




在上一期的《『译』研报:低延迟趋势线与交易择时》文章里,LLT 均线切线买入策略的回测结果好到难以置信。我知道你们爱看这样的文章,但很少人有提出置疑,这样的回测结果,有几分可信度?
借这个机会,讨论一下策略回测中的几个关键问题。这篇文章将揭示导致『回测买地球、实盘亏成狗』的深层技术原因: 它深藏在你使用的回测框架里,如果你不用显微镜来查看每一个细节,你可能完全意识不到哪哪儿错了。
这也是为什么做量化可能会盈利的根本原因:这世界就是一个草台班子,没有多少人在努力在认真。如果你能高效地做好每一个细节,你就能战胜任何人。
声明:本文发布的目的是为了分享如何解决将研报策略实现为代码的技术问题,请勿以此作为投资决策
未来数据
在我们昨天的研报复现中,实际上是有一点使用未来数据的嫌疑的。问题出在下面的代码中:
df = df.copy()
df['slope'] = (df[factor_col].rolling(slope_window)
.apply(lambda x: np.polyfit(np.arange(slope_window), x, 1)[0]))
df['signal'] = 0
df.loc[df['slope'] > 0, 'signal'] = 1
df.loc[df['slope'] < 0, 'signal'] = -1
# 计算每日收益率
df['benchmark'] = df['close'].pct_change()
# 计算多空组合收益
df['long_return'] = np.where(df['signal'] == 1, df['benchmark'], 0)
df['short_return'] = np.where(df['signal'] == -1, -df['benchmark'], 0)
# 组合收益 = 多头收益 * 多头权重 + 空头收益 * 空头权重
df['strategy'] = df['long_return'] * long_weight + df['short_return'] * short_weight
return df
如果把signal看成因子,那么这段代码里,因子与远期回报是按时间对齐的,而不是错位对齐的。即,代码把 T 0 T_0 T0日的收益归因为 T 0 T_0 T0日的因子。而 T 0 T_0 T0日收益的确切含义是,你要在 T − 1 T_{-1} T−1日买入,在 T 0 T_0 T0日卖出,才能计算出来。这当然是错误的。
如果今天股价上涨,那么均线的切线就可能方向向上,从而 signal = 1;如果今天股价下跌,均线切线就有可能方向向下,从而 signal = -1。这两种情况都被不合理的计入了组合收益。

这句话虽然没有包含实现细节,但本质上也是包含了未来数据的,不过它的副作用会小一点:它只是要求在收盘后,根据收盘价计算出来趋势线切线斜率和信号后,再以收盘价买入。
尽管这也有一点点未来数据的含义,但在实践中是允许的,因为理论上你可以赶在尾盘集合竞价时计算信号并买入:这样你计算信号时使用的价格,与最终的收盘价相差并不大,很可能就是一个滑点的价格。在一些回测工具中,也是允许这样做的。比如,backtrader 就允许以当天收盘价买入,只要你声明允许 COC(Cheat on Close)。
修正算法
现在,我们来修正上述代码的错误,我们先考虑能否连带研报中的Cheat on Close这个小小的瑕疵也规避了?

与上一版相比,重要的区别有两点:
- 我们将信号后移了一行(而不是向前!)。这样在计算仓位时,如果前一天信号为 1,我们就用这个 1 来乘以当天的涨跌幅。
- 我们允许指定计算收益的价格数据列,默认为 open
如果你熟悉 Alphalens 的话,就会知道它在计算收益时,是以信号发出之后,第二天的开盘价买入,第三天的开盘价卖出来计算 period = 1D 时的收益的。现在,看起来我们正是这样做的!
下图显示了最初几次交易的完整过程(使用合成数据,涨跌固定为 5%,-5%交替):

在 1 月 2 日,策略发出做多信号,于是,我们在 1 月 3 日开盘时多方买入,价格是 104.73,当日涨幅 5%,把 shift 之后的信号 1 作为仓位,最终多空组合收益计为 2.5%(按多、空各可用 50%仓位)。1 月 3 日的信号也为 1,所以持仓中;但当天跌 5%,所以组合收益为-2.5%;4 号的信号为 0,策略需要在 5 日开盘卖出;5 号当天由于不持仓,所以组合的收益为 0。
当使用 open 作为计算收益的价格列之后,我们仍然会得到与之前几乎一样的累积收益图。这次结果可信吗?
看上去都是对的,很完美。除了这一点:在基于 dataframe 的向量化回测框架中,我们不能使用按次日开盘价买入的策略。以1月2日的买入信号为例,由于1月2日的买入信号(1)被移位到了1月3日,算成了多方仓位,所以这会导致把1月3日开盘价对1月2日开盘价的涨幅算成多方收益。而1月2日开盘时,我们还没有实现多方买入呢。
考虑到如果 T 0 T_0 T0日以上涨收盘,就更容易发出做多信号,并且次日开盘价也很有可能高于前一日开盘价,所以,这样计算出来的策略收益,会在第一天有较大的作弊成份,这是导致在使用开盘价计算收益时,回测结果很好看的主要原因。
但我们又不能在信号发出后的第三天以开盘价买入(信号不等人!),所以,我们必须使用 Cheat on Close 的策略,也就是价格列必须指定为"close"。
在指定价格列为 close 时,如果记信号发生日为 T 0 T_0 T0,信号为 1,由于移位的原因,我们在计算 T 1 T_1 T1日的组合收益将是 1 * T 1 T_1 T1日收益, T 1 T_1 T1日的收益是 T 1 T_1 T1日的收盘价与 T 0 T_0 T0日的收盘价计算得来的。尽管这是一种 Cheat on Close,但并不会引起太大的误差。
我们使用 DataFrame来进行回测的主要原因是简单快捷。从一个想法到最终实盘,需要经过无数道工序,几个月的时间(以日频计,算上仿真),所以,没有必要一开始就使用更重的框架。如果一个想法在简单测试中就不工作,我们大概率应该放弃它 – 因为从统计上讲,多数想法本身就是无效的。
backtrader: 慢一点,但是更可靠
对事件型策略的回测,backtrader尽管会慢一点,但是在结果上会更可靠一些,表现在:
- backtrader默认会在信号发出之后的下一个bar以开盘价买入。
- backtrader会计算手续费、仓位限制和成交量限制。
- 基于DataFrame的向量式回测因为很简单,所以没有一个标准的库来实现。我们自己的手工实现比较容易引入错误。
我们就用backtrader来验证一下之前的回测结果。
计算LLT和切线斜率的代码在前一期提供了,这里不再重复。

这是回测策略类:
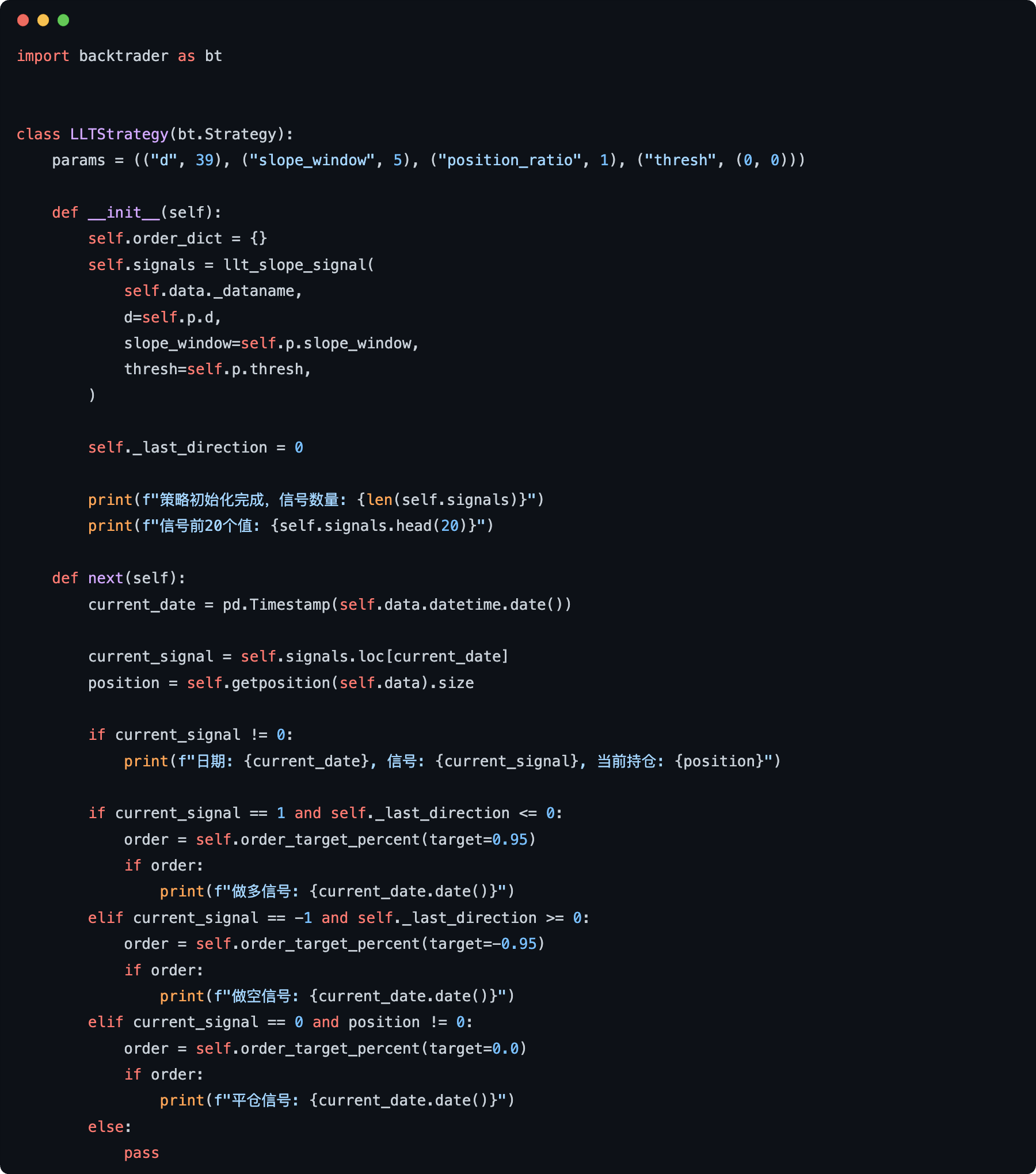
我们省略回测调用代码,以节省篇幅。如果你需要这些代码,可以购买匡醍会员。如果你不太理解我们在讨论些啥,你应该报名匡醍的《量化24课》和《因子挖掘与机器学习策略》。
我们得到的结果是,年化收益11.8%,夏普0.4。会比基准略好一点。但是,如果我们对2013年之后的区间进行回测,会发现我们其实只是捡回来一条咬人的毒蛇:

这次的年化是-6.4%,最大回撤79%。
backtrader参数优化
我们应该对此失望吗?
不!我们从来就不应该指望一个简单的策略,甚至只有不到 100 行代码,就能成为一台印钞机。繁复深奥并不必然成功,但在资本市场上,简单甚至简陋肯定是不行的。任何赚钱的生意,都必须有壁垒。
所以,我们的优化之路刚刚开始。远远不到应该失望的时候!
首先,千分之一的手续费太高了。当我们在指数上回测时,一定要记住指数本身就没有太大的盈利空间,任何跑冒滴漏都不能允许!
现在,多数券商的交易手续费,特别是量化交易的,已经低到万分之 0.854 了。所以,我们完全没必要设置千分之一这么高的手续费。

在仔细分析之后,我们发现信号翻转过于频繁。当切线斜率从-0.01 变化为 0.005 时,我们就要从空单马上变为多单?这显然不合理,我们应该过滤掉这种虚假的信号。切线斜率的计算本身,也受到 alpha 的影响。我们之前的回测中,使用的是 0.05,它会是最优的吗?
我们决定使用 backtrader 自带的参数优化方案来帮我们调优。但是,调优可能出现过拟合,所以,我们最后还要分享如何判断调优的结果没有过拟合。
我们先来定义优化函数。
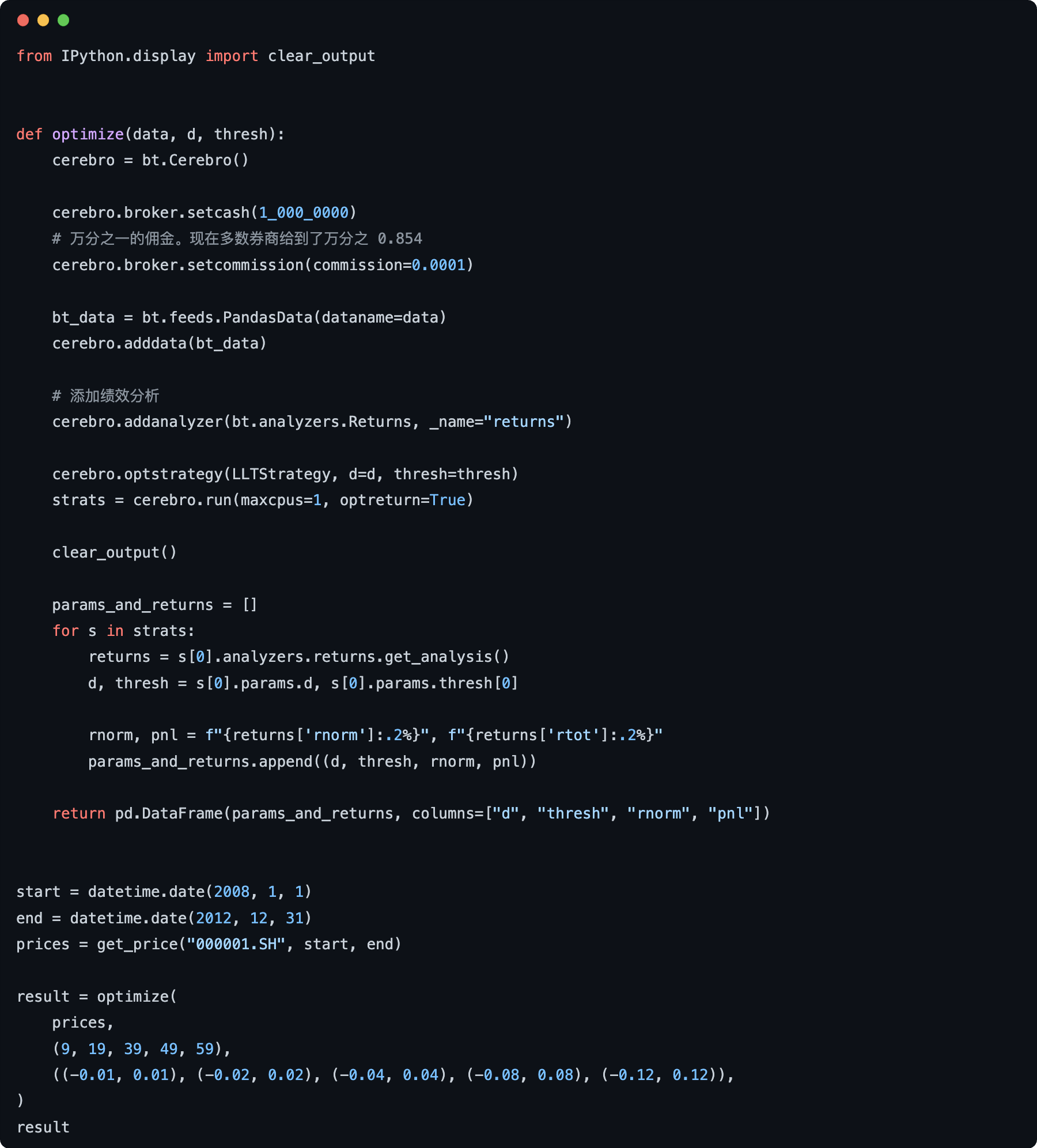
通过backtrader来进行参数优化,关键是这样两行代码:
cerebro.optstrategy(LLTStrategy, d = d, thresh = thresh)
strats = cerebro.run(maxcpus = 1, optreturn = True)
在 notebook 中运行时,我们必须设置maxcpus = 1。如果maccpus > 1,将会启动多进程优化。此时涉及到notebook中代码的持久化(因为要把代码传送到新的进程中),就会出错。
我们让参数 d 在 (9, 19, 39, 49, 59, 69),之间取值,这样对应的alpha会是(0.2, 0.1, 0.05, 0.03),而thresh则在(-0.01, 0.01)到(-0.12, 0.12)之间,以倍增的方式来取值。
从参数优化结果来看,d = 59, thresh = -0.01 是最好的一组,达到了年化26.6%的超高收益率。总体来看,随着 d 值增加,收益变好;thresh的影响并不大。另外,还有一个对性能有影响的参数,即计算切线斜率时,使用多少个 bar? 这里只使用了固定的 5。
刚刚的参数优化是基于2008年到2012年的数据得到的。它在2005年到2013年间的情况怎么样?结论是:年化收益率达到了25.6%。
如果我们把这个参数用于2013年到2014年的投资,那么,将会得到13.9%的年化和0.97的夏普率。这个成绩应该说相当不错。
正确看待过拟合
当我们使用backtrader来进行参数优化时,一定要注意会比较容易出现过拟合。
在上一节,我们已经把基于[2008,2012]得到的最优参数,运用于过去[2005, 2012]和未来[2013,2014],来对比观察结果。这是检验过拟合是否存在的一种方法。如果参数没有过拟合,那么它就应该在它没有见过的数据上,也能讲出好的故事出来。
这里还介绍另外一个思路。关于thresh参数的。基于 thresh 来决定 signal,显然要比简单地基于 0 来判断 signal 合理,这一点无庸置疑。但优化的thresh参数会不会导致过拟合?这时候我们可以观察下切线斜率的分布:
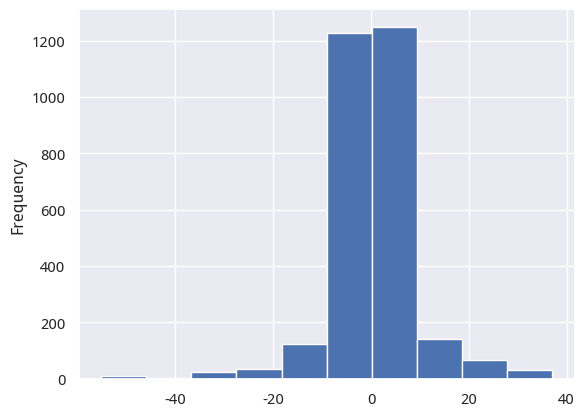 切线斜率分布
切线斜率分布
可以看出,通过设置 thresh 为 [-0.02, 0.02],我们只排除了 0.3%左右的数据。这说明:我们并没有通过 hacking 的手段,排除大多数情形,只留下让最终收益好看的少量数据。因此,至少在thresh参数上,很有可能这里并没有发生过拟合。
如果我们通过[2008, 2012]年的数据优化出来的参数 d = 59, thresh = [-0.01, 0.01] 用在2013年到2024年不变的话,那么年化收益率会衰减到2.79%。这说明,市场风格其实是一直在变化的。这个策略也只是一个
β
\beta
β因子。
不过,我们可以每隔几年就更新一次参数,再在接下来的一小段时间内,使用这个策略。
下面的代码演示了如何基于过去5年的数据搜索出优化参数,然后用在随后两年的投资中:

最终,我们得到历年(两年)的收益如下:

如果缩短验证时间(比如在参数优化之后,将策略运行时间由两年改短为1.5年),则在2023到2025年,此策略仍然带来了不错收益。大家可以自己改参数运行下。
本文notebook源码可在微信公众号 上获得。


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











