




 这篇博客详细介绍了YOLO(You Only Look Once)目标检测算法,包括YOLOv1的基本思想、网络结构、损失函数,以及YOLOv2的改进,如使用anchor box、高分辨率分类、Batch Normalization等,揭示了YOLO系列如何提高检测速度和精度。
这篇博客详细介绍了YOLO(You Only Look Once)目标检测算法,包括YOLOv1的基本思想、网络结构、损失函数,以及YOLOv2的改进,如使用anchor box、高分辨率分类、Batch Normalization等,揭示了YOLO系列如何提高检测速度和精度。
YOLOV1
1、综述
Yolov1是CVPR2016的论文,Yolov1的网络速度很快,可以实时处理图片,达到45fps,还有一种改进的fast Yolo(减少了一些卷积层),可以达到155fps,精度也比较高,虽然会在定位上错误比较高,但是会在将背景预测为正样本的情况较少。主要的思想就是将一幅图片分成一个SxS grid,每个cell负责检测落在其中的gt框内容,那么只有当gt框的中心落在cell中,才算这个gt属于这个cell。且不像二阶段中有RPN阶段,Yolov1是直接输出最终得到的结果,结果维度为SxSx(B*5+C),其中SxS是cell的数量,B为每个cell中bbox的数量,C为类别数。在本轮文中使用的是C=20,B=2,S=7。
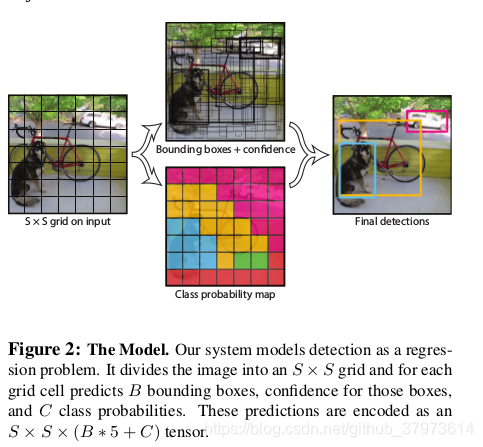
2、Details
首先,YOLOv1的网络是使用自己设计的darknet。使用的darknet网络最开始是在ImageNet上使用224x224(在进行目标检测的时候是448x448)的图进行预训练,预训练的任务是进行图像分类,大概训练了一周时间,在ImageNet 2012 validation set达到了top-5 accuracy 80%的效果,堪比GoogleNet的模型达到的效果。
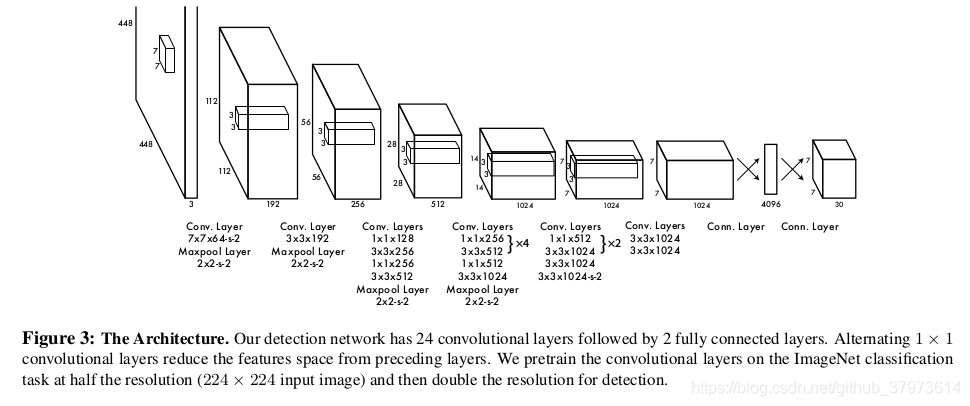 考虑到检测的任务需要细粒度的信息,所以将输入图片的分辨率由224x224变成448x448。最终的预测结果是7x7x(5x2+20),其中5是1 class probabilities+ 4 bbox coordinates。需要将bbox的宽和长归一化,即相对于image width and height的比例,取值范围在0-1,bbox的中心坐标x,y则是相对于cell左上坐标的偏移,也是一个0-1范围的值(见下面代码)。
考虑到检测的任务需要细粒度的信息,所以将输入图片的分辨率由224x224变成448x448。最终的预测结果是7x7x(5x2+20),其中5是1 class probabilities+ 4 bbox coordinates。需要将bbox的宽和长归一化,即相对于image width and height的比例,取值范围在0-1,bbox的中心坐标x,y则是相对于cell左上坐标的偏移,也是一个0-1范围的值(见下面代码)。
#如下是gt框计算loss需要的对应的值的过程
cellx = 1. * w / S
celly = 1. * h / S
for obj in allobj:
centerx = .5*(obj[1]+obj[3]) #xmin, xmax
centery = .5*(obj[2]+obj[4]) #ymin, ymax
cx = centerx / cellx
cy = centery / celly
# obj[1] is lttop_x, obj[2] is lttop_y, obj[3] is rigbot_x, obj[4] is rigbot_y
obj[3] = float(obj[3]-obj[1]) / w
obj[4] = flo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









