




 本文详细介绍了策略评价的常用指标,如年化收益率、最大回撤、贝塔值、阿尔法值和夏普比率,以及如何通过计算实例来评估投资策略的表现。通过实例演示了如何计算这些指标,以及如何结合实际市场数据进行策略效果的对比和优化。
本文详细介绍了策略评价的常用指标,如年化收益率、最大回撤、贝塔值、阿尔法值和夏普比率,以及如何通过计算实例来评估投资策略的表现。通过实例演示了如何计算这些指标,以及如何结合实际市场数据进行策略效果的对比和优化。
一、策略评价指标
设计了一个策略后,需要通过回测来评价其效果如何。常用的评价指标包括:
1.年化收益率
年化收益率是为了将不同策略的收益结果转换到同一个体系下,方便进行效果比较和评价。计算公式为:
年化收益率=(策略当前净值/策略初始净值)^(年交易日天数/回测期间总天数)-1
其中,年交易日天数是指A股市场一年的交易日天数。由于节假日的原因每年的天数是不同的,大概在230~250天之间,可以取平均值244。
给大家几个参考数据让大家要心里有个数:
(1)从1965年至2021年,巴菲特旗下的伯克希尔哈撒韦公司的年化收益率高达20.1%,而同期标普500指数的年化收益率10.5%。
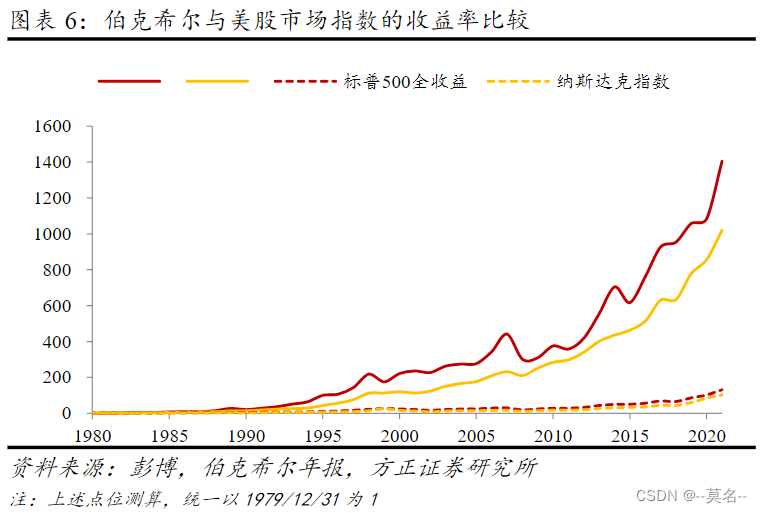
(2)大卫·西格尔在《股市长线法宝》一书中,对美国股市过去200多年的数据进行测算,扣除通货膨胀因素得到年化收益率是6.6%,如果不扣除通货膨胀因素的年化收益率是10%左右。
(3)上证指数从1990年12月19日到2021年6月24日,指数从100点涨到3566.65点,在约30.5年时间上涨了34倍多,年化收益率约12.43%。
(4)整个A股从开市到现在的年化收益率差不多也是10%左右。
以上数据均来自网上,有兴趣的朋友可以自己编程去算一下。如果你的策略跑出来的年化收益率动辄翻倍甚至几倍,好吧,你将赢得全世界!!!~~~做完梦记得好好检查下策略哪里写错了:)
2.最大回撤
最大回撤是指账户净值从上一个最高点到当前计算时间点的最大下跌幅度,在这些最大下跌幅度中取最小值(下跌幅度为负)作为最大回撤。用来描述策略可能出现的最糟糕情况,即衡量最极端情况下的亏损百分比。计算公式为:
最大回撤=min(账户当日净值 / 当日之前账户最高净值-1)。
注意,每当净值到达新的最高点时,回撤归零,需要更新计算公式中的账户最高净值。
如果一个策略的年化收益为30%,最大回撤是70%,那么你使用这个策略之前就要想想,是否能扛得住70%的下跌。打个比方,如果净值是1,下跌70%意味着后续净值要翻3.3倍才能回到1,能够让你深刻的体会到什么叫生不如死,这么坑的策略还是不要用了~~~~
3.贝塔值(beta)
根据资本资产定价理论(CAPM模型),beta系数衡量策略的回报率对市场变动的敏感程度,代表了该策略的结构性和系统性风险,表示策略与基准的相关性。简单点说就是策略的收益相对于业绩评价基准收益的总体波动性,或者叫做承担市场风险带来的投资收益。
计算公式为:
beta=策略日收益与基准日收益的协方差 / 基准日收益的方差。
比如策略采用的评价基准为沪深300指数,计算得到的beta如下:
beta=1说明策略和沪深300指数的收益变化一致。
beta=1.1说明沪深300指数上涨10%时,策略上涨11%;沪深300指数下跌10%时,策略下跌11%。
beta=0.9说沪深300指数上涨10%时,策略上涨9%;沪深300指数跌10%时,策略下跌9%。
那么现在问题来了,这个beta值到底怎么看好呢?不能一概而论。如果是牛市,个股、大盘上涨概率很大,应该选择beta值大的策略,从而获取高收益(这就是研报中常常提到的高beta系数策略);如果是熊市,大盘下跌可能性更大,就应该选择beta值小的策略,以降低回撤,确保资金的安全。
4.阿尔法值(alpha)
alpha值表示实际收益和平均预期收益的差额,衡量策略的非系统性风险。简单点说就是策略跑赢比较基准获得的超额收益大小。计算公式为:
alpha=(账户年化收益-无风险收益)-beta*(基准年化收益-无风险收益)
评价所设计的策略获得超额收益的能力大小。
5.账户收益波动率(Volatility)
账户收益波动率用来测量资产的风险性,波动越大代表策略风险越高。计算公式如下:
账户收益波动率=收益标准差*年交易日天数的平方根
6.夏普比率(Sharpe ratio)
夏普比率是一个可以同时对收益与风险加以综合考虑的经典指标,表示每承受一单位风险,会产生多少的超额回报。计算公式为:
夏普比率=(策略年化收益率-无风险利率)/ 策略收益波动率。
其中的无风险利率通常采用10年期国债年化收益率,可参考这个网站。
由于夏普比率代表单位风险所获得的超额回报率。该比率越高,策略承担单位风险得到的超额回报率越高,所以说夏普比率是越高越好。需要注意的是,夏普比率没有基准点,因此其绝对大小本身没有意义,只有在与其他策略的比较中才有价值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









