




 随着大数据的发展,云上的机器学习平台成为趋势。本文对比了亚马逊的Amazon Machine Learning、微软Azure的机器学习平台、BigML和其他厂商如Databricks、Google、百度、阿里云和腾讯云的产品。AWS提供模型创建和预测,Azure采用流程图式编程,BigML注重易用性,其他平台各有特色。选择取决于需求,如Azure适合程序员和数据科学家,AWS和BigML适合快速预测,特定场景可选Google、百度或IBM Watson。
随着大数据的发展,云上的机器学习平台成为趋势。本文对比了亚马逊的Amazon Machine Learning、微软Azure的机器学习平台、BigML和其他厂商如Databricks、Google、百度、阿里云和腾讯云的产品。AWS提供模型创建和预测,Azure采用流程图式编程,BigML注重易用性,其他平台各有特色。选择取决于需求,如Azure适合程序员和数据科学家,AWS和BigML适合快速预测,特定场景可选Google、百度或IBM Watson。
随着大数据日新月异的飞速发展,机器学习也变的越来越性感。云和大数据是天生的一对,那么云上的机器学习又是什么样呢?我们今天就来看看几个基于云的机器学习平台:亚马逊,微软和bigml
亚马逊机器学习
我们先来看看云的领军人物亚马逊的机器学习平台 Amazon Machine Learning
首先,要是用亚马逊的机器学习,你需要有一个AWS的账号(废话)。在Analytics服务区域你会找到他的位置:

Machine Learning是AWS的一个相对比较新的功能,所以当前只有EU(爱尔兰)和美西(弗吉尼亚)两个domain支持。
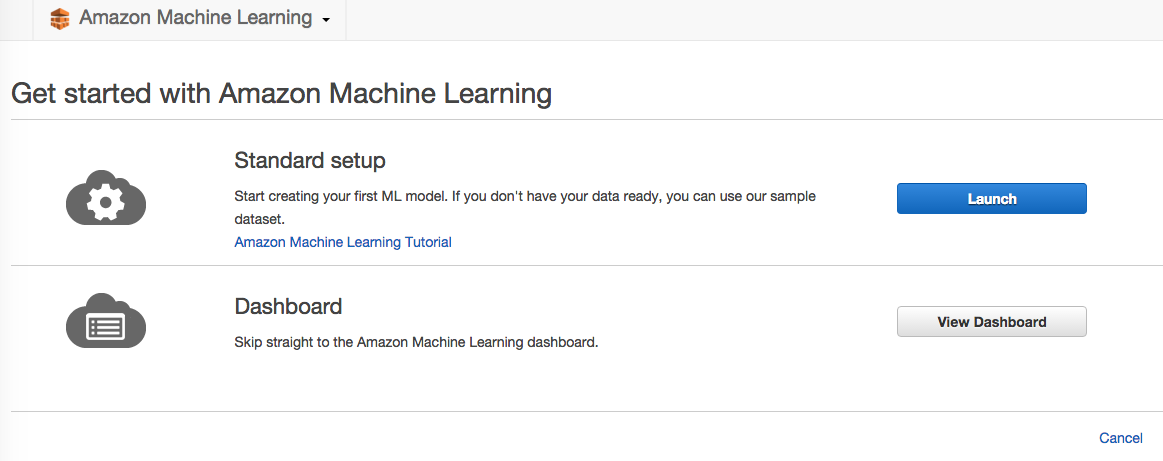
选择Launch启动机器学习,首先需要一个数据源。创建一个数据源分几步:
-
输入数据 input data
输入的数据源可以来自:用户可以使用S3上的一个csv文件或者来自Amazon Redshift数据库
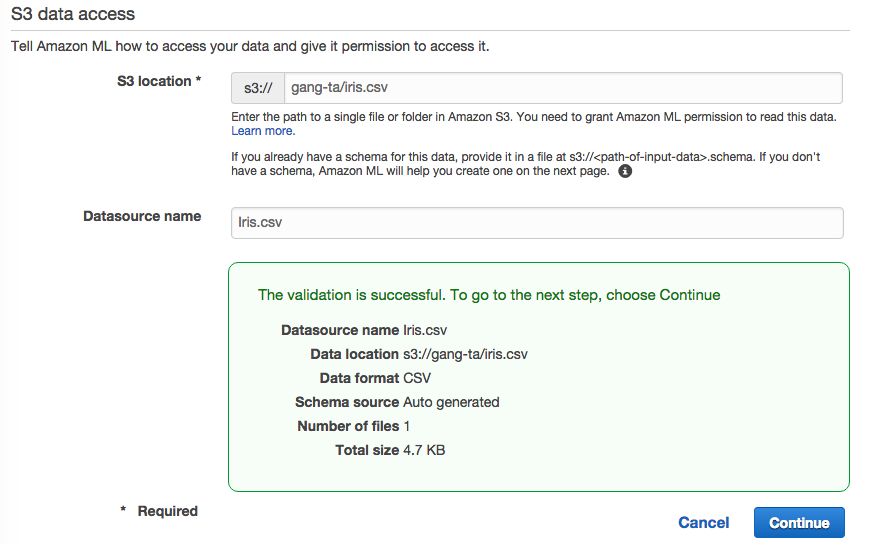
这里,我在我的S3上放了一个Iris的dataset,Verify后,数据就准备好了。
⚠ Iris Dataset 可能是最著名的数据集 (参见wikipedia的介绍),该数据集包含了三种鸢尾属植物(什么鬼?)的50个样本,该数据包涵植物的花瓣的萼片的长度和宽度的统计。
-
数据模式 schema
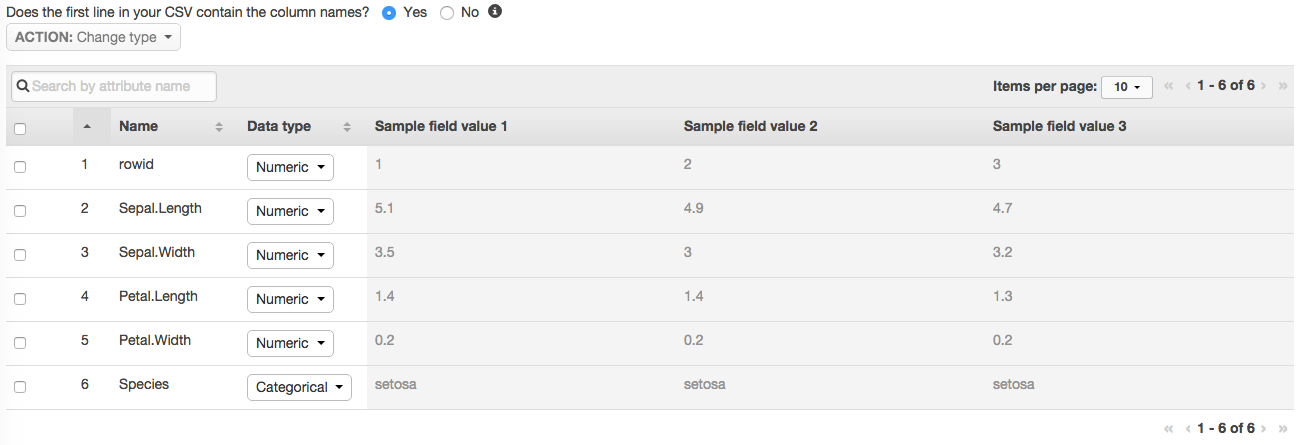
在schema这一步,选择CSV包含name column, (Does the first line in your CSV contain the column names? -> Yes) 结果如下:
-
目标 Target
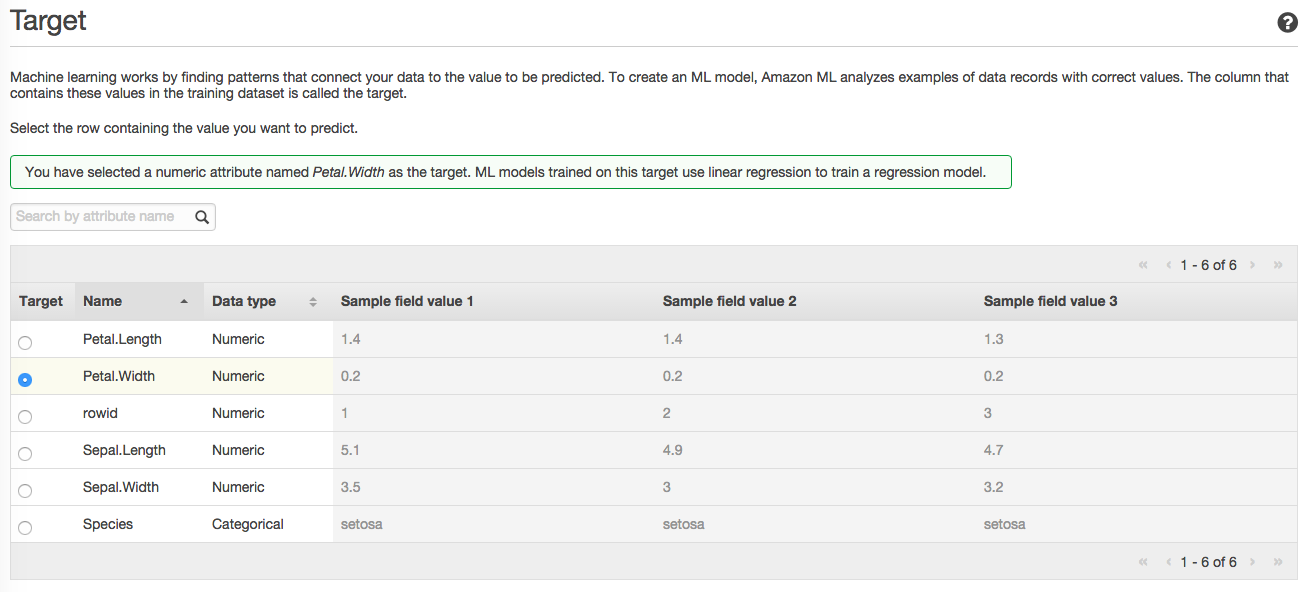
在Target这一步,选择一个要预测的目标。
如果选择了Species,AWS会选择创建一个分类模型 (multinomial logistic regression)

如果选择了长度或者宽度属性,AWS会选择创建一个回归模型 (线性回归)
-
Rowid
这一步用户可以选择一个rowid
-
review
review所有的数据源选项后,数据源就创建成功了
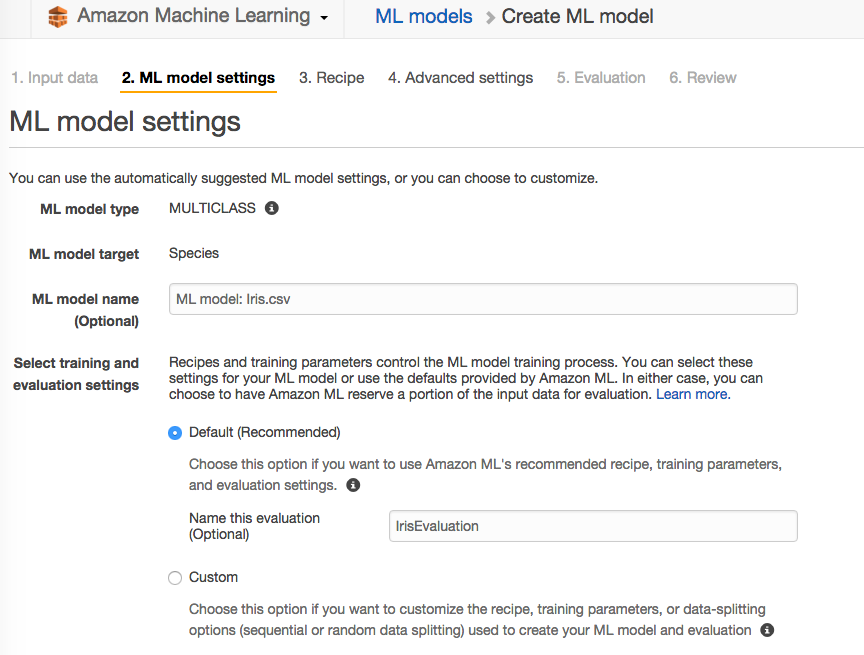
数据源创建成功后,可以对模型做一些设置。
这里可以选择缺省的设置。
设置好模型后,AWS会对该模型进行评估(evaluation),需要等一段时间看到结果。
我们不需要等待评估的结果,直接来进行预测。
为了省事,我们直接使用原始的Iris数据集进行预测(本文的目的只是为了感受在云上的机器学习,并非解决实际问题)
选择Batch Prediction
选择我们刚刚创建的模型:

选择Iris数据集来进行预测
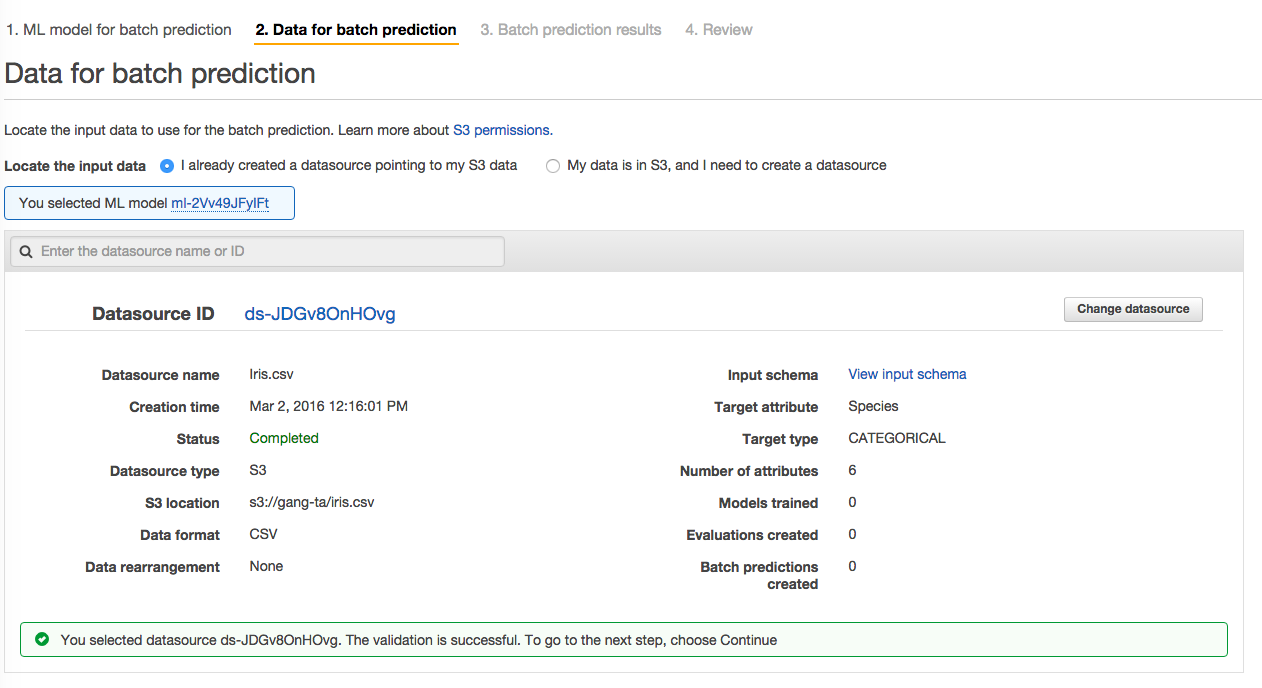
选择一个S3bucket的路径作为预测结果的存放,注意,确保机器学习的服务有对该目录的写权限。
注意,模型的创建是不收费的,但是预测是收费,这里AWS提示每1000个预测收费0.1美元。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









