




 本文介绍了将YoloV3-Tiny模型移植到Zynq020 FPGA的过程,包括模型简介、PyTorch处理、RTL移植、验证以及上板测试和优化空间。在移植过程中,模型经过训练和int8量化,实现了320x320@15Hz的目标检测,并在FPGA上进行本地推断,确保了与上位机相同的精度。
本文介绍了将YoloV3-Tiny模型移植到Zynq020 FPGA的过程,包括模型简介、PyTorch处理、RTL移植、验证以及上板测试和优化空间。在移植过程中,模型经过训练和int8量化,实现了320x320@15Hz的目标检测,并在FPGA上进行本地推断,确保了与上位机相同的精度。

“ yolov3-tiny移植zynq020概述。”
01
yolov3-tiny模型
yolo是目前目标检测落地到硬件中比较常用的AI模型,因为yolo标准版模型参数和计算量太大,所以目前暂时在zynq020上移植的是tiny版本,这里选用yolov3-tiny来移植,输入模型的图像源320x320@15Hz,模型各层如下(其中C是训练时的类别):

02
模型pytorch处理
yolo模型需要经过训练(检测多少个类别)和int8量化(暂时未使用剪枝、压缩处理),然后生成权重等参数,再测试量化后的检测精度(基本和官网量化前的精度相差不大),大致流程如下:
-
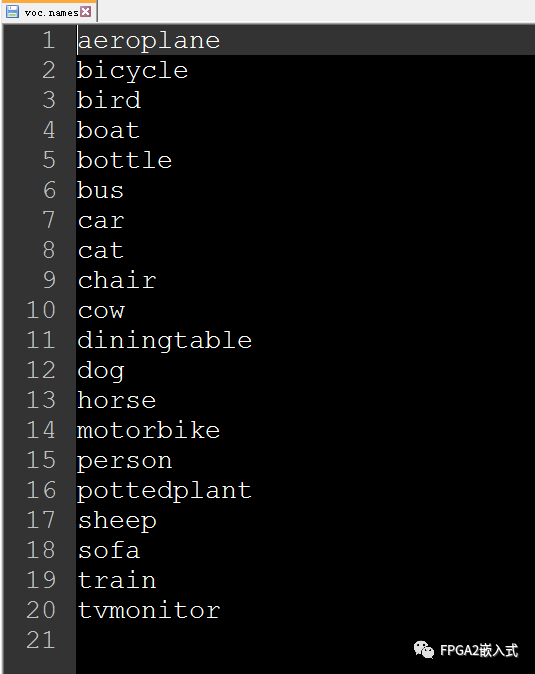
根据种类(如下图)选择数据集;
-
训练;
-
int8量化和再训练;
-
测试精度(如下图);
-
最终得到权重等参数。

03
模型RTL移植
yolo在pytorch处理后获得权重参数,然后根据权重等参数编写RTL代码,实现FPGA的本地推断,设计主要包括:
-
摄像头驱动,获取数据源;
-
源数据预处理,缩放到320*320;
-
自写DMA IP,处理源图、模型缓存、TFT显示;
-
自写DDR仲裁 IP,DDR加载十几个通道的权重参数时的仲裁处理;
-
AI模型算法RTL;
-
SDK下FLASH参数加载、AI模型算法控制等;
-
YOLO检测结果的NMS等RTL解析;
-
检测结果 + 源图像的叠加及TFT显示。
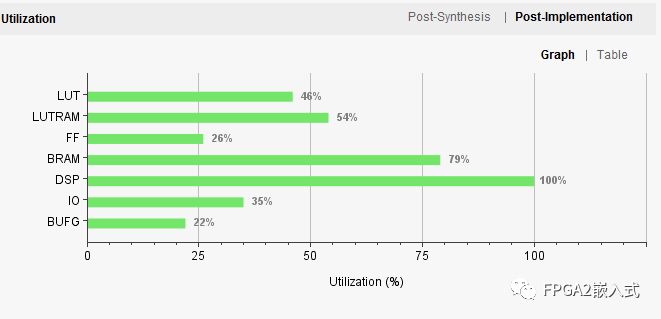
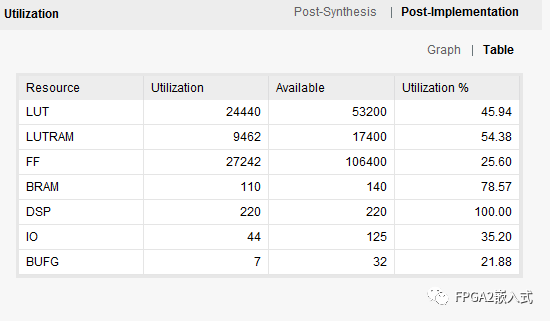
在zynq中,FPGA主频150MHz,达到AI速度320x320@15Hz,精度和上位机精度一致,zynq资源消耗及布局布线后时序如下:

04
模型RTL验证
对编写的RTL验证采用Python + bat脚本的自动化测试平台(只需修改TB,单击exe即可打印仿真结果来分析),保证FPGA仿真输出的模型各个层的结果与Pytorch量化后的输出结果完全一致:

05
上板测试及升级
在主频150MHz无时序报错情况下上板测试,解决了以下问题,最终达到和上位机一致的效果。
-
Sensr(30Hz)、AI(15Hz)、TFT(50Hz)不一致在未使用VDMA下出现显示分层,AI计算不对应的情况;
-
自定义DDR仲裁带宽计算考虑不当,导致加载权重等参数不对应的情况;
-
AI各层运算连接时,出现特征值不对应的情况。
后期升级可优化的空间:
-
主频改为200MHz;
-
AI模型用低bit量化,剪枝,压缩等算法;
-
RTL的资源进一步优化,减少资源为原来的50%甚至更少。

长按左侧关注 共同学习FPGA2嵌入式



















 1万+
1万+







 到【灌水乐园】发言
到【灌水乐园】发言







