




Unet系类算法为什么在医疗图像处理上取得这么好的效果?很大一部分原因是由于医疗图像自身的特性所决定的,首先是医疗图像结构固定且简单、其次Unet网络结构简单与难获取的医疗图像匹配度较高。导致的问题就是深度学习强大的特征表示能力并不能很好的发挥其作用,最后就是数据集获取难度很大。一般人获取不到,就算获取到大量的医疗图像数据,对其进行标注真的是一件特别无聊的工作。专业的事交给专业的人去做比较好,现实生活中可能会存在以下几个问题,搞CV的人对医疗图像进行标注有困难,正常不正常傻傻分不清。医生对CV可能也比较陌生,不是针对所有人,针对大部分人而言来说,情况就是这么个情况。
1.Unet
U-Net: Convolutional Networks for Biomedical Image Segmentation
code
paper
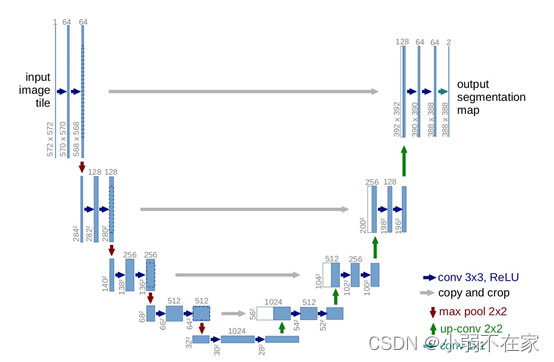
从Unet网络结构图可知,该网络结构是一个编码解码结构,编码由卷积、池化组成,也可理解为下采样操作。目的是为了获取不同尺寸的feature map。解码器由卷积、特征拼接、上采样组成,其中特征拼接是feature map维度上的拼接,其目的是为了获取更厚的feature map,因编码阶段卷积池化过程会使图像的细节信息丢失,feature map进行拼接是为了尽可能的找回编码阶段所丢失的图像细节信息。拼接这一操作虽然可以避免图像信息的缺失,但这一操作能找回丢失信息的多少?拼接的方式到底好还是不好?是一个值得考虑的问题。Unet网络已然成为当前医疗图像分割的baseline,主要是因为医疗图像本身自带的一些数据特性所决定的。大多医疗图像数据的特点有以下几点:首先是医疗图像语义相比较自然场景其语义较为简单且结构固定,导致其所有的feature都很重要,也即是说低级、高级的语义信息都尽量保存下来,以便模型能更好的对其进行学习。其次是医疗数据获取难度大,能获取的数据量过少,导致的问题是网络过深与数据量少这一矛盾。会出现过拟合现象。最后是Unet相比较于其他的分割模型,其结构简单,具有更大的操作空间。
后续的改进工作大多围绕特征提取、特征拼接展开
torch实现如下
import torch
import torch.nn as nn
import torch.nn.functional as F
class double_conv2d_bn(nn.Module):
def__init__(self,in_channels,out_channels,kernel_size=3,strides=1,padding=1):
super(double_conv2d_bn,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,
kernel_size=kernel_size,
stride = strides,padding=padding,bias=True)
self.conv2 = nn.Conv2d(out_channels,out_channels,
kernel_size = kernel_size,
stride = strides,padding=padding,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class deconv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=2,strides=2):
super(deconv2d_bn,self).__init__()
self.conv1 = nn.ConvTranspose2d(in_channels,out_channels,
kernel_size = kernel_size,
stride = strides,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
return out
class Unet(nn.Module):
def __init__(self):
super(Unet,self).__init__()
self.layer1_conv = double_conv2d_bn(1,8)
self.layer2_conv = double_conv2d_bn(8,16)
self.layer3_conv = double_conv2d_bn(16,32)
self.layer4_conv = double_conv2d_bn(32,64)
self.layer5_conv = double_conv2d_bn(64,128)
self.layer6_conv = double_conv2d_bn(128,64)
self.layer7_conv = double_conv2d_bn(64, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











