






摘要
任务名为伪装物体检测(COD),目的是识别那些与其周围环境“无缝”融合的物体。由于目标物体与背景之间高度的内在相似性,使得COD任务比传统的物体检测任务更具挑战性。
精心收集并构建了一个新的数据集COD10K,包含10,000张图像,涵盖超过78个物体类别的伪装物体,这些图像密集地标注了类别、边界框、物体/实例级别和抠图级别的标签。COD10K数据集能够推动多种视觉任务的发展,例如定位、分割和Alpha抠图等。
开发了一个简单但有效的框架,称为搜索识别网络(SINet),在所有测试的数据集上超越了各种最新的物体检测基线。
介绍

-
背景描述:引言部分首先从生物学和生态学的角度介绍伪装现象,指出目标物体与背景高度相似,这种“背景匹配”伪装的生物策略让目标难以被观察者识别。这不仅体现了伪装检测的挑战性,还引出了该任务的科学和应用价值。
-
挑战性:伪装物体检测与传统的显著物体检测和通用物体检测的区别在于,它需要识别那些与环境高度融合的物体。这对算法提出了更高的要求,不仅需要识别出物体,还要能够在复杂的背景下找到它们的边界。
-
多样化的应用场景:COD的应用不仅限于生物学和科学研究,在计算机视觉、医疗、农业和艺术等多个领域都有重要应用。这样的描述突出了COD研究的广泛实用性,为后续的研究动机提供了支持。
-
研究意义:提出的SINet框架设计简单高效,其训练时间仅为约1小时,同时在多个数据集上均取得了最优性能,这种高效性和优越性增强了SINet作为COD任务潜在解决方案的可行性。SINet的出现标志着在伪装检测领域设立了首个完整的基准,推动了深度学习在该任务中的应用。此外,SINet的设计为对象检测任务提供了一种新的视角,即从伪装角度出发,提高了检测算法应对复杂背景的能力。
数据集COD
1. 数据集概述
COD10K数据集是为伪装物体检测(COD)任务特别设计的,包含了10,000张高质量图像,覆盖了自然场景中常见的伪装对象。该数据集在内容上分为10个大类(例如水生、飞行、两栖和陆生物体)和78个子类,如鱼类、昆虫、鸟类等。每张图像都密集标注了物体类别、边界框、对象级、实例级和Alpha-Matting级别的标签。
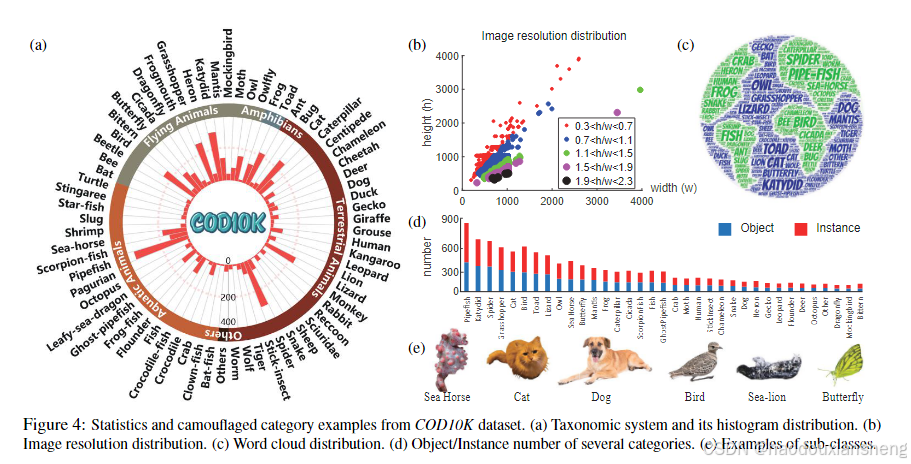
2. 标注细节
COD10K的标注系统具有层次性和多样性,以支持不同层次的视觉任务:
- 类别标注:每张图像都标注了所属的大类和子类,为不同类型的物体提供了明确的分类。
- 边界框:在每个图像中标注出伪装物体的边界框,支持物体定位任务。
- 对象级标注:对每个物体进行精细标注,以帮助模型识别物体的整体轮廓。
- 实例级标注:进一步细分物体的实例级标签,类似COCO数据集的标注方式,这对于场景理解和对象编辑具有重要意义。
- Alpha-Matting:为部分图像提供了Alpha-Matting标注,准确标注出物体的边界细节,通常需要耗费60分钟完成一张图像的标注。
3. 挑战性属性
COD10K数据集中的图像还配备了多种挑战性属性标注,这些属性常见于自然伪装场景,包括:
- 多对象(Multiple Objects):图像中含有两个或以上的伪装物体。
- 大物体(Big Object) 和 小物体(Small Object):物体的面积与图像面积的比例分别达到一定阈值,代表物体大小的不同。
- 视野外(Out-of-View):物体被图像边界截断,部分位于视野之外。
- 遮挡(Occlusion):物体被其他物体部分遮挡,增加了检测难度。
- 复杂形状(Shape Complexity):物体具有复杂或细长的部分,增加了模型检测边界的难度。
- 不确定边界(Indefinable Boundaries):物体与背景颜色相似,使得其边界难以辨别。
4. 数据集的分布特征
- 对象大小:COD10K中的物体大小范围从0.01%到80.74%,提供了广泛的尺度变化,有助于评估模型在不同尺度下的检测性能。
- 全局/局部对比度:通过全局和局部对比度评估物体的可检测性,COD10K中物体的对比度较低,增加了检测难度。
- 中心偏置:COD10K数据集减少了中心偏置,使物体在图像中的位置更加多样化,增加了检测的泛化能力。
- 分辨率:该数据集包含大量1080p的高清图像,确保模型在训练和测试中可以获取到精细的边界信息。
- 训练/测试划分:COD10K数据集被分为6,000张训练图像和4,000张测试图像,以保证充足的数据量用于深度学习模型的训练和评估。
方法
在该论文中,作者提出了一个名为SINet的框架,用于伪装物体检测(COD)。该框架模拟了生物在捕猎过程中对伪装物体的搜索与识别过程,包含了两个主要模块:搜索模块(Search Module, SM)和识别模块(Identification Module, IM)。此外,该框架还引入了几个关键组件:感受野(Receptive Field, RF)模块、部分解码器组件(Partial Decoder Component, PDC)、以及搜索注意力(Search Attention, SA)模块。这些组件的组合帮助模型在具有高度相似背景的图像中准确定位和分割伪装物体。
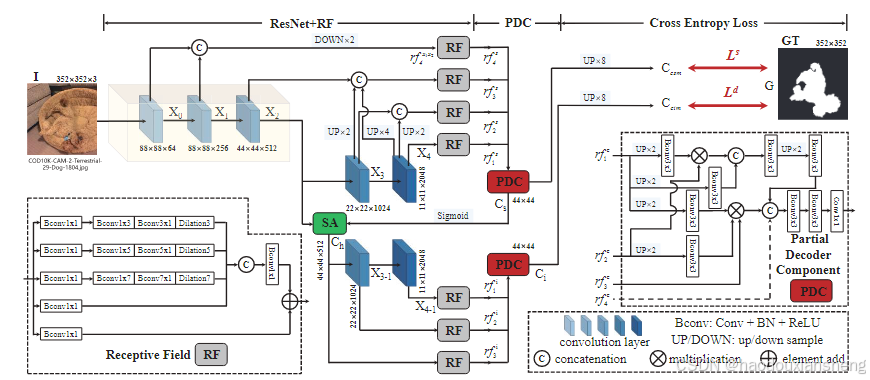
1. 搜索模块(Search Module, SM)
搜索模块的设计灵感来自神经科学研究中的人类视觉系统。在人类视觉系统中,不同大小的感受野(Receptive Fields, RF)会突出靠近视网膜中心的区域,以更好地处理空间上的微小位移。因此,搜索模块利用不同分辨率的特征图来高效地搜索可能存在伪装物体的区域。
具体而言,对于输入图像 I ∈ R W × H × 3 I \in \mathbb{R}^{W \times H \times 3} I∈RW×H×3,从ResNet-50中提取了一组特征 { X k } k = 0 4 \{X_k\}_{k=0}^4 {Xk}k=04。为了保留更多的空间信息,第二层的步长被设置为1,从而保持较高的分辨率。然后,将这些特征按层次划分为低层特征 { X 0 , X 1 } \{X_0, X_1\} {X0,X1}、中层特征 X 2 X_2 X2、和高层特征 { X 3 , X 4 } \{X_3, X_4\} {X3,X4},并通过串联、上采样和下采样操作进行融合。这种多层次特征组合为后续的精确识别提供了强大的特征基础。
2. 识别模块(Identification Module, IM)
识别模块负责对搜索模块提供的候选特征进行精细检测,以确保准确定位伪装物体。在识别模块中,作者扩展了部分解码器组件(PDC)来融合多层次的特征,从而生成粗略的伪装物体图。
具体来说,粗略的伪装物体图
C
s
C_s
Cs 的计算公式为:
C
s
=
PD
s
(
r
f
1
s
,
r
f
2
s
,
r
f
3
s
,
r
f
4
s
)
C_s = \text{PD}_s(rf^s_1, rf^s_2, rf^s_3, rf^s_4)
Cs=PDs(rf1s,rf2s,rf3s,rf4s)
其中
{
r
f
k
s
=
r
f
k
,
k
=
1
,
2
,
3
,
4
}
\{rf^s_k = rf_k, k = 1, 2, 3, 4\}
{rfks=rfk,k=1,2,3,4} 表示在搜索模块中增强后的特征。识别模块进一步利用搜索注意力模块(SA)来提升中层特征的分辨能力,最终生成增强的伪装图
C
h
C_h
Ch:
C h = f max ( g ( X 2 , σ , λ ) , C s ) C_h = f_{\text{max}}(g(X_2, \sigma, \lambda), C_s) Ch=fmax(g(X2,σ,λ),Cs)
最终,高层特征进一步通过部分解码器组件聚合,生成最终的伪装图 C i C_i Ci:
C i = PD i ( r f 1 i , r f 2 i , r f 3 i ) C_i = \text{PD}_i(rf^i_1, rf^i_2, rf^i_3) Ci=PDi(rf1i,rf2i,rf3i)
3. 感受野(Receptive Field, RF)模块
RF模块旨在模拟人类视觉中的感受野,通过多个分支来捕捉不同尺度的信息。RF模块包含五个分支,每个分支的第一个卷积层(Bconv)尺寸为 1 × 1 1 \times 1 1×1,以减少通道数。然后,通过 ( 2 k − 1 ) × ( 2 k − 1 ) (2k-1) \times (2k-1) (2k−1)×(2k−1) 的Bconv层和一个具有特定扩张率的 3 × 3 3 \times 3 3×3 Bconv层来进一步处理特征。
4. 部分解码器组件(Partial Decoder Component, PDC)
PDC的设计是为了有效地整合来自不同层次的特征。通过在不同特征之间进行上下采样和相乘操作,PDC可以有效地减少特征间的差距,并确保浅层和深层特征的一致性。
PDC中的特征更新公式如下:
r f k c 2 = r f k c 1 ⊗ ∏ j = k + 1 M Bconv ( UP ( f j c 1 ) ) rf^{c2}_k = rf^{c1}_k \otimes \prod_{j=k+1}^{M} \text{Bconv}(\text{UP}(f^{c1}_j)) rfkc2=rfkc1⊗j=k+1∏MBconv(UP(fjc1))
其中, UP ( ⋅ ) \text{UP}(\cdot) UP(⋅) 是上采样操作, Bconv ( ⋅ ) \text{Bconv}(\cdot) Bconv(⋅) 是一个 3 × 3 3 \times 3 3×3 卷积、批归一化和ReLU的序列操作。
5. 搜索注意力(Search Attention, SA)模块
SA模块主要用于消除中层特征中的干扰特征,通过应用一个高斯滤波来增强目标区域的分辨能力。
SA模块的公式如下:
C h = f max ( g ( X 2 , σ , λ ) , C s ) C_h = f_{\text{max}}(g(X_2, \sigma, \lambda), C_s) Ch=fmax(g(X2,σ,λ),Cs)
其中, g ( ⋅ ) g(\cdot) g(⋅) 是一个标准差为 σ = 32 \sigma = 32 σ=32 的高斯滤波器,核大小为 λ = 4 \lambda = 4 λ=4。
6. 损失函数
在SINet的训练过程中,采用了交叉熵损失函数来优化伪装物体的检测精度。为了生成最终的伪装物体检测图,作者定义了两个不同阶段的伪装物体图:粗略的伪装图 C c s m C_{csm} Ccsm 和增强的伪装图 C c i m C_{cim} Ccim。损失函数包含了这两个伪装图的交叉熵损失。
总的损失函数 L L L 定义如下:
L = L C E ( C c s m , G ) + L C E ( C c i m , G ) L = L_{CE}(C_{csm}, G) + L_{CE}(C_{cim}, G) L=LCE(Ccsm,G)+LCE(Ccim,G)
其中, L C E L_{CE} LCE 表示交叉熵损失, C c s m C_{csm} Ccsm 和 C c i m C_{cim} Ccim 分别是经过上采样到 352 × 352 352 \times 352 352×352 分辨率的两个伪装物体图, G G G 是对应的标签(ground-truth)。通过最小化该损失函数,SINet能够逐步优化模型的伪装物体检测效果。
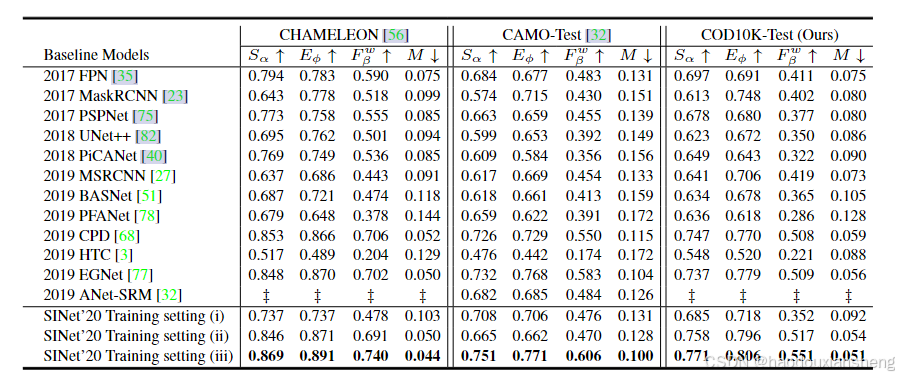
结果
这张表格展示了SINet相较于其他COD模型的性能优势,特别是在多数据集联合训练下达到了最佳结果。SINet在结构相似性(
S
α
S_\alpha
Sα)、E-measure(
E
ϕ
E_\phi
Eϕ)和加权F-measure(
F
w
β
F_w^\beta
Fwβ)方面的领先地位,表明该方法在不同场景下具有较高的鲁棒性和精度,适用于伪装物体检测任务。


















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









