







大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本笔记介绍深度学习中常见的归一化。

热门专栏
机器学习
深度学习
文章目录
各种优化的归一化介绍(本质上进行标准化)
下面的归一化。本质上进行的是标准化。
普通归一化(例如 BN、LN等)通常放在全连接层或卷积层之后,并在激活函数之前。
权重归一化与普通的归一化不同,它是直接应用于层的权重参数,因此它通常在层的定义阶段就应用。例如,在卷积层或全连接层的权重初始化或定义时。
普通归一化过程
归一化方法的统一步骤如下:
1. 确定归一化范围
- 批归一化(Batch Normalization)
- 层归一化(Layer Normalization)
- 实例归一化(Instance Normalization)
- 组归一化(Group Normalization)
2. 计算均值和方差
- 对归一化范围内的元素计算均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2。
- 公式如下:
μ = 1 N ∑ i = 1 N x i \mu = \frac{1}{N} \sum_{i=1}^{N} x_i μ=N1i=1∑Nxi
σ 2 = 1 N ∑ i = 1 N ( x i − μ ) 2 \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 σ2=N1i=1∑N(xi−μ)2- 其中 N N N 是归一化范围内的元素总数。
3. 标准化
- 将输入值进行标准化,使其具有均值 0 和方差 1:
x ^ i = x i − μ σ 2 + ϵ \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} x^i=σ2+ϵxi−μ- ϵ \epsilon ϵ 是一个小常数,用于避免分母为零。
4. 缩放和平移
- 为了让模型在归一化后仍能保持灵活性,引入可学习的缩放参数
γ
\gamma
γ 和平移参数
β
\beta
β:
y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β- 通过学习 γ \gamma γ 和 β \beta β,模型可以调整归一化后的输出尺度和偏移,使其更加适应模型的需求。
普通归一化分类
1. 批归一化(Batch Normalization, BN)
原理
对一个批量中的样本的同一通道进行归一化。它将每个神经元的输出值转换为均值为0、方差为1的分布,随后再进行缩放和平移。批归一化的公式如:
x
^
=
x
−
μ
batch
σ
batch
2
+
ϵ
\hat{x}=\frac{x-\mu_{\text{batch}}}{\sqrt{\sigma_{\text{batch}}^{2}+\epsilon}}
x^=σbatch2+ϵx−μbatch
其中
μ
batch
\mu_{\text{batch}}
μbatch 和
σ
batch
\sigma_{\text{batch}}
σbatch 是当前批次中的均值和方差,
ϵ
\epsilon
ϵ 是一个小常数,防止除零错误。
优点
- 减少了内部协变量偏移问题,使得模型更稳定。
- 加速收敛,允许使用更高的学习率。
- 有轻微的正则化效果,因为批次间的随机性类似于dropout的效果。
缺点
- 对小批量数据敏感。当批次较小时,均值和方差估计不准,导致效果下降。
- 在某些情况下(如RNN、Transformer中的序列任务),批次归一化的效果不如其他归一化方法。
- 训练和推理时行为不同:推理时使用全局的均值和方差,因此需要额外的记录和计算。
使用场景
- 适用于大多数卷积神经网络(CNN)和全连接网络(MLP),如图像分类、物体检测等任务中。
- 不太适合处理序列任务,如RNN和LSTM。
2. 层归一化(Layer Normalization, LN)
原理
对单个样本的所有通道进行归一化,不依赖批量。
- 公式类似于批归一化,但均值和方差是基于整个层(而不是批次)计算的。
x ^ = x − μ layer σ layer 2 + ϵ \hat{x}=\frac{x-\mu_{\text{layer}}}{\sqrt{\sigma_{\text{layer}}^{2}+\epsilon}} x^=σlayer2+ϵx−μlayer- 其中 μ layer \mu_{\text{layer}} μlayer和 σ layer \sigma_{\text{layer}} σlayer是当前层中的均值和方差。
优点
- 对小批次数据敏感性较低,不依赖于批次大小。
- 在处理序列数据(如RNN、Transformer)时效果更好,因为它不依赖于批次中的样本数。
缺点
- 相比批归一化,计算量稍大。
- 由于没有利用批次之间的信息,收敛速度可能稍慢。
使用场景
- 适用于序列任务,如RNN、LSTM、Transformer模型等,尤其在自然语言处理和时间序列任务中广泛使用。
3. 实例归一化(Instance Normalization, IN)
原理
对单张图像的每个通道分别独立进行归一化,不依赖批量。
- 公式类似于批归一化,但归一化的维度是单个样本的每个通道:
x ^ c = x c − μ instance σ instance 2 + ϵ \hat{x}_{c}=\frac{x_{c}-\mu_{\text{instance}}}{\sqrt{\sigma_{\text{instance}}^{2}+\epsilon}} x^c=σinstance2+ϵxc−μinstance
优点
- 适合风格迁移、图像生成等任务,因为在这些任务中,局部统计量(如样本和通道内的均值和方差)比批次统计量更重要。
- 对风格变化的敏感度更高。
缺点
- 不适合大多数分类任务,因为它只考虑样本的单个通道,不利用全局信息。
使用场景
- 广泛用于图像生成任务中,如GAN和风格迁移(Style Transfer)等。
- 在卷积神经网络中常见于图像处理任务。
4. 组归一化(Group Normalization, GN)
原理
组归一化是介于批归一化和层归一化之间的一种方法。它将单个样本的特征通道分为若干组,并在每组内进行归一化操作。这种方法避免了批归一化对批次大小的依赖,同时利用了更多的局部信息。
- 公式与批归一化类似,但均值和方差是在每组特征通道内计算的:
x ^ g = x g − μ group σ group 2 + ϵ \hat{x}_{g}=\frac{x_{g}-\mu_{\text{group}}}{\sqrt{\sigma_{\text{group}}^{2}+\epsilon}} x^g=σgroup2+ϵxg−μgroup - 其中 μ group \mu_{\text{group}} μgroup 和 σ group \sigma_{\text{group}} σgroup 是当前组内的均值和方差。
优点
- 对小批次训练效果良好,不依赖于批次大小。
- 比层归一化更有效,特别是在卷积神经网络中,能很好地利用局部特征。
缺点
- 对卷积核的大小和特征通道数敏感,不如批归一化适用于大批次训练任务。
使用场景
- 适用于卷积神经网络(CNN)中的图像分类任务,特别是小批次训练场景。
- 当批归一化效果不佳或批次较小时(如语义分割、目标检测等任务)表现优越。
权重归一化(Weight Normalization, WN)
原理
权重归一化是对神经网络中的权重进行归一化,而不是激活值(准备通过激活函数(如 ReLU、Sigmoid、Tanh 等)的值)。它通过对每个神经元的权重向量进行重新参数化,将权重向量的方向与其长度分离开。
权重归一化主要针对模型的权重参数,确保训练中权重更新稳定。
批/层/实例/组归一化主要针对层的激活值,确保每层输出的稳定分布,从而提高训练的速度和稳定性。
权重归一化的步骤
权重归一化的过程可以分为以下几个步骤:
1.重参数化权重:
- 将每个权重向量重参数化为方向向量和长度标量的乘积。
- 具体表示为:
w = v ∥ v ∥ ⋅ g w=\frac{v}{\|v\|} \cdot g w=∥v∥v⋅g - 其中:
- v v v 是原始权重向量(可学习参数),
- ∥ v ∥ \|v\| ∥v∥ 是权重向量的范数(即它的长度),
- g g g 是可学习的标量(称为“尺度参数”),
- w w w 是归一化后的权重向量。
- 通过这种重参数化,权重向量 w \mathbf{w} w的方向被标准化为单位长度(归一化),而 g 控制权重的尺度。
2.计算范数:
- 计算权重向量的 L2 范数:
∥ v ∥ = ∑ i v i 2 \|v\|=\sqrt{\sum_{i} v_{i}^{2}} ∥v∥=i∑vi2 - 该范数用于对权重向量进行标准化,使得其长度等于 1。
3.标准化权重:
- 使用计算出的范数将权重向量标准化,得到单位长度的方向向量:
v ^ = v ∥ v ∥ \hat{v}=\frac{v}{\|v\|} v^=∥v∥v - 这个标准化的方向向量 v ^ \hat{\mathbf{v}} v^仅包含方向信息,而没有尺度信息。
4.应用缩放:
- 使用可学习的尺度参数 g 来调整权重的实际尺度,使得网络能够灵活调整权重的大小:
W = v ^ ⋅ g W = \hat{v} \cdot g W=v^⋅g - 通过引入这个缩放参数 g ,模型可以学习适当的权重大小,以适应不同的训练和优化需求。
- 权重更新:
- 在反向传播时,优化器会更新原始权重 v \mathbf{v} v和缩放参数 g 的值,而不是直接更新标准化后的权重 w \mathbf{w} w。这种重参数化不会改变优化问题,但可以提高训练的稳定性。
权重归一化的作用
- 提高收敛速度:权重归一化通过标准化权重的长度,使得不同层的权重尺度在训练中保持一致,减轻了梯度爆炸或消失的问题,从而加速训练收敛。
- 更稳定的训练过程:权重归一化减少了权重值的剧烈变化,使优化过程更加平滑和稳定。
- 增强模型的可解释性:通过将权重分解为方向和尺度两个部分,模型的行为更容易解释,因为方向向量决定了特征的方向,而缩放参数决定了特征的重要性。
优点
- 可以加速收敛,并提高模型的稳定性。
- 在一定程度上减少了对批次大小的依赖。
缺点
- 相较于批归一化,效果并不总是显著。
使用场景
- 适用于卷积神经网络和全连接网络,尤其在需要加速训练时。
- 在一些生成模型中(如GAN)也有应用。
归一化方法对比总结
以下是归一化方法对比总结,其中加入了每种归一化方法的原理:
| 归一化方法 | 原理 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 批归一化(BN) | 对一个批量中的所有样本的同一通道进行归一化,基于批次的均值和方差调整 | 卷积网络、全连接网络 | 加快收敛,正则化,适应大批量训练 | 对小批次敏感,序列任务效果差 |
| 层归一化(LN) | 对单个样本的所有通道进行归一化,不依赖批量,计算层内均值和方差 | RNN、Transformer、序列任务 | 适应小批次训练,不依赖批次大小 | 计算量较大,收敛可能稍慢 |
| 实例归一化(IN) | 对单张图像的每个通道分别独立进行归一化,计算每个样本的通道内均值和方差 | 图像生成、风格迁移 | 对风格敏感,适用于生成任务 | 不适合分类任务,无法捕捉全局信息 |
| 组归一化(GN) | 将单个样本的特征通道分组,对每一组进行归一化,计算组内均值和方差 | 小批次训练,卷积网络 | 适合小批次,不依赖批次大小 | 对卷积核大小和通道数较敏感 |
| 权重归一化(WN) | 对神经元的权重向量进行归一化,将方向和长度分开重新参数化 | 卷积网络、全连接网络、生成模型 | 加速收敛,提高稳定性 | 效果不一定显著,某些任务中不如BN |
注意,虽然他们是叫做归一化(批归一化、层归一化、实例归一化),是将多个输入特征归一化为均值为 0、方差为 1 的分布,使得网络的各层输入保持在较为稳定的范围内。本质上是进行标准化。再进行引入两个可学习参数 γ 和 𝛽,分别表示缩放和平移操作。
BN、LN、IN、GN 等归一化方法都包含了标准化的步骤,即它们都会将激活值调整为均值为 0、方差为 1 的分布,关键区别在于这些方法在不同的范围内计算均值和方差,以适应不同的训练场景和模型结构:

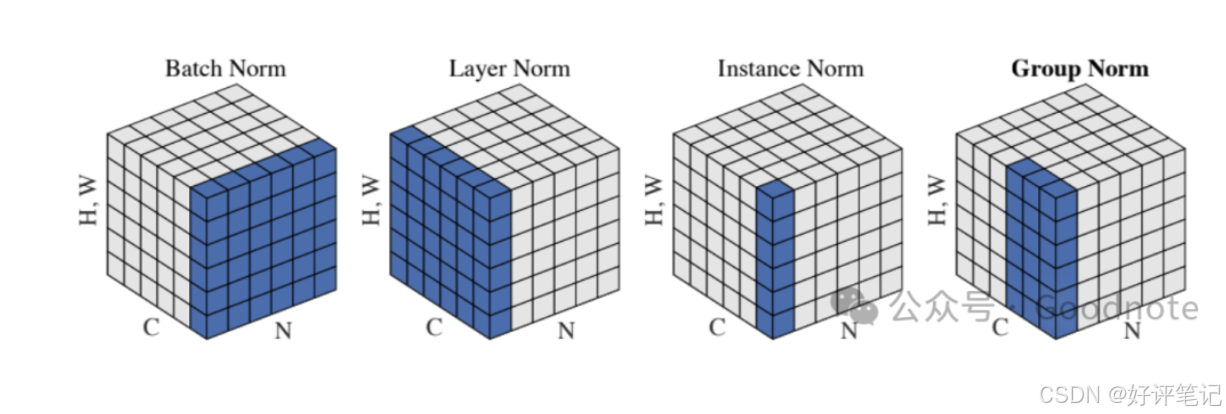
- Batch Normalization (BN):对一个批量中的所有样本的同一通道进行归一化。
- Layer Normalization (LN):对单个样本的所有通道进行归一化,不依赖批量。
- Instance Normalization (IN):对单张图像的每个通道分别独立进行归一化,不依赖批量。
- Group Normalization (GN):对单张图像的多个通道进行归一化,不依赖批量。


















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









