 特征金字塔网络与目标检测:多尺度融合与分而治之的权衡
特征金字塔网络与目标检测:多尺度融合与分而治之的权衡







 本文探讨了目标检测中特征金字塔网络(FPN)的有效性,通过实验对比表明,多尺度特征融合与分而治之对检测效果的影响。提出使用SiSo结构的encoder,结合DilatedEncoder和UniformMatching方法来优化检测性能。针对C5特征层的感受野限制和anchor分布不平衡问题,设计了LimitedScaleRange和ImbalanceProblemOnPositionAnchors解决方案。实验结果显示,所提方法在保持检测速度的同时提高了检测精度,特别是在大目标检测上。
本文探讨了目标检测中特征金字塔网络(FPN)的有效性,通过实验对比表明,多尺度特征融合与分而治之对检测效果的影响。提出使用SiSo结构的encoder,结合DilatedEncoder和UniformMatching方法来优化检测性能。针对C5特征层的感受野限制和anchor分布不平衡问题,设计了LimitedScaleRange和ImbalanceProblemOnPositionAnchors解决方案。实验结果显示,所提方法在保持检测速度的同时提高了检测精度,特别是在大目标检测上。
Motivation
目标检测中常用到特征金字塔(FPN),在各网络中证明FPN确实有效,通常认为其有效得益于两个方面:(1)多尺度特征融合:融合了多种高分辨率和低分辨率的特征获取到更好的特征表达;(2)分而治之:根据目标的大小在不同层进行目标检测。
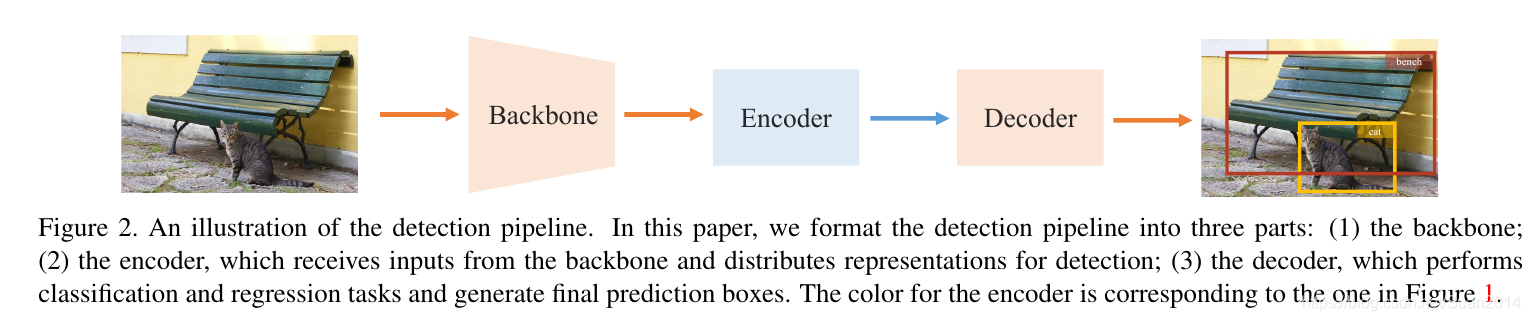
目标检测的网络结构可以分为三大部分:backbone、encoder、decoder,如下所示:
对encoder设计如下结构Figure 1进行实验,验证FPN的有效性是得益于多特征融合还是分而治之
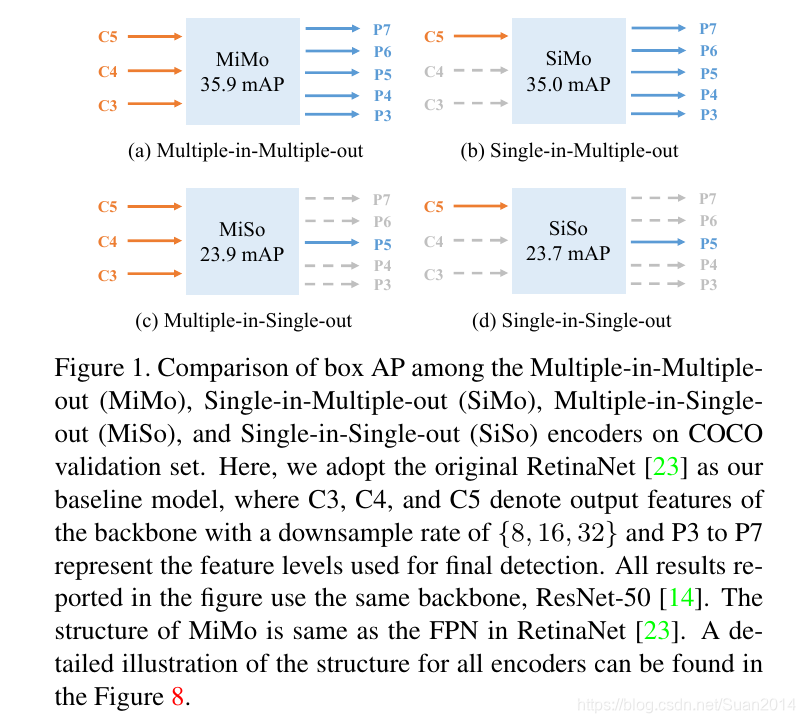
通过实验发现SiMo作为encoder,其输入只有C5特征层,并未进行特征融合,可以获得和MiMo相当的效果,而MiSo和SiSo作为encoder,检测效果大幅下降。这表明:1)C5特征层对于不同尺度的目标含有足够的上下文信息,因此SiMo作为encoder能获得不错的检测效果;2)分而治之的作用远超多尺度融合。
采用SiMo来进行分而治之的缺点是:计算量大,检测器运行速度慢。
因此,本文的encoder采用SiSo的结构作为encoder,但采用两种方式:Dilated Encoder(分而治之的思想)和Uniform Matching来提升SiSo作为encoder的检测效果。
本文算法
SiSo与MiMo相比,性能下降的两个主要原因是:1.C5的感受野是受限的,因此在不同尺寸目标上的检测性能下降;2.单层特征产生的sparse anchor会导致正负anchor的失衡。
Limited Scale Range(应对第一个感受野受限的问题)
SiSo输入为C5特征层,为产生不同的感受野,本文通过对常规卷积和空洞卷积进行stack来增大感受野,如图5所示,Resisual Blocks中的卷积采用不用dilationrate的空洞卷积,从而产生不同的感受野,以覆盖所有尺寸的目标。

Imabance Problem on Position Anchors(应对正负anchor失衡的问题)
SiSo相比于MiMo,anchor的数量会从100k将为5k,因此anchor比较sparse。几种不同的正anchor匹配方法基于单层特征产生的正anchor分布如下所示:
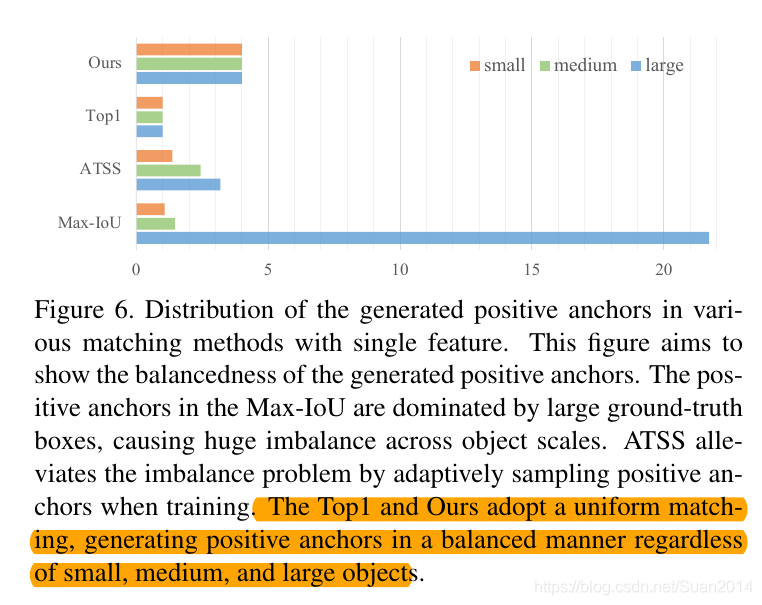
本文采用Uinform Matching:对于每个GT box,选取k个最近的anchor(k nearest)作为正anchor,这样所有的GT box不论尺寸大小都有相同数据的正anchor;此外本文还依据Max-IoU匹配的原则,在Uniform Matching时,设定IoU阈值以去除大IoU(>0.7)的负anchor和小IoU(<0.15)的正anchor。
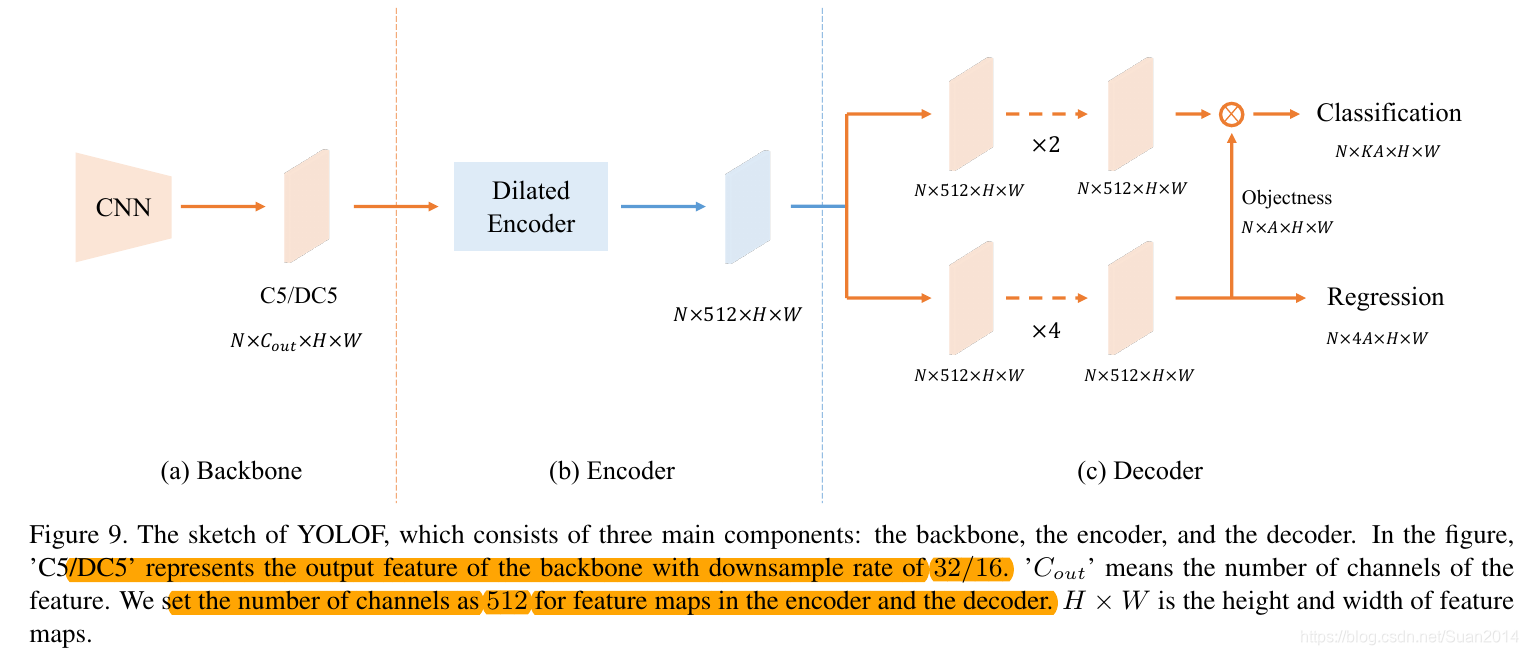
整体网络结构
实验
和其他算法相比
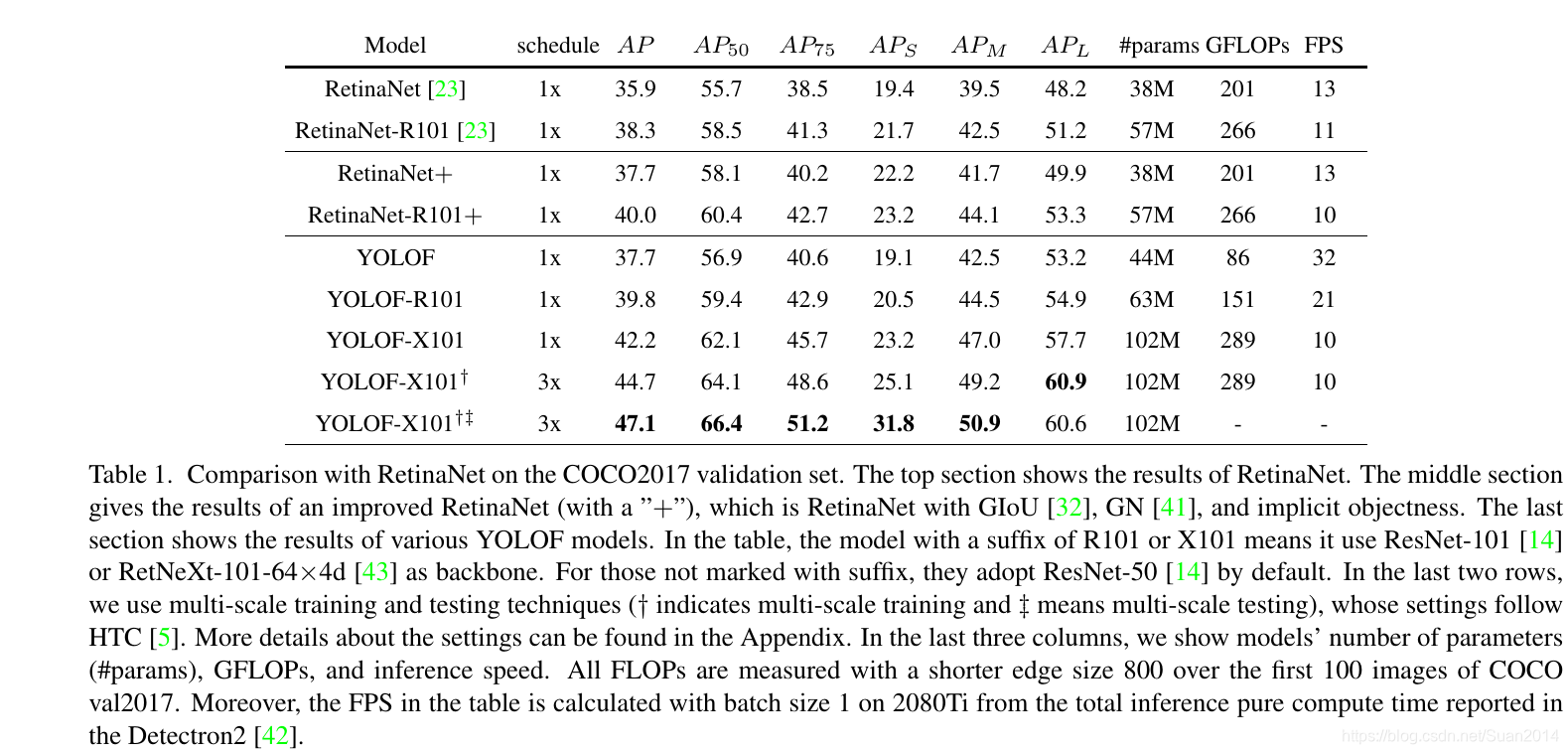
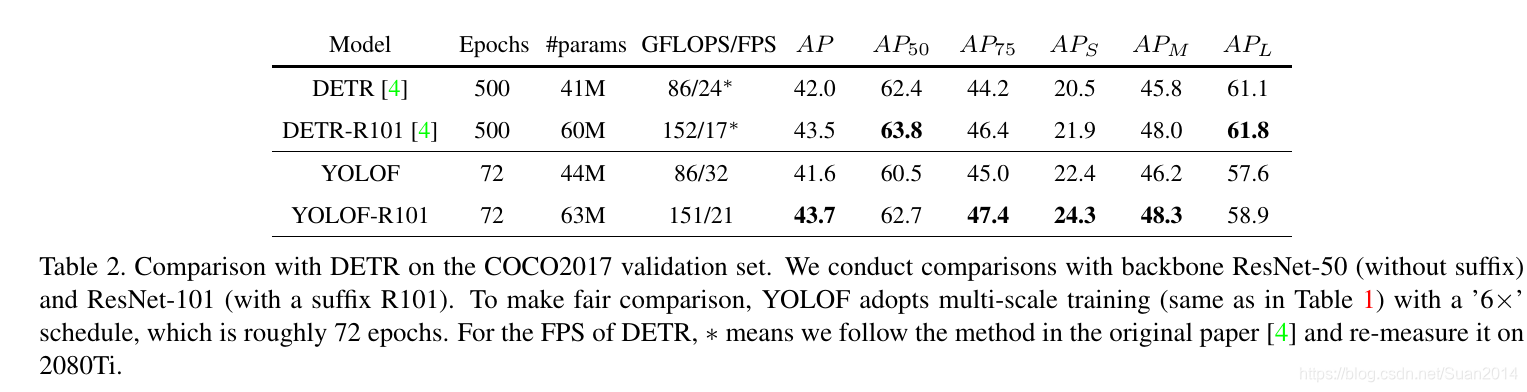

整体表现:速度快、效果好
消融实验
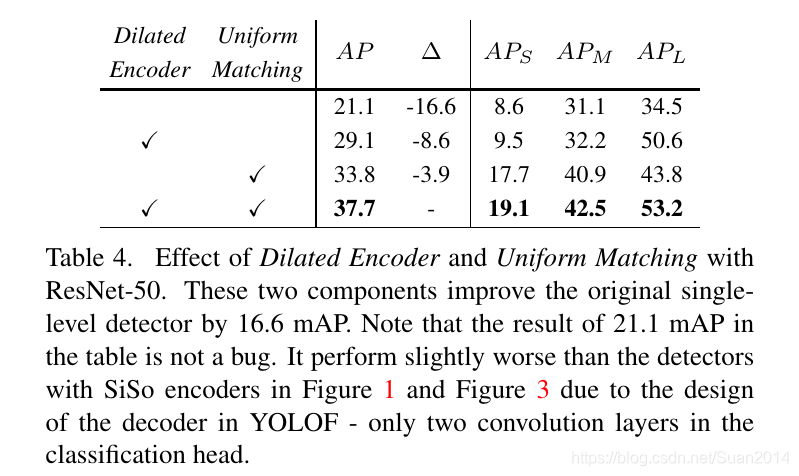
Dialated Encoder和Uniform Matching都有着重要作用
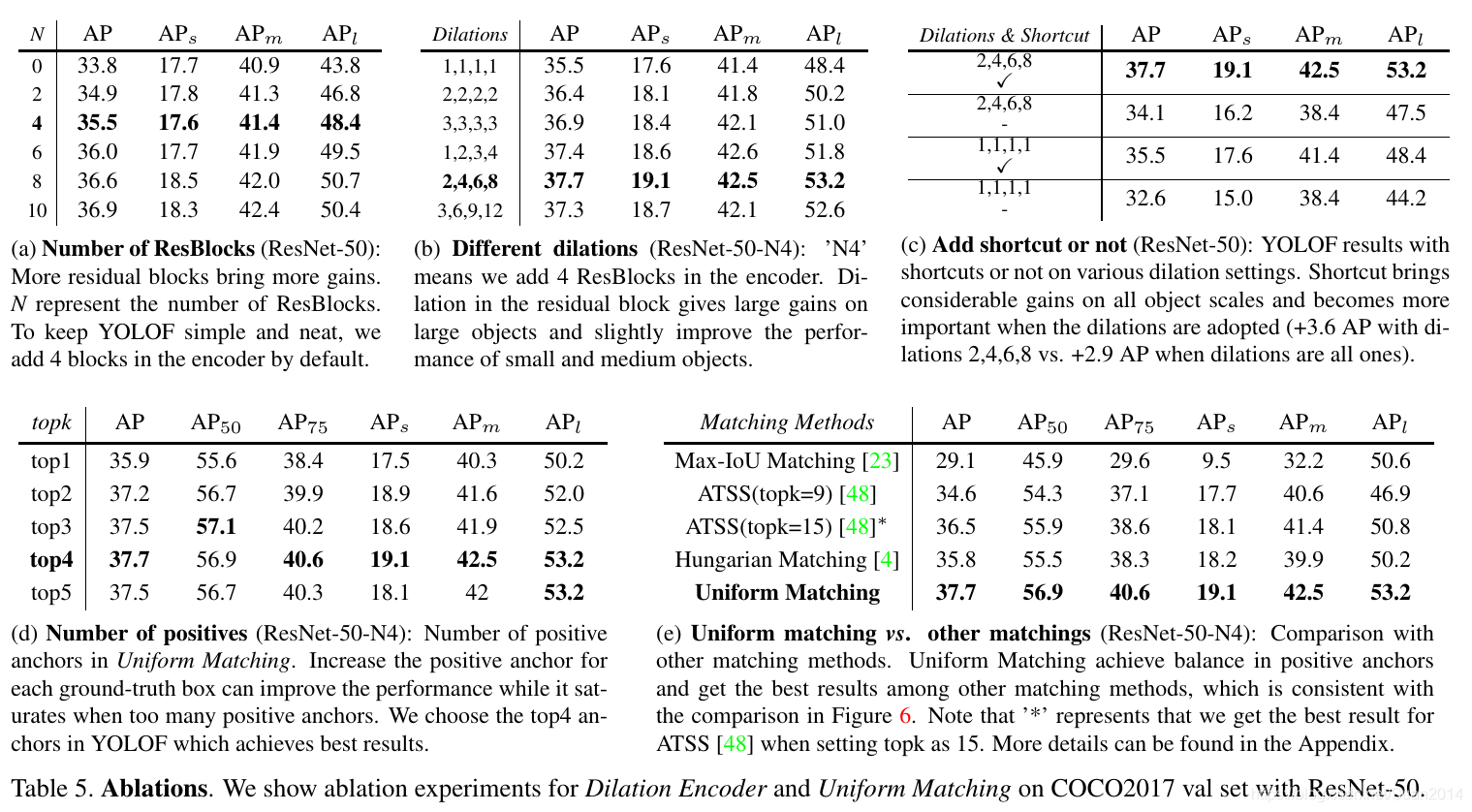
- 上图(a)表明残差block取4最优;
- 上图(a)表明4个残差block中空洞卷积取2,4,6,8的dialation rate最优;
- 上图©表明残差块中需要shortcut;
- 上图(d)表明Uniform Matching时,取k=4最优;
- 上图(e)表明Uniform Matching方式最优。
思考
- Uniform Matching可以解决部分小目标检测的问题;
- 采用空洞卷积来扩大感受野对大目标有效(文中大目标AP提升多),但对小目标效果有限,如何进一步提升小目标检测?


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











