






我们前面介绍了笔记本电脑如何部署PyTorch环境(复制成功!GTX1050Ti换版本安装Pytorch、CUDA和cuDNN),也介绍了Tesla系列GPU如何部署PyTorch环境(Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch),再后来,我们也用4070显卡介绍了ollama工具的使用(哪怕用笔记本的4070显卡运行DeepSeek,都要比128核的CPU快得多!)。
但在使用过程中,我们发现使用vLLM部署大模型时,无论是单请求吞吐量、并发吞吐量、支持的模型尺寸等,整体性能都要优于ollama。但是,vLLM的核心框架主要针对Linux和CUDA环境优化,不能直接运行在Windows环境中;当然,我们也可以使用WSL来进行部署(在Windows 11上启用WSL(适用于Linux的Windows子系统)),但是资源利用率会有所下降。
当然,运行vLLM也对GPU的计算架构有所要求,比如我之前用的Tesla P40(清华大模型ChatGLM3在本地Tesla P40上也运行起来了),虽然显存够大,但是架构版本是6.1的Pascal架构,不支持FP16,需要到7.0版本的Volta架构才支持,也就是到Tesla V100这一代;但是7.0版本又不支持BF16,需要8.0版本的Ampere架构才能支持,这就到了A100这一代了(A10本地部署的DeepSeek-R1:32b做逻辑推理题)。至于大家熟悉的Tesla T4,夹在中间,属于7.5版本的Turing架构。
既然如此,我不是还有一台RTX4070的笔记本电脑吗?是8.9版本的Ada Loverlace架构,跟L20属于同一代。所以,我们本次将在4070笔记本上安装Ubuntu操作系统,然后进行后续操作。
开始操作之前,先介绍一下软件版本信息:vLLM的当前最高版本为0.7.4,能支持的PyTorch最高版本为2.5.1,对应的CUDA版本最高为12.4,对应的操作系统为Ubuntu 22.04 LTS,显卡驱动为550.144.03。
电脑型号为机械革命极光X,处理器为12th Gen Intel(R) Core(TM) i7-12800HX,24核心;搭配32 GB(DDR5@4800 MHz)运行内存,500 GB系统盘(NVMe);显卡型号RTX4070,8 GB显存(8188MiB)。
首先安装Ubuntu 22.04.5 LTS操作系统,建议使用DD刻录启动U盘;电脑如果支持Secure Boot,建议关闭,要不然后续操作会很麻烦。
系统安装过程参考图文(没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机)或以下视频:
系统安装好之后,我们先安装显卡驱动程序,到NVIDIA官网搜索驱动文件。
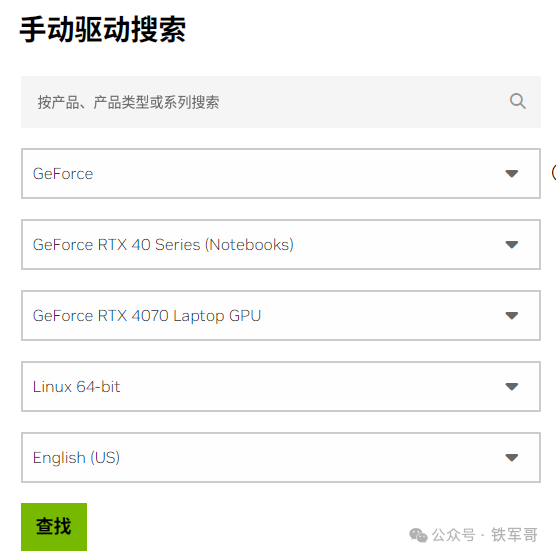
因为桌面显卡不支持按照CUDA版本进行搜索,所以你可以直接找550.144.03这个版本,对应的就是CUDA 12.4版本。
驱动版本:550.144.03发布日期:Thu Jan 16, 2025操作系统:Linux 64-bit语言:English (US)文件大小:307.27 MB或者,你直接用下面的下载链接也行:
https://us.download.nvidia.com/XFree86/Linux-x86_64/550.144.03/NVIDIA-Linux-x86_64-550.144.03.run
在安装之前,我们需要准备相关的编译安装环境:
apt install gcc make dkms -y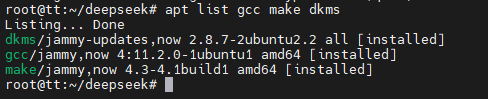
然后,下载驱动文件,赋予可执行权限,并运行:
wget https://us.download.nvidia.com/XFree86/Linux-x86_64/550.144.03/NVIDIA-Linux-x86_64-550.144.03.runchmod +x NVIDIA-Linux-x86_64-550.144.03.run./NVIDIA-Linux-x86_64-550.144.03.run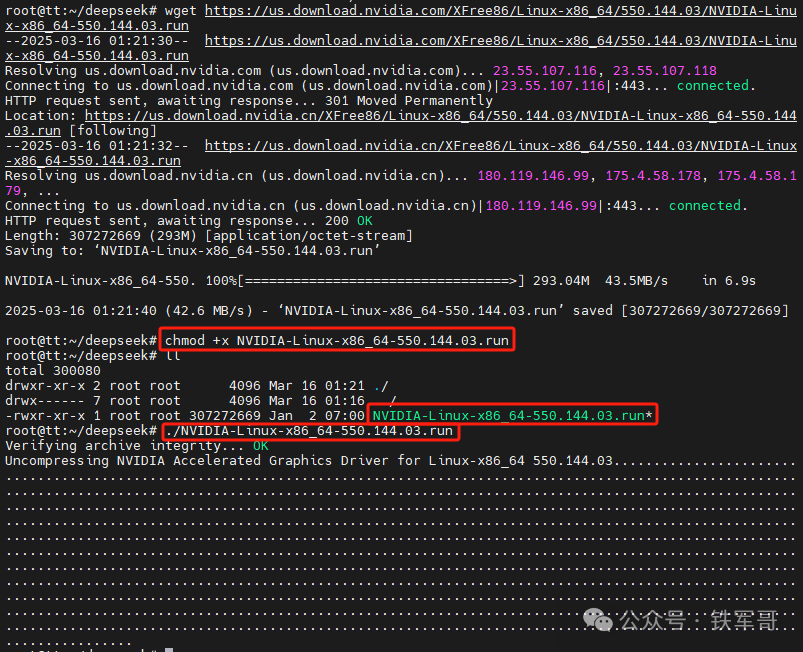
整体安装过程很简单,基本都是选择默认操作即可。驱动信息页面,选择【Continue installations】。
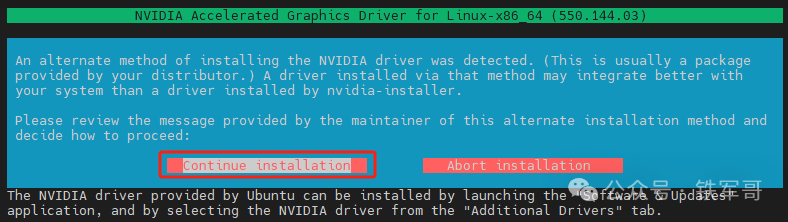
安装完成后,系统提示修改X Module配置。
将32位的兼容库也安装上。

安装过程中检测到Vulkan组件缺失的警告,具体原因是系统缺少Vulkan ICD加载器(Vulkan Installable Client Driver Loader),导致NVIDIA的Vulkan驱动无法正常工作。这个后面可以通过命令来修复:
apt install vulkan-icd-loader vulkan-tools libnvidia-gl-550.144.03
DKMS是Linux内核模块的自动化编译框架,当系统升级内核时,可以自动重新编译NVIDIA驱动;吐过没有注册到DKMS,每次内核更新后需手动重新安装驱动,所以我们选择注册。

开源驱动Nouveau残留在initramfs中,可能与新安装的NVIDIA官方驱动产生冲突,我们选择重建initramfs。

是否自动更新X Window系统的配置文件xorg.conf,以强制X Server加载NVIDIA驱动,取代开源驱动Nouveau。对于单显卡笔记本,无需复杂显示配置,追求快速启用NVIDIA驱动,选择Yes。

驱动程序安装完成。

这样,无需重启系统,我们也能直接执行nvidia-smi命令查看显卡状态了。
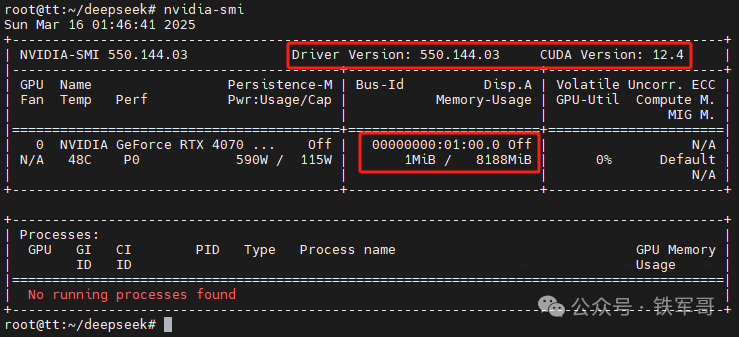
接下来,我们安装CUDA 12.4,首先下载配置APT包管理器优先级,确保CUDA相关软件从指定仓库安装。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinmv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
然后下载CUDA安装程序,并运行。
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.debdpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
按照提示复制秘钥文件,再次安装即可,安装完成之后,更新软件仓库。
cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/apt-get update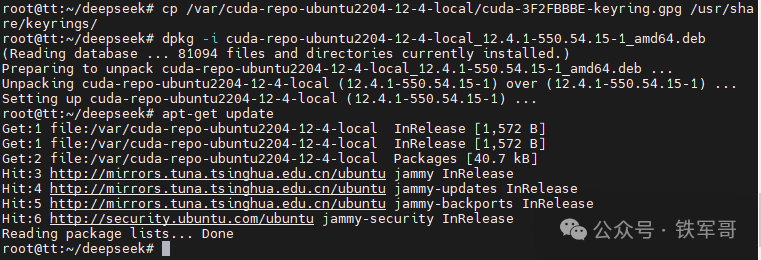
完成CUDA的安装。
apt-get -y install cuda-toolkit-12-4选择安装传统内核模块cuda-drivers,执行以下命令:
apt-get install -y cuda-drivers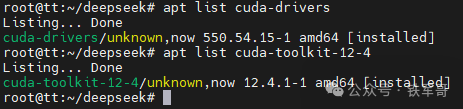
查看CUDA版本信息。
/usr/local/cuda-12.4/bin/nvcc --version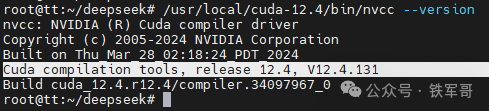
接下来,安装cuDNN,跟安装CUDA的操作过程类似。
wget https://developer.download.nvidia.com/compute/cudnn/9.8.0/local_installers/cudnn-local-repo-ubuntu2204-9.8.0_1.0-1_amd64.debdpkg -i cudnn-local-repo-ubuntu2204-9.8.0_1.0-1_amd64.debcp /var/cudnn-local-repo-ubuntu2204-9.8.0/cudnn-*-keyring.gpg /usr/share/keyrings/apt-get update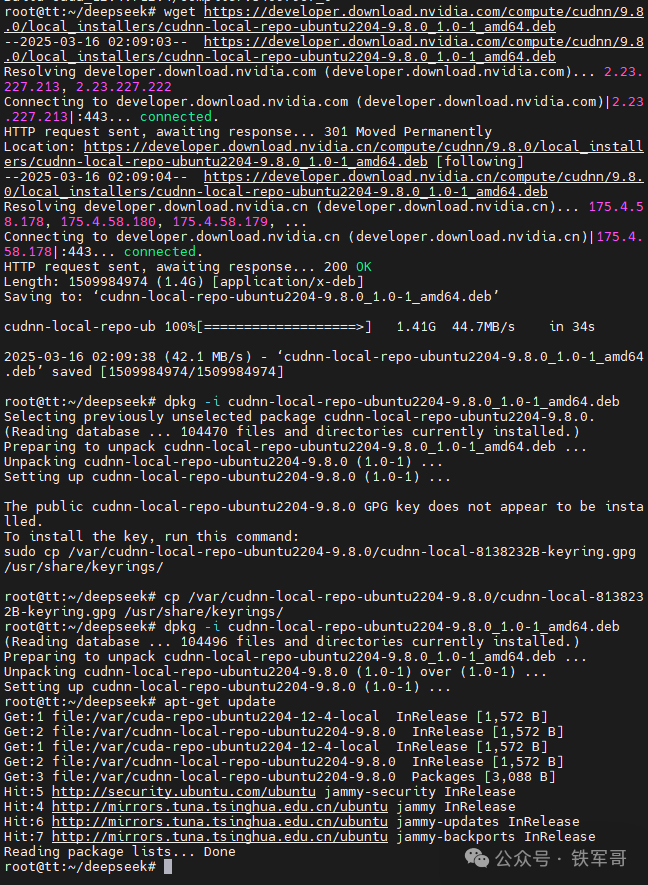
最后安装cuDNN。
apt-get -y install cudnn
vLLM对PyTorch版本敏感,建议严格匹配版本。对于Ubuntu 22.04系统,自带的Python版本为3.10,满足vLLM要求的3.8版本的要求。
我们先创建一个Python虚拟环境并激活,用于安装vLLM。
apt install python3.10-venv -ypython3.10 -m venv vllm_envsource vllm_env/bin/activate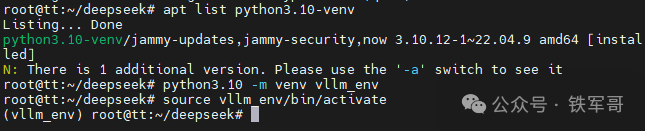
安装vLLM需要用到PyTorch,对应的版本信息如下:
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124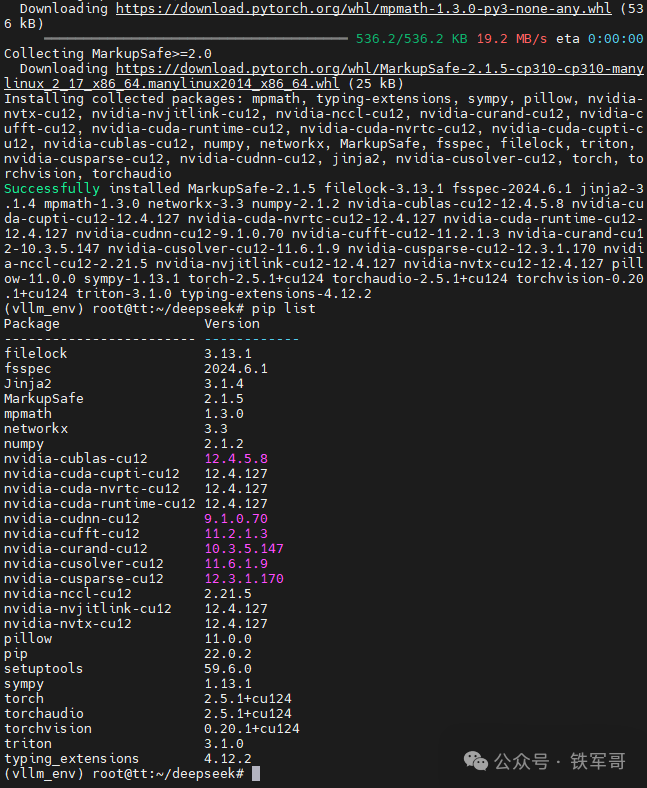
最后,安装vLLM。
pip install vllm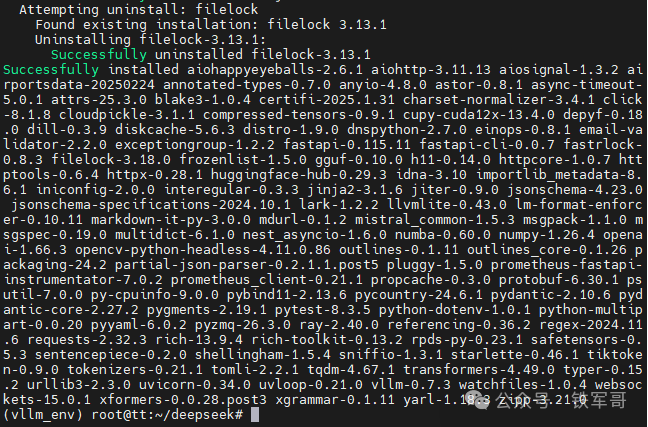
好了,到这里,vLLM环境就准备好了,后面,我们就能下载DeepSeek模型文件来进行测试了。
***推荐阅读***
DeepSeek-R1内卷把自己卷死了,QwQ模型的优势凸显出来了
用Anything LLM来一场关于SD-WAN的开卷考试,DeepSeek-R1和QwQ谁更胜一筹?
目前来看,ollama量化过的DeepSeek模型应该就是最具性价比的选择
哪怕用笔记本的4070显卡运行DeepSeek,都要比128核的CPU快得多!
帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型
离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理
Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch
没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机
使用openVPN对比AES和SM4加密算法性能,国密好像也没那么差



















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











