







 AdaBoost是一种自适应增强算法,通过调整训练数据权重来训练弱分类器,并组合成强分类器。在sklearn中,AdaBoostClassifier提供了SAMME和SAMME.R两种实现。调参主要包括框架参数如n_estimators(弱分类器数量)、learning_rate(步长)以及弱学习器参数。实验表明,改变这些参数会影响模型的拟合效果和过拟合风险。
AdaBoost是一种自适应增强算法,通过调整训练数据权重来训练弱分类器,并组合成强分类器。在sklearn中,AdaBoostClassifier提供了SAMME和SAMME.R两种实现。调参主要包括框架参数如n_estimators(弱分类器数量)、learning_rate(步长)以及弱学习器参数。实验表明,改变这些参数会影响模型的拟合效果和过拟合风险。
AdaBoost
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由 Yoav Freund 和 Robert Schapire在1995年提出。它的自适应在于:前一个基本分类器分错的样本会得到加强(也就是得到更高的权重),加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数,算法停止。
具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权重。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
原则上,只要表现略好于随机猜测的算法都可以作为弱学习器,以决策树作为弱学习器的AdaBoost通常被称为最佳开箱即用的分类器。
Scikit-Learn中AdaBoost类库比较直接,就是AdaBoostClassifier和AdaBoostRegressor两个,从名字就可以看出AdaBoostClassifier用于分类,AdaBoostRegressor用于回归。 AdaBoostClassifier使用了两种AdaBoost分类算法的实现,SAMME和SAMME.R。而AdaBoostRegressor则使用了Adaboost.R2。
对Adaboost调参,主要要对两部分内容进行调参,第一部分是对Adaboost的框架进行调参, 第二部分是对选择的弱分类器进行调参。两者相辅成。下面就对AdaBoostClassifier从这两部分做一个介绍。
AdaBoost分类器
class sklearn.ensemble.AdaBoostClassifier (base_estimator = None,n_estimators = 50,learning_rate = 1.0,algorithm =‘SAMME.R’,random_state = None )
核心参数
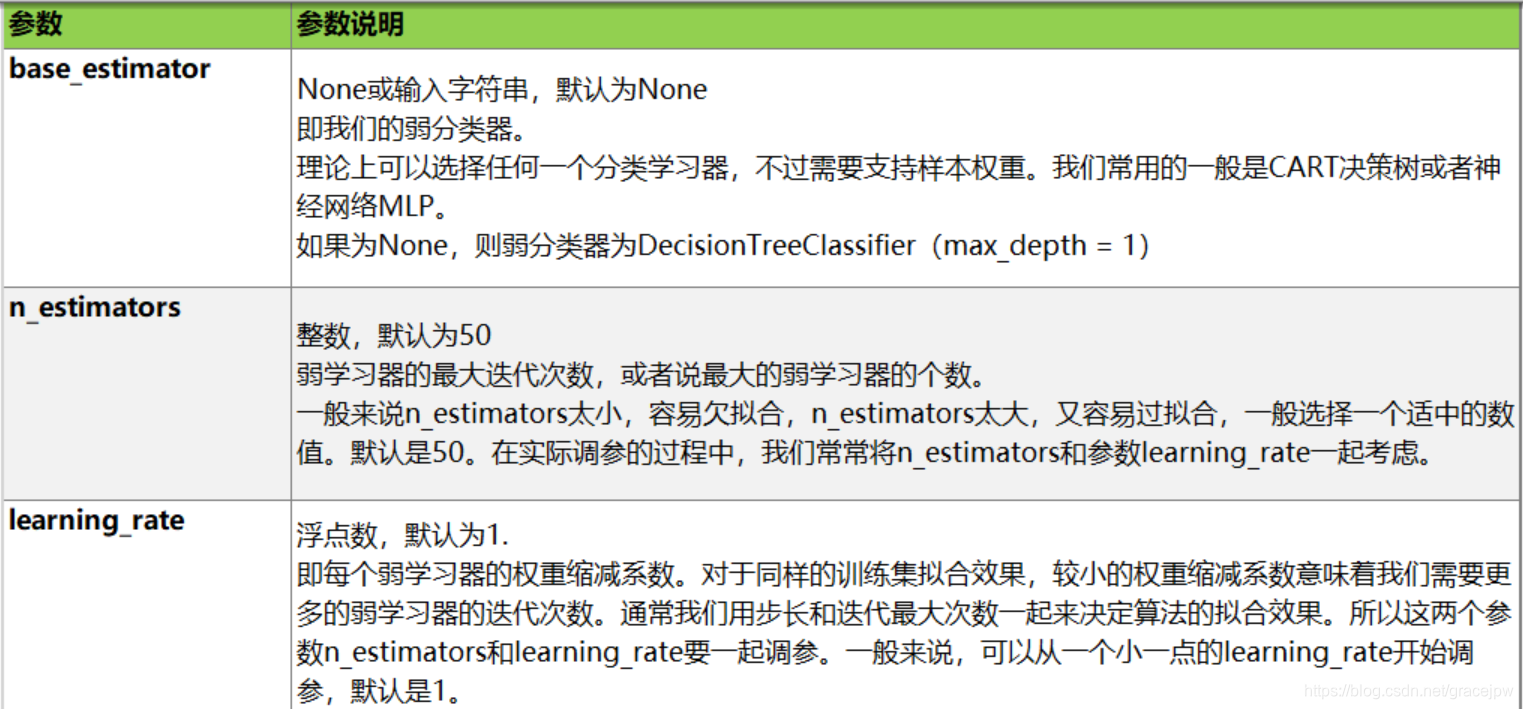

弱学习器参数
由于使用不同的弱学习器,则对应的弱学习器参数各不相同。这里仅讨论默认的决策树弱学习器的参数。即回顾下CART分类树DecisionTreeClassifier和CART回归树DecisionTreeRegressor。


AdaBoostClassifier
#AdaBoostClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征,协方差系数为2
X1, y1 = make_gaussian_quantiles(cov=2.0,n_samples=500,
n_features=2,n_classes=2, random_state=1)
# 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3,协方差系数为1.5
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,n_samples=400,
n_features=2, n_classes=2, random_state=1)
#将两组数据合成一组数据
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
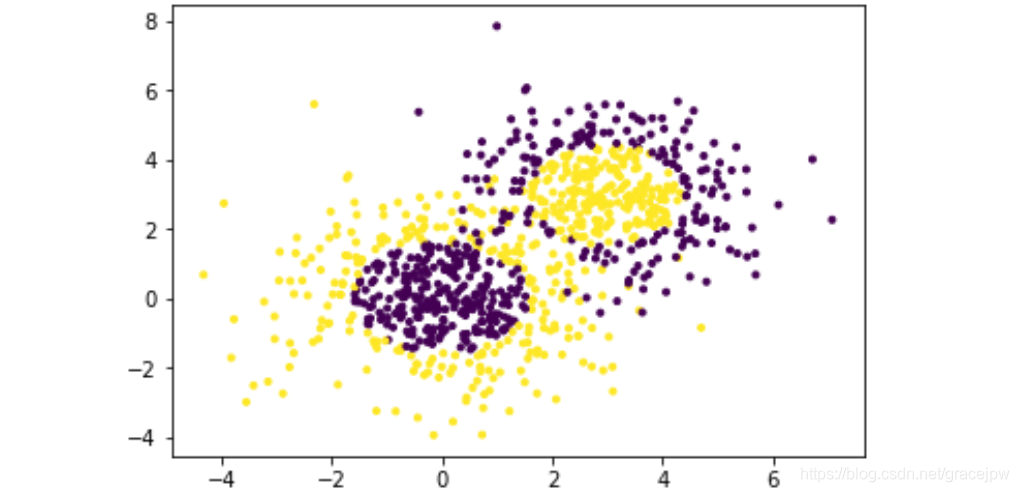
#可视化分类数据,它有两个特征,两个输出类别,用颜色区别。
plt.scatter(X[:, 0], X[:, 1], marker='.', c=y);
这里我们选择了SAMME算法,最多200个弱分类器,步长0.8,在实际运用中,可能需要通过交叉验证调参而选择最好的参数。拟合完了后,用网格图来看看它拟合的区域。
#网格图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()])#.c_将切片对象沿第二轴进行连接
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], s=8, marker='o', c=y)
plt.show()
#可以看到数据有些混杂,现在用基于决策树的Adaboost来做分类拟合
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,
min_samples_split=20,
min_samples_leaf=5)
,algorithm="SAMME",n_estimators=200, learning_rate=0.8)
bdt.fit(X, y)
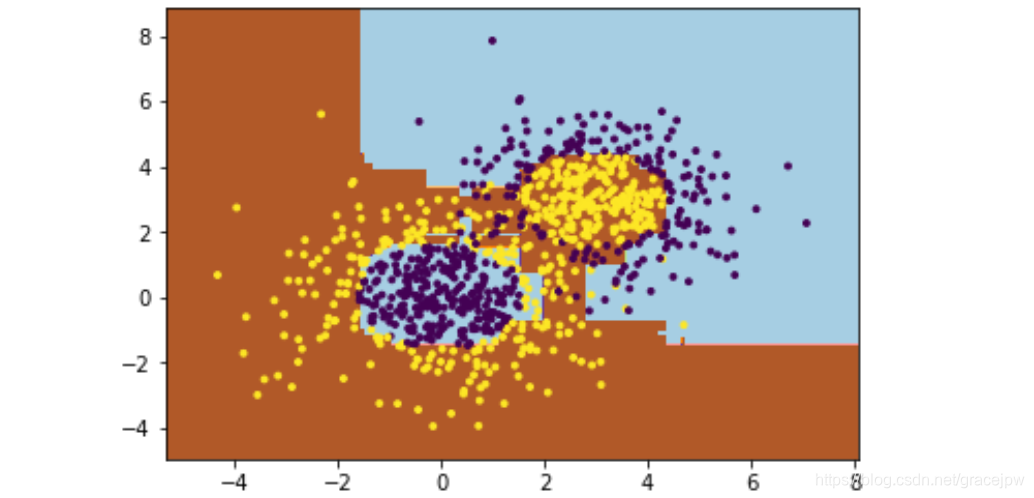
可以看出,Adaboost的拟合效果还是不错的,再看看拟合分数
#拟合分数
print("Score:" ,bdt.score(X,y))
Score: 0.9133333333333333
拟合训练集数据的分数还不错。当然分数高并不一定好,因为可能过拟合。
现在将最大弱分离器个数从200增加到300。再来看看拟合分数。
#将最大弱分离器个数从200增加到300,再看拟合分数
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,
min_samples_split=20,
min_samples_leaf=5)
,algorithm="SAMME",n_estimators=300, learning_rate=0.8)
bdt.fit(X, y)
print("Score:" ,bdt.score(X,y))
Score: 0.9622222222222222
这印证了前面讲的,弱分离器个数越多,则拟合程度越好,当然也越容易过拟合。
现在降低步长,将步长从上面的0.8减少到0.5,再来看看拟合分数。
#将步长从上面的0.8减少到0.5,再来看看拟合分数
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,
min_samples_split=20,
min_samples_leaf=5)
,algorithm="SAMME",n_estimators=300, learning_rate=0.5)
bdt.fit(X, y)
print("Score:" ,bdt.score(X,y))
Score: 0.8944444444444445
可见在同样的弱分类器的个数情况下,如果减少步长,拟合效果会下降。
最后,看看当弱分类器个数为700,步长为0.7时候的情况:
#当弱分类器个数为700,步长为0.7时候的情况
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,
min_samples_split=20,
min_samples_leaf=5)
,algorithm="SAMME",n_estimators=700, learning_rate=0.7)
bdt.fit(X, y)
print("Score:" ,bdt.score(X,y))
Score: 0.9688888888888889
此时的拟合分数和我们最初的300弱分类器,0.8步长的拟合程度相当。也就是说,在这个例子中,如果步长从0.8降到0.7,则弱分类器个数要从300增加到700才能达到类似的拟合效果。
可见,步长相关参数learning_rate的微降可以起到n_estimators大幅增加才能达到的拟合效果。

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









