




 本文详细介绍了序列化和反序列化的基本概念,以及在SOME/IP协议中的应用。SOME/IP使用序列化来转换数据结构为字节序以便网络传输,通常采用4字节对齐以优化效率。文中还讨论了大小端问题、内存对齐和填充策略,以及数据类型的序列化规则,包括基础数据类型、结构体、字符串和数组。此外,提到了TLV格式作为可选的序列化方式,以及联合体的序列化处理。
本文详细介绍了序列化和反序列化的基本概念,以及在SOME/IP协议中的应用。SOME/IP使用序列化来转换数据结构为字节序以便网络传输,通常采用4字节对齐以优化效率。文中还讨论了大小端问题、内存对齐和填充策略,以及数据类型的序列化规则,包括基础数据类型、结构体、字符串和数组。此外,提到了TLV格式作为可选的序列化方式,以及联合体的序列化处理。
什么是序列化与反序列化?
- 序列化是指将数据结构或对象按定义的规则转换成二进制串的过程。
- 反序列化是指将二进制串依据相同规则重新构建成数据结构或对象的过程。
而本质就是一种编码规范。
在SOME/IP中使用序列化的目的和作用?
- 使数据按照固定格式进行编排成为字节序,实现数据在网络上的传输。
7.1 说明
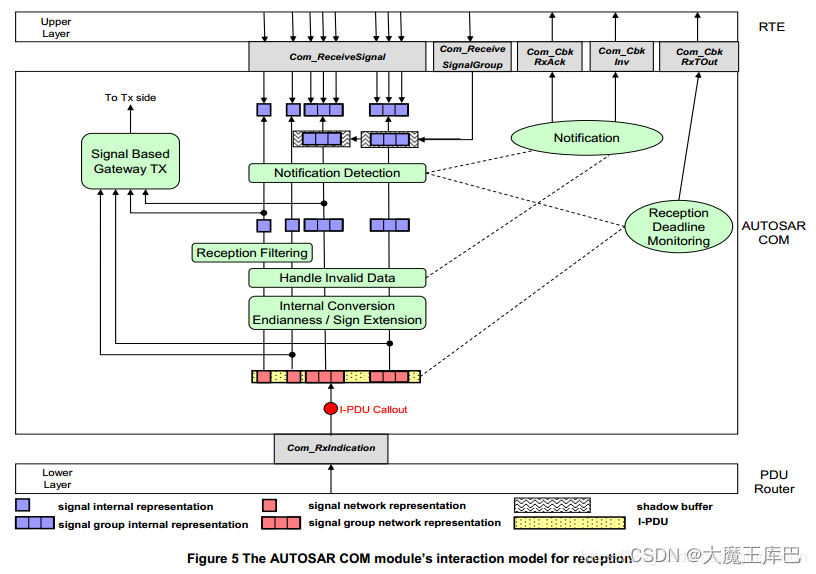
在AUTOSAR中是指数据在PDU中的表达形式,可以理解为来自应用层的真实数据转换成固定格式的字节序,以实现数据在网络上的传输。软件组件将数据从应用层传递到RTE层,在RTE层调用SOME/IP Transformer,执行可配置的数据序列化(Serialize)或反序列化(Deserialize)。SOME/IP Serializer将结构体形式的数据序列化为线性结构的数据;SOME/IP Deserializer将线性结构数据再反序列化为结构体形式数据。在服务端,数据经过SOME/IP Serializer序列化后,被传输到服务层的COM模块;在客户端,数据从COM模块传递到SOME/IP Deserializer反序列化后再进入RTE层。如下图参考Autosar Com过程。
7.2 大小端问题
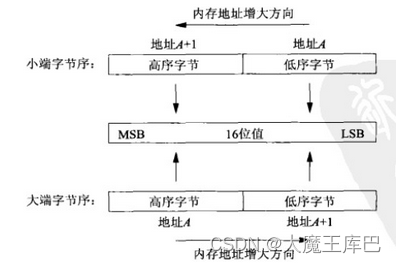
对于一个由2个字节组成的16位整数,在内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种方法是将高序字节存储在起始地址,这称为大端(big-endian)字节序。
假如现有一32位int型数0x12345678,那么其MSB(Most Significant Byte,最高有效字节)为0x12,其LSB (Least Significant Byte,最低有效字节)为0x78,在CPU内存中有两种存放方式:(假设从地址0x4000开始存放)
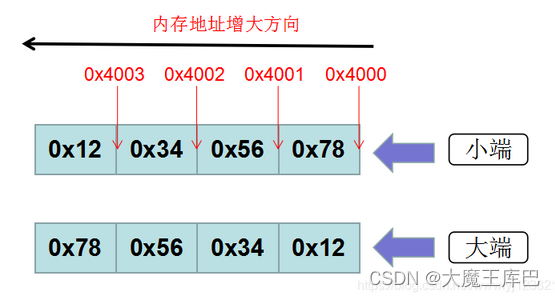
总结:
- 大端是高字节存放到内存的低地址
- 小端是高字节存放到内存的高地址
假如有一个数据是0x12345678,直接用memcpy将这个数copy到下图中的Length里面来,如果是大端的话,((uint8)Length)[0]就等于0x12;如果是小端的话,就是0x78。

因为对于赋值的方便性来讲,大端是网络通信中常用的方式(例如TCP/IP),所以SOME/IP格式头也使用大端。Payload由于是用户自主定义的内容,所以用户可以自己决定大小端。
7.3 内存对齐与填充
SOME/IP协议通常使用4字节对齐方式进行数据传输。这意味着每个字段的长度应该是4的倍数。这种对齐方式的主要目的是提高传输效率,因为在很多处理器架构中,4字节对齐是最优的方式,可以在内存中更快地访问数据。此外,使用4字节对齐方式还可以确保字段的偏移量是整数,避免了在解析数据时出现未对齐数据的问题。
在进行SOME/IP序列化时,对于每个结构体中的字段,需要根据其数据类型和对齐要求计算其对齐偏移量。对于大多数数据类型,SOME/IP协议都要求其对齐偏移量是4的倍数。例如,对于一个8字节的double类型字段,其对齐偏移量应该是4的倍数,即0、4、8、12等。如果字段的大小不是4的倍数,那么需要在其后添加额外的填充字节,以便满足对齐要求。
在某些情况下,为了提高传输效率,可能需要使用不同的对齐方式。例如,在某些嵌入式系统中,可能需要使用2字节对齐或8字节对齐方式。在这种情况下,SOME/IP协议可以通过在消息头中包含对齐方式信息来指定所使用的对齐方式。但是,这需要在消息头中添加额外的信息,可能会导致消息大小增加,降低传输效率。因此,4字节对齐方式仍然是SOME/IP协议中最常用的对齐方式。(有些项目实际使用中用的是1字节对齐,即不对齐。因为1字节对齐是最简单的对齐方式,大多编译器很容易实现;并且采用一字节对齐,序列化后没有冗余数据,报文的有效负载段都是有意义的数据,所以总体传输效率得到了一定提升。)
通过在数据后插入填充元素来对齐数据的开头,以确保对齐的数据从特定的内存地址开始。对于有些处理器架构可以更高效地访问数据。
当可变元素不是序列化数据流中最后一个元素,应依据规则对可变元素进行位填充来实现数据对齐。
填充示例:
示例1.
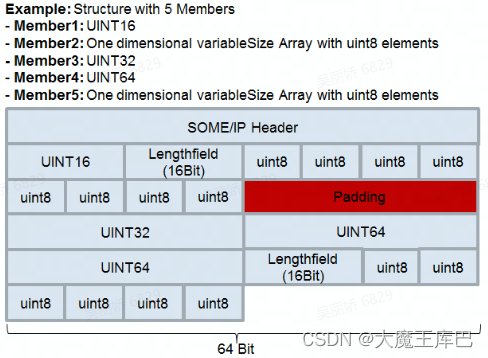
示例2.
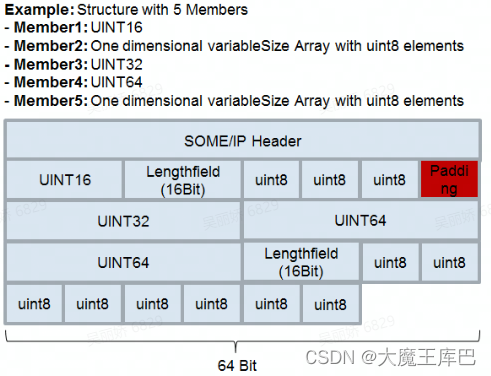
注:数据对齐填充应尽量以8、16、32、64、128或256长度长度进行。
但是!
对于不同的CPU
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1398
1398




 到【灌水乐园】发言
到【灌水乐园】发言









