






 FCN开创了深度学习在图像语义分割领域的先河,通过全卷积网络和端到端训练,显著提升了分割精度,达62.2%meanIU。该文对比了多种传统方法,如patchwise训练和条件随机场,突出了FCN无需预处理和后处理的优势。
FCN开创了深度学习在图像语义分割领域的先河,通过全卷积网络和端到端训练,显著提升了分割精度,达62.2%meanIU。该文对比了多种传统方法,如patchwise训练和条件随机场,突出了FCN无需预处理和后处理的优势。

CVPR2015
FCN是一篇整体思想比较简单的论文,但是其训练的方法有许多的尝试,FCN可以说是深度学习引入语义分割的开山之作,文章主要强调了两个点:1、全卷积网络(FCN);2、端到端的学习(trained end-to-end)。
概述
- 解决什么问题?
使用深度学习来解决图像分割的问题 - 使用的方法?
- 使用了图像分类的模型(Alex,VGG, Googlenet等)来迁移学习到分割任务上
- 使用转置卷积来做upsample
- 使用skip layer提高精度
- result
- 在VOC的数据集上,mean IU达到了62.2%,比之前的最优方法提高了20个百分点。
- 每张图片的处理时间只有0.2s。
- 还存在的问题
- 本文是深度学习解决图像语义分割的开山之作,提出了一种新的思路,效果是当时很好。
- 对细节不敏感,对像素的分类未考虑像素与像素之间的关系,忽略了在通常的基于像素分割方法中的空间规整步骤。(这个地方应该知道是像在分割之后接条件随机场之类的操作来对像素之间的关系进行进一步的处理的步骤)
其实因为在此之前大多是传统的方法,且没有很熟悉之前的方法是如何去做到,文中也提到了一些使用卷积网络来做语义分割任务的方法,但是目前还没有仔细看,所以不方法进行对比,这样的话,对于从2018、2017论文看过来的,就有点不太适应,很难get到此论文的一些想法在当时意味着什么。因为其中的许多做法在我们现在看来都是比较熟悉的,反倒是他之前的一些传统方法,看起来比较陌生。
细节部分
1、Introduction
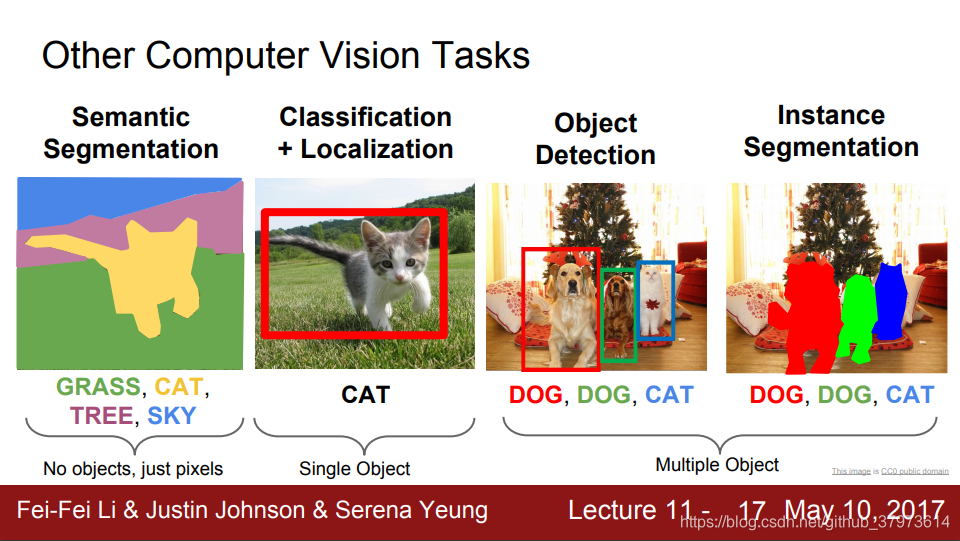
这里先介绍一些概念,参考自知乎用户/link,以下是分割检测分类的概念图示。分割任务确实是做的像素级别的分类,分割任务也属于Dense prediction任务。
end-to-end:文中对FCN是end-to-end多次强调,如我们现在的网络,R-CNN不是end-to-end,因为需要使用selective search来单独进行region proposal,faster rcnn和yolo是end-to-end的。
- 因为是一篇可以说是承前启后的文章,所以introduction的对比论文还是挺多的:
- 因为卷积网络在分类器的训练上取得了很好的效果,自然而然,将其“迁移”到像素级的预测将是下一步需要做的。这里提到了一些早些时候使用卷积网络来做语义分割的论文[27, 2, 8, 28, 16, 14, 11],这里可以做一个对比,在文章最后会慢慢进行对比。
- 以前有使用patchwise training这种方法进行训练的,还比较常见,但是这种方法相对于全卷积来说,缺乏效率。而且全卷积网络无需一些预处理和后处理的操作,如:超像素,proposals,post-hoc refinement by random fields or local classifier。
- 这里还有提及:previous works have applied small convnets without supervised pre-training。即以前的工作没有使用迁移学习而是选择直接在数据集上重新开始训练模型。
- Semantic segmentation faces an inherent tension between semantics and location: global information resolves what while local information resolves where
2、Related work
- 使用卷积网络来实现任意化的输入
- 论文1-1991,继承了LeNet网络来识别字符(这个是一个数字串的切割成单独的数字后再进行识别的任务,输入限定再一维的输入串,即如12345,而不能是分布在整个二维平面各处的数字)。

- 论文2-1994,这篇论文是是一个邮件地址部位识别模块的设计,也是使用了卷积网络,要实现这个邮件地址模块识别系统,论文2中,传统 的一般分为两个步骤:首先从image中提取墨迹特征,其次,通过几百条的规则去找出地址块的候选。论文2的实现是,使用卷积神经网络来找出bbox。

- 论文3-2005,这篇论文是在进行基因测试的背景下,进行细胞的演变的观察,主要需要观察的部分有细胞核,核膜,细胞质,细胞壁和外部培养基五个类,做法是将其中的每个像素都进行类别标注。然后使用卷积网络来进行处理(对每个像素进行分类,后期局部一致性处理)。
- 论文1-1991,继承了LeNet网络来识别字符(这个是一个数字串的切割成单独的数字后再进行识别的任务,输入限定再一维的输入串,即如12345,而不能是分布在整个二维平面各处的数字)。
- 利用全卷积计算
- overfeat-2014,也利用了Fully convolutional network来进行滑动窗口的检测任务。论文的全名就是:Integrated Recognition, Localization and Detection using Convolutional Networks,表明就是使用全卷积网络来整合这些任务。
- 论文5-2014,提出的循环卷积网络,对一个场景中的每个像素进行标注分类,同时,要对每个像素的局部信息进行关注,端到端的进行训练。
有许多的局部分类器的方法来处理这个问题,一般对像素局部关联性信息进行处理,会使用条件随机场或者马尔可夫随机场,这些方法通常包括将图像分割成超像素或片段区域以确保标记的可见一致性,并且还考虑相邻片段之间的相似性。每个片段都会包含一连串的特征输入(input feature),和描述相邻片段的标签空间相关性的上下文特征(contextual features describing spatial relation between the label of neighbor segments),分类器则根据给定的特征来进行最大可能性的预测分类。
此论文就与上述的方法相比,就是 (i)无需设计特征(engineered features),(ii)the prediction phase does not rely on any label space searching, since it requires only the forward evaluation of a function. 这里的第二点应该是指的不用考虑相邻的像素的空间相关性了吧? - 论文6-2013,这是做图像恢复的一篇论文,对于透过一个带泥或雨水的窗而得到的图片进行除泥除水的过程。采集数据的时候是成对采集,一幅带噪声的(dirt & rain drops), 一幅是不带噪声的。

- 论文7-2014, to learn an end-to-end part detector and spatial model for pose estimation.
- 此外
- Sppnet-2014,这个网络是不能end-to-end训练。这个网络的一些小tips。
- Dense prediction
- 一些使用了卷积网络来进行Dense prediction任务的,许多论文里,将分割任务作为Dense prediction任务。包括有论文3-2005(,基因测试中细胞变化的检测),论文9-2013(,基于深度学习的场景解析系统,需要对每个像素进行分类,传统是先利用graph-based的方法获得分割假设,之后对得到的分割候选区域使用手动设置的特征进行编码,最后使用条件随机场or一些其他的图形模型对区域产生标签。过程如下图所示)。还有论文5-2014。
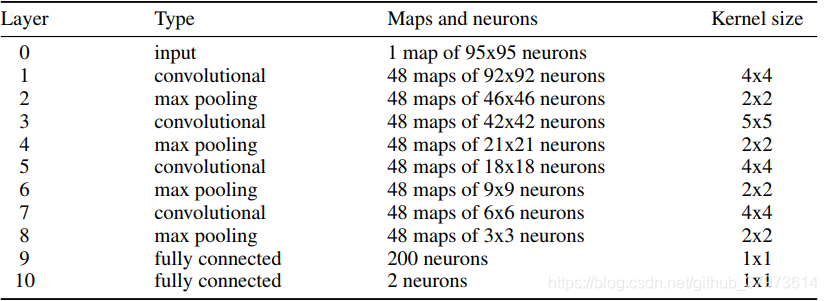
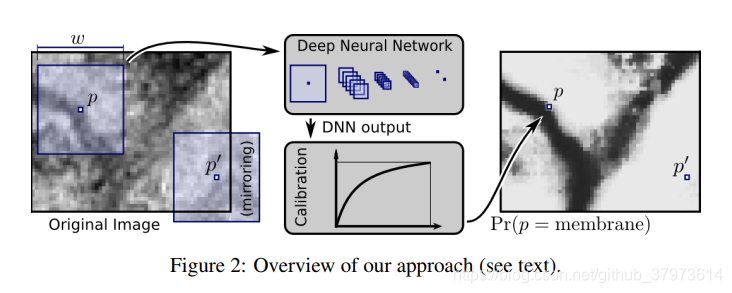
论文10-2012,是对大脑的神经原膜处的像素进行分类的操作。下面是网络结构。其实就很简单,是使用了卷积网络作为特征提取,以及池化的下采样,但是效果据并不是很出色。
- 一些使用了卷积网络来进行Dense prediction任务的,许多论文里,将分割任务作为Dense prediction任务。包括有论文3-2005(,基因测试中细胞变化的检测),论文9-2013(,基于深度学习的场景解析系统,需要对每个像素进行分类,传统是先利用graph-based的方法获得分割假设,之后对得到的分割候选区域使用手动设置的特征进行编码,最后使用条件随机场or一些其他的图形模型对区域产生标签。过程如下图所示)。还有论文5-2014。
- summary,上面的方法大多包含以下elements:
- 模型特别小
- patchwise training
- 使用superpixel projection,random field regularization、filtering or local classification来进行后期处理。
- overfeat的input shifting and output interlacing for dense output.
- 多尺度的处理(有些是直接对原图进行缩放)
- tanh
- ensembles
不同于之前存在的方法,FCN网络是采用分类网络的结构再采用微调的策略。也有论文11-([SDS]Simultaneous Detection and Segmentation),SDS如下图;论文12( Learning rich features from RGB-D images for object detection and segmentation)是采用这样的策略去做分割的,但是通常都是do so in hybrid proposal-calssifer models(对RCNN进行finetune)。(sample bounding boxes and/or region proposals for detection,semantic segmentation and instance segmentation)。都没有达到end-to-end学习。
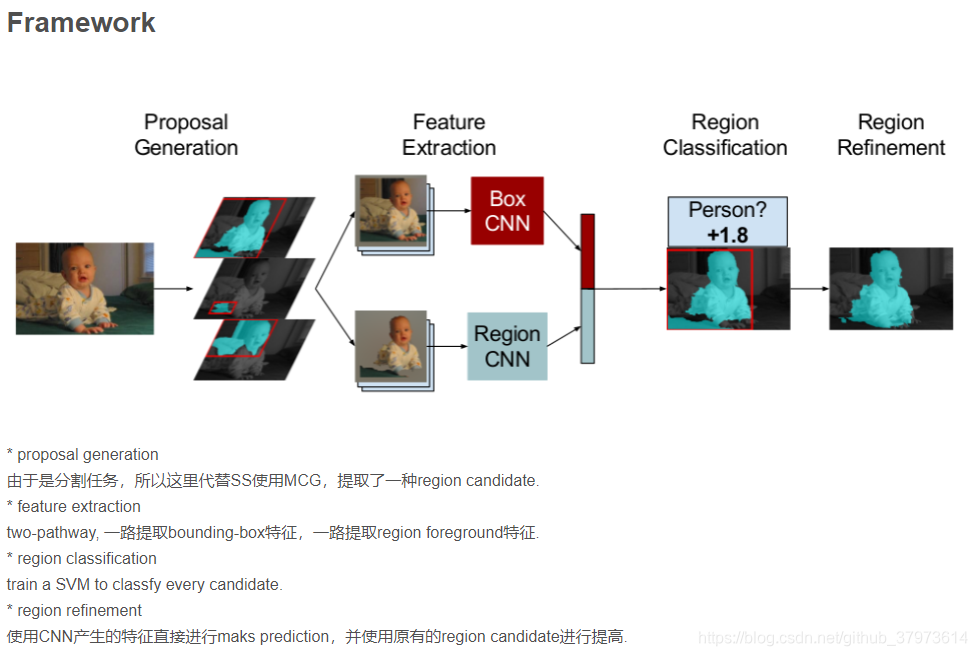
paper特别强调了,上述的方法在pascal、NYUDv2分割上取得最好的效果。所以本paper就直接与他们的效果做比较。强调本paper使用了standalone,end-to-end FCN。
3、网络结构
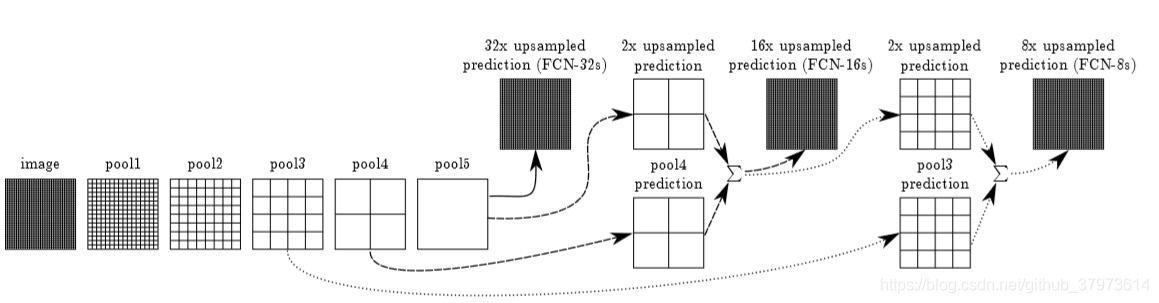
效果:以下是分别对应在上面网络结构的三个地方的输出的直观效果和结果评估对比。
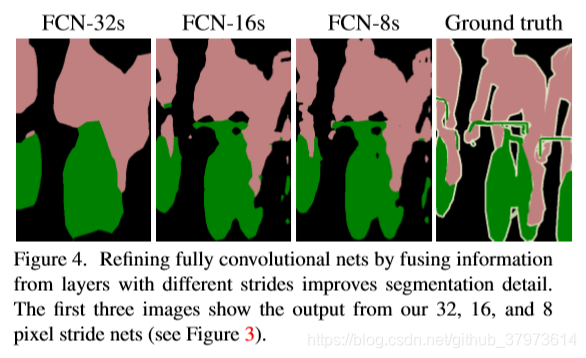
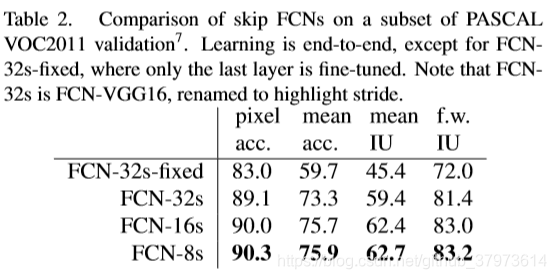
4、分割的评价指标

实际上mean IU这个指标不是很好,在paper的附录中有验证。
结果

数据集
NYUDv2:是一个RGB-D的数据集,使用Microsoft Kinect来进行收集的,共有1449幅带有像素级标签(40个类别)的RGB-D的图像,795 training images & 654 testing images。
SIFT Flow:图像语义分割与几何语义分割数据集。共2688幅,33个像素级标签类别,三个几何类别(‘horizontal’, ‘vertical’, ‘sky’),FCN可以对两种类别的标签都可以进行预测。2488 trainging images & 200 testing images。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









