



1.前言
今年过年,deepseek一下子爆火,导致我前段时间好好用的官网直接挤爆了,一直转圈圈到没心思过了,天天挂热搜,直接导致我的科研工作受阻(dog),好吧,话不多说,看看怎么在本地部署deepseek丝滑享受以及白嫖一下api体验>_<!
部署环境:
系统:ubuntu22.04
显卡:一张4090,24G显存
2.vllm部署deepseek-R1-8B
2.1 vllm安装
conda create -n vllm python==3.11
conda activate vllm
pip install vllm
2.2 模型下载
直接去HF官网找到官方发布的模型仓库https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/tree/main,可以自己用浏览器下载或者迅雷下载(我觉得这个快一点)亦或者HF提供的下载方式
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
下载路径随意
2.3 使用 vLLM 启动推理服务
python -m vllm.entrypoints.openai.api_server --model <你下载的模型的路径> --served-model-name <Deepseek-R1-8B> --max-model-len=16384 --trust-remote-code
部署结束
3.ollama部署deepseek-R1-32B
3.1下载安装ollama
直接搜索ollama官网,首页直接下载,
ollama在linux上的下载命令如下:
curl -fsSL https://ollama.com/install.sh | sh
有时候可能下载会中断,按照下面的方法修改可以解决:
# 下载安装脚本
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh
# 给脚本添加执行权限
chmod +x ollama_install.sh
# 使用github文件加速替换github下载地址
sed -i 's|https://ollama.com/download/ollama-linux|https://gh.llkk.cc/https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux|g' ollama_install.sh
#执行下载
sh ollama_install.sh
安装之后默认是会自动运行的
3.2部署运行指定模型
在ollama的网页中,直接点到models页面,搜索指定模型,然后进入页面,复制运行部署模型的命令
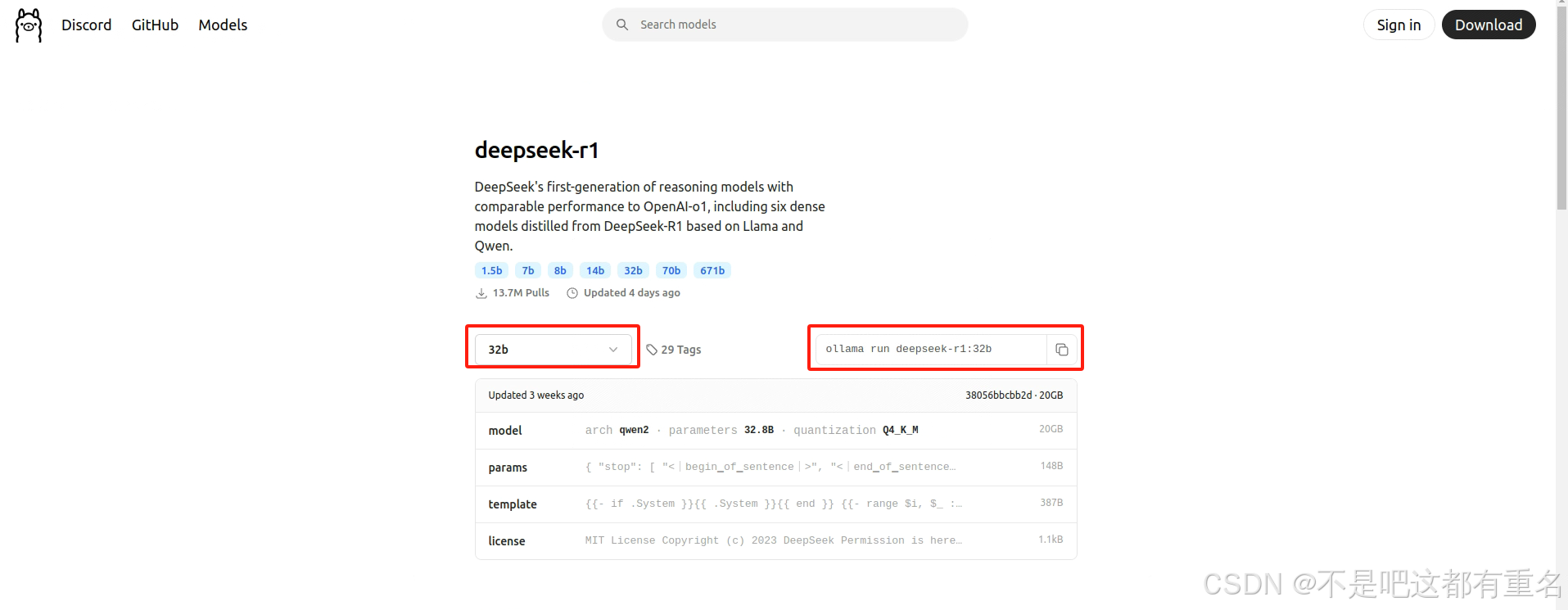
ollama run deepseek-r1:8b
接下来就是漫长的等待过程,等待模型下载完成,有时候可能会碰到网速先高后低的情况,断掉重新下载就可以,ollama可以断点续传。
如果不想这么操作,欢迎看这篇博文ollama模型一键满速下载
4.效果展示
4.1写个计算器试试
满血版V3的效果:
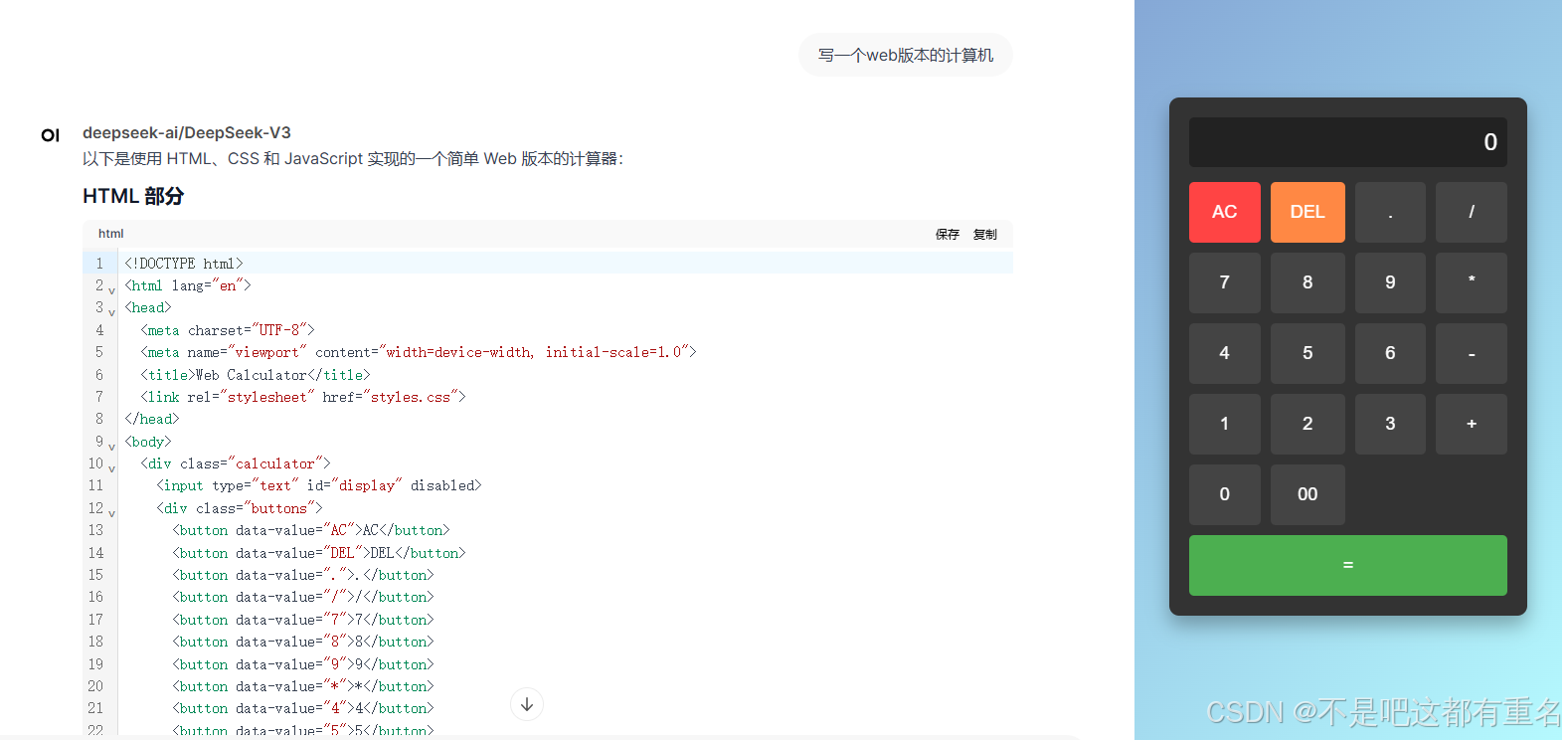
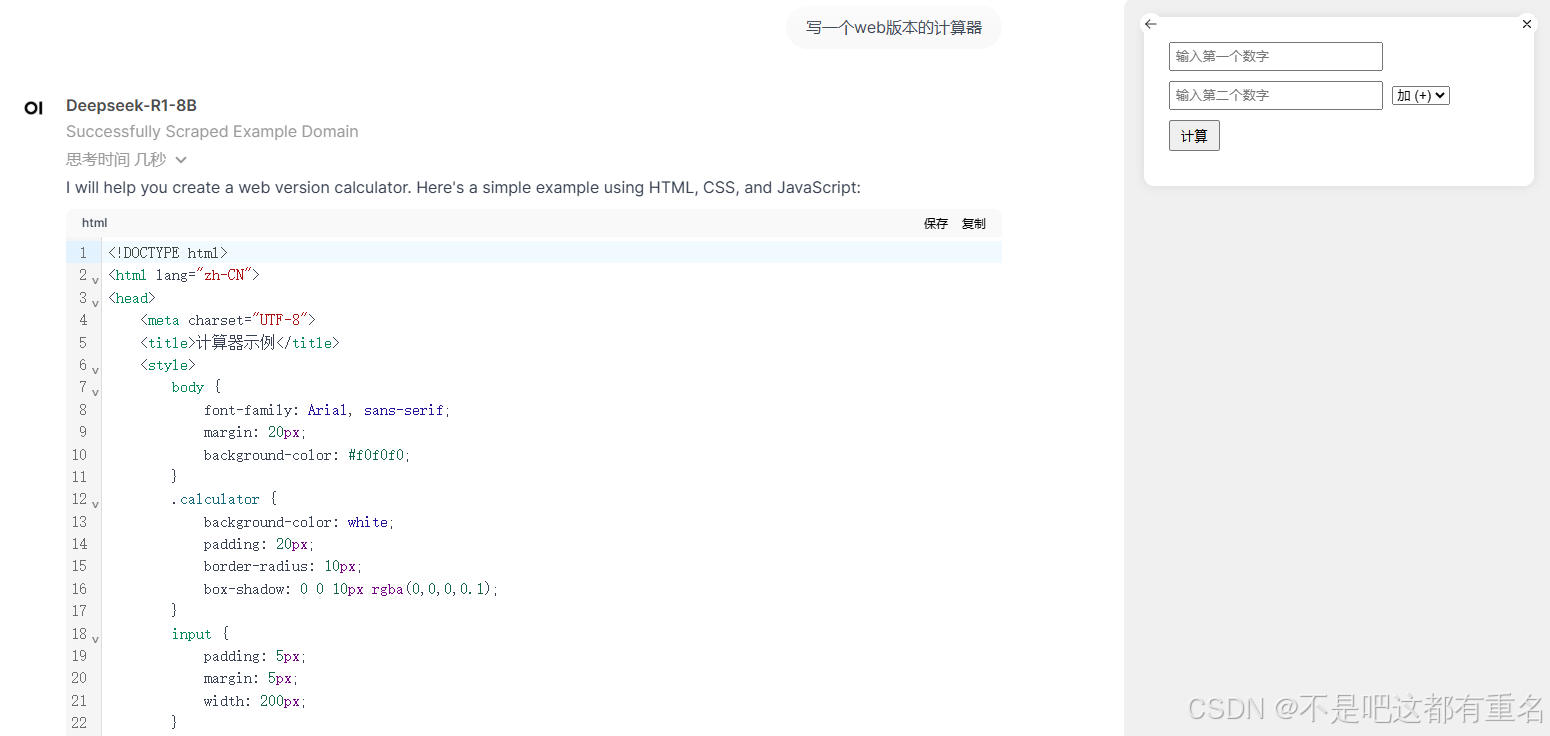
本地部署的Deepseek-R1-8B的效果:

本地部署的Deepseek-R1-14B的效果:
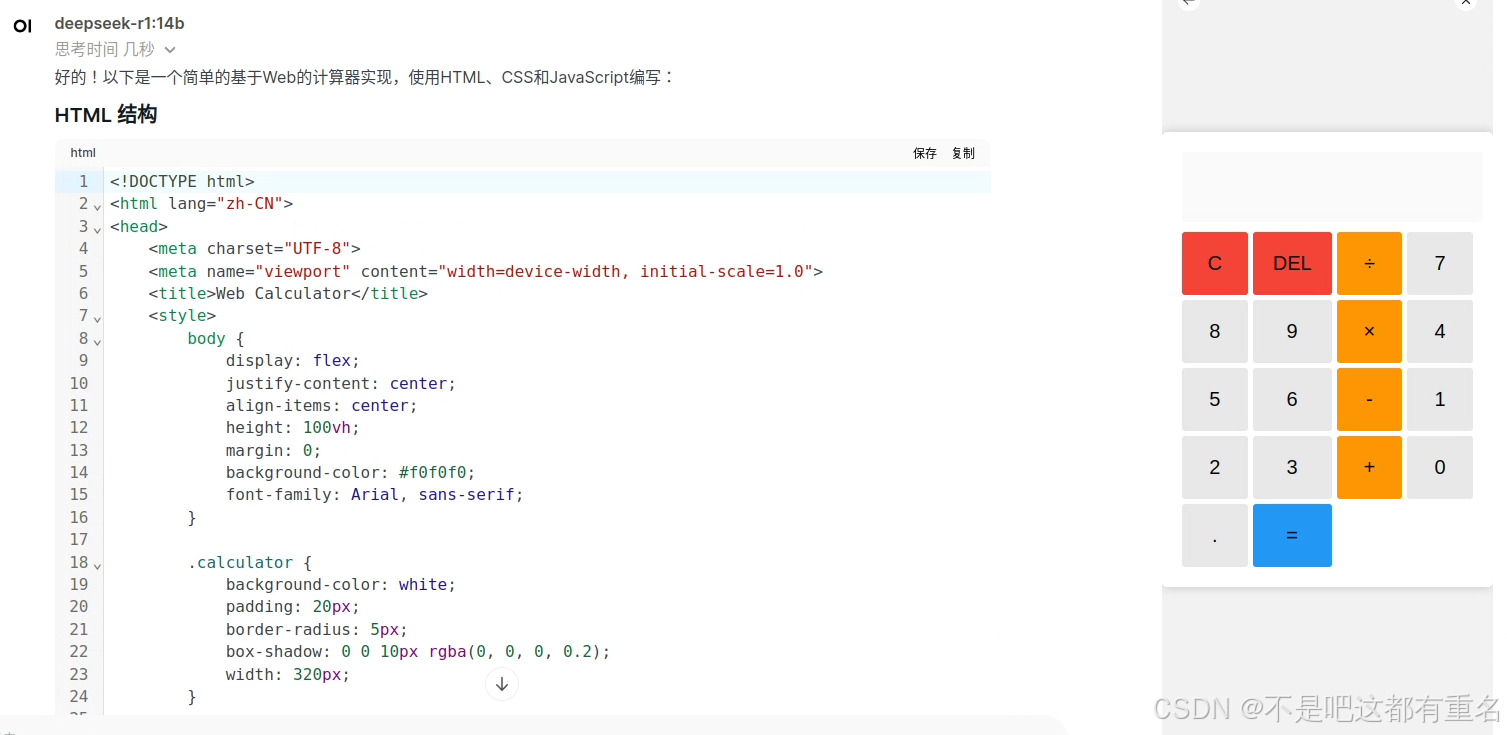
可以直观的看到不同参数量的表现了,本地部署14B及以下的看来只能玩玩了




















 6052
6052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











