




 本文详细介绍了Linux线程的基本概念,包括线程与进程的区别、线程的创建与退出,以及线程同步的重要性。通过示例代码展示了如何使用pthread库创建、退出、分离和连接线程,并探讨了线程同步的必要性,如互斥量、读写锁、条件变量和信号量的应用,以解决并发访问共享资源时可能出现的问题。此外,还讨论了死锁的概念及避免策略,以及生产者消费者模型在多线程环境中的实现。
本文详细介绍了Linux线程的基本概念,包括线程与进程的区别、线程的创建与退出,以及线程同步的重要性。通过示例代码展示了如何使用pthread库创建、退出、分离和连接线程,并探讨了线程同步的必要性,如互斥量、读写锁、条件变量和信号量的应用,以解决并发访问共享资源时可能出现的问题。此外,还讨论了死锁的概念及避免策略,以及生产者消费者模型在多线程环境中的实现。
1.线程
1.1 线程的基本概念
1.1.1 线程的定义
1.线程的基本概念
线程概念(process):线程是进程的⼀个实体,也是 CPU 调度和分派的基本单位,它是⽐进程更⼩的能独⽴运⾏的基本单位,是一种轻量级的进程。
同一程序中的所有线程会独立的执行相同的程序,共享一份内存区域(数据段,未初始化的数据段,堆内存段)。
2.Linux 指令查看当前线程
查看某个进程开启的所有线程
ps -Lf pid
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ANK2MIVW-1644492844290)(https://gitee.com/xuboluo/images/raw/master/img/202202052334053.png)]
1.1.2 线程和进程的区别
1.为什么使用线程而不是进程
(1)进程间的信息难以共享(写时拷贝)。除了只读代码段外,父子进程并未共享内存,所以就要采用一些进程间的通信方式进行进程间的通信。
线程能够方便快捷的共享信息,只需要将数据复制到全局或者堆变量即可
(2)创建进程消耗的内存更大。使用 fork 方法创建进程的开销比较大,虽然有写时拷贝技术,但是还是需要拷贝内存页表还有文件描述符等 PCB 的一些内容
线程之间共享开辟他的进程的那个虚拟地址空间,无需采用写时拷贝来赋值内存,也就是不用赋值内存表还有页表。所以创建线程的速度是进程的10倍以上
(3)进程同一时间只能做一件事。如果中间发生阻塞了,那他就被挂起了。但是线程的话是并发执行的,不同的线程可以干不同的活。比如一个线程访问服务器,一个线层显示访问进度条
进程和线程如何共享内存:
线程和进程使用同一块虚拟内存,只不过会将虚拟内存的栈空间分成一块一块的,不同的线程调用不同的栈空间。但是堆空间是共享的

1.1.3 进程和线程共享和不共享的资源

2.子线程的相关函数

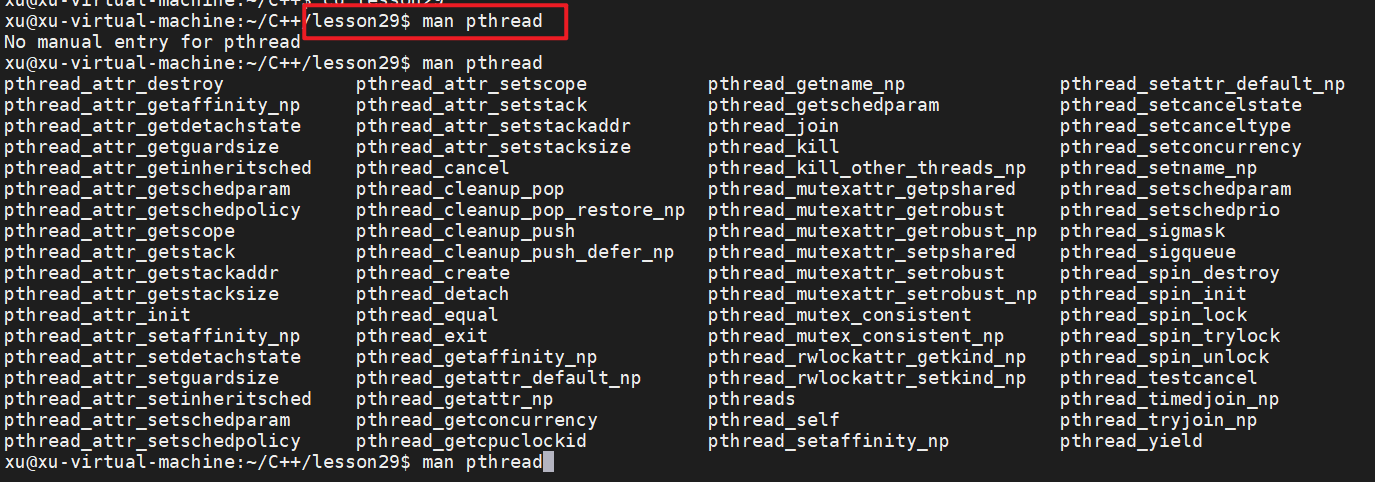
如何查看相关的方法
man pthread +Tab // 后面就会显示所有与之相关的方法
2.1 pthread_create—线程创建函数
代码保存在 lesson29 pthread_creat.c
1.API

库工程
#include <pthread.h>
这里的 arg 参数其实最终传给了 start_routine 方法当中
最后返回的错误也不太一样,他返回的是一个 string 类型的错误,使用方法如下:
if(ret!=0){
char* errstr = strerror(ret);
printf("error:%s\n",errstr);
}
2.代码
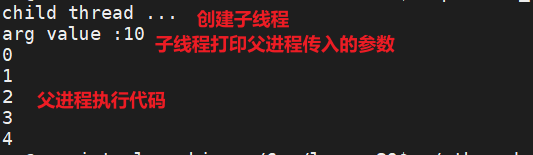
父进程创建一个子线程,并在子线程的回调函数中进行相应的处理操作。父线程也会在自己的方法中进行相应的操作
#include <pthread.h>
#include <string.h>
#include <unistd.h>
void* callback(void *arg){
printf("child thread ...\n");
printf("arg value :%d\n",*(int *)arg);
return NULL;
}
int main(){
pthread_t tid;
int num = 10;
// 创建一个子线程
int ret = pthread_create(&tid,NULL,callback,(void*)&num); // 在这一步会对 pthread_id 进行赋值
// 子线程创建判错
if(ret!=0){
char* errstr = strerror(ret);
printf("error:%s\n",errstr);
}
// 主线程执行
for(int i =0;i<5;i++) printf("%d\n",i);
sleep(1);
return 0;
}
3.代码演示
根据 API 可以看到这里需要连接 pthread 这个库,所以编译时的代码如下
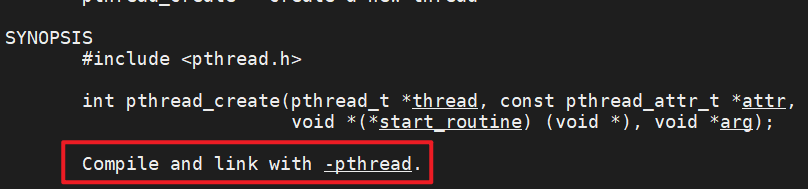
gcc pthread_create.c -o pthread_create -pthread
2.2 pthread_exit—进程退出函数,pthread_self()—查看线程 id
在哪里调用这个函数,这个函数就会在哪个线程中退出,如果是在主线程中调用,主线程退出,但是不会释放资源,子线程依旧正常执行
主线程退出后主线程中的剩余代码不会再执行
1.关键代码
pthread_exit(NULL); // 退出当前线程
pthread_self(); // 查看当前线程 id
2.代码演示
2.3 pthread_join—和已经终止的线程进行连接
代码放在 lesson29 pthread_join.c
1.API

这个函数是阻塞的,会将主线程阻塞住
2.代码
创建一个子线程,运行结束时向父进程反传值
关键代码:
子线程在结束时在 callback 函数向父线程传值
pthread_exit((void *)&value);
父线程使用双指针接收子线程传来的值
// 主线程调用 pthread_join() 回收子线程的资源
int * thread_retrval; // 创建一个指针
ret = pthread_join(tid,(void**)&thread_retrval); // 创建指针的指针
#include <stdio.h>
#include <pthread.h>
#include <string.h>
#include <unistd.h>
int value = 10; // 因为子线程被销毁后子线程的空间会被销毁,所以将这个变量定义在全局
void* callback(void *arg){
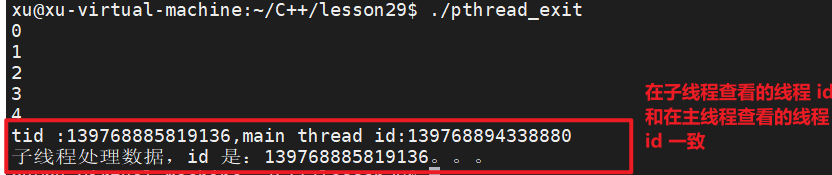
printf("child thread:%ld\n",pthread_self());
pthread_exit((void *)&value); // 线层结束时将值传入
return NULL;
}
int main(){
pthread_t tid;
int num = 10;
// 创建一个子线程
int ret = pthread_create(&tid,NULL,callback,(void*)&num);
// 子线程创建判错
if(ret!=0){
char* errstr = strerror(ret);
printf("error:%s\n",errstr);
}
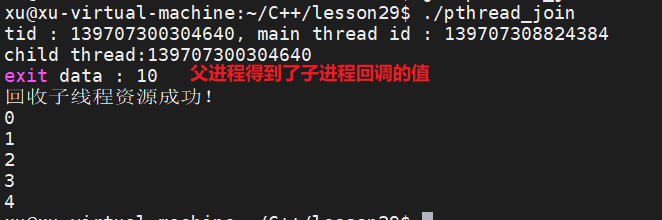
printf("tid : %ld, main thread id : %ld\n", tid ,pthread_self());
// 主线程调用 pthread_join() 回收子线程的资源
int * thread_retrval;
ret = pthread_join(tid,(void**)&thread_retrval);
printf("exit data : %d\n", *thread_retrval);
printf("回收子线程资源成功!\n");
// 让主线程退出,当主线程退出时,不会影响其他正常运行的线程。
// pthread_exit(NULL);"")"")
// 主线程执行
for(int i =0;i<5;i++) printf("%d\n",i);
sleep(1);
return 0;
}
为什么在线程结束进行通信时需要传入二级指针:
因为以往传入函数的参数都是形参,没有办法改变变量原先的值。但是如果传入的是指针就可以改变原先的值。
因为这里本来想要传入一个指针,与此同时又想改变其中的值,所以需要传入指针的指针
3.代码实现
2.4pthread_detach—线程分离
代码放在 lesson29 detach .c
1.API
#include <pthread.h>
/**
* 使调⽤线程与当前进程分离,分离后不代表此线程不依赖与当前进程,
* 线程分离的⽬的是将线程资源的回收⼯作交由系统⾃动来完成,
* 也就是说当被分离的线程结束之后,系统会⾃动回收它的资源。所以,此函数不会阻塞. *
* @param thread 线程号.
* @return 成功: 0; 失败: ⾮0.
*/
int pthread_detach(pthread_t thread);
分离的作用:
在我们使用默认属性创建一个线程的时候,线程是 joinable 的。 joinable 状态的线程,必须在另一个线程中使用 pthread_join() 等待其结束, 如果一个 joinable 的线程在结束后,没有使用 pthread_join() 进行操作, 这个线程就会变成"僵尸线程"。每个僵尸线程都会消耗一些系统资源, 当有太多的僵尸线程的时候,可能会导致创建线程失败。
当线程被设置为分离状态后,线程结束时,它的资源会被系统自动的回收, 而不再需要在其它线程中对其进行 pthread_join() 操作,这样主线程就不会被阻塞住
分离之后是不能进行 join 操作的
2.代码
实现使用 detach 的方法将子线程和主线程分离,然后再通过 join 连接
关键代码:将主线程和子线程分离,并使用 join 方法连接
// 主线程和子线程分离
ret = pthread_detach(tid);
if(ret!=0){
char *s = strerror(ret);
printf("error2:%s\n",s);
}
// 分离后再次调用 join 操作
ret = pthread_join(tid,NULL);
if(ret!=0){
char *s = strerror(ret);
printf("error3:%s\n",s);
}
3.代码演示
最后可以看到使用 join 方法连接时最后会报错,因为不能使用 join 连接,也就是 error3

2.5 pthread_cancel—线程取消(中止)
代码放在 lesson29 pthread_cancel.c
1.API

使用了中止线程的代码后并不会立刻中止,而是在某个取消点中止
2.代码
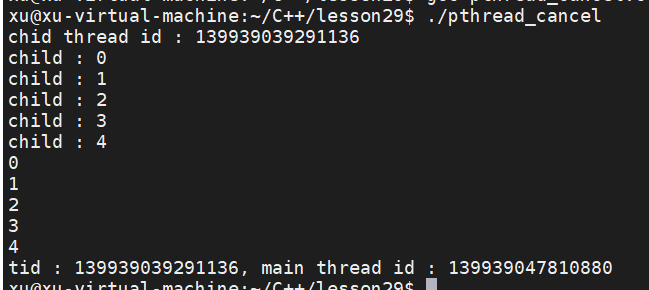
pthread_cancel(tid); // 中止线程
3.代码演示
2.6 线程属性
1.API
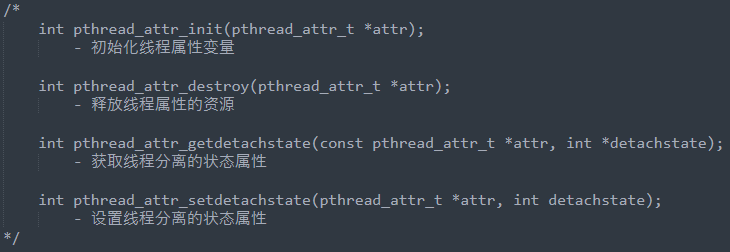
查看 Linux 中的线程属性
man pthread_attr_ // 按两次 Tab 键
2.代码
Step1:初始化属性变量
// 创建一个线程属性变量
pthread_attr_t attr;
// 初始化属性变量
pthread_attr_init(&attr);
Step2:设置属性 (设置线程分离的属性)
// 设置属性
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
Step3:创建子线程时传入属性
int ret = pthread_create(&tid, &attr, callback, NULL);
Step4:获得线程栈的大小
// 获取线程的栈的大小
size_t size;
pthread_attr_getstacksize(&attr, &size);
printf("thread stack size : %ld\n", size);
Step5:释放线程属性资源(别忘了最后的销毁操作)
pthread_attr_destroy(&attr);
3.代码演示
进行 detach 操作,查看栈的大小
重点:3. 线程同步
3.1 线程同步的基本概念
3.1 .1 为什么需要线程同步
代码放在 lesson30 selltickets.c
三个线层同时对 100 张票(某个变量)进行 减减 操作,这个时候会出现两个问题:1.输出剩余的票最后变成了负数2.一共100张票,线程 A 和 线程 B 可能会同时卖出第 90 张票
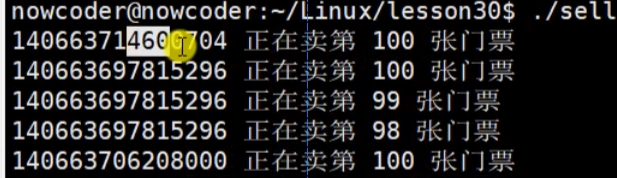


(感觉上图线程同步和异步说反了)
造成原因:线程可以通过全局变量共享信息,这就导致多个线层会同时修改同一变量
原子操作:不可以被分割,也就是说这个变量在一个线程访问时另一个线程就不能访问
3.1.2 锁的种类
1.读写锁
多个读者可以同时进⾏读
写者必须互斥(只允许⼀个写者写,也不能读者写者同时进⾏)
写者优先于读者(⼀旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
2.互斥锁(量)
为避免线程更新共享变量时出现问题,可以使用互斥量(mutex 是mutual exclusion 的缩写)来确保同时仅有一个线程可以访问某项共享资源。可以使用互斥量来保证对任意共享资源的原子访问。
互斥量有两种状态:已锁定(locked) 和未锁定(unlocked) 。任何时候,至多只有一个线程可以锁定该互斥量。试图对已经锁定的某一互斥量再次加锁, 将可能阻塞线程或者报错失败,具体取决于加锁时使用的方法。
一旦线程锁定互斥量,随即成为该互斥量的所有者,只有所有者才能给互斥量解锁。
3.条件变量
条件变量是另外一种同步机制,可以用于线程和管程中的进程互斥。通常与互斥量一起使用。
条件变量允许线程由于一些暂时没有达到的条件而阻塞。通常,等待另一个线程完成该线程所需要的条件。条件达到时,另外一个线程发送一个信号,唤醒该线程。
条件变量对应的一组操作是pthread_cond_wait和pthread_cond_signal。
条件变量与互斥量一起使用,一般情况是:一个线程锁住一个互斥量,然后当它不能获得它期待的结果时,等待一个条件变量;最后另外一个线程向它发送信号,使得它可以继续执行。
4.自旋锁
如果进线程⽆法取得锁,进线程不会⽴刻放弃CPU时间⽚,⽽是⼀直循环尝试获取锁,直到获取为⽌。如果别的线
程⻓时期占有锁,那么⾃旋就是在浪费CPU做⽆⽤功,但是⾃旋锁⼀般应⽤于加锁时间很短的场景,这个时候效率
⽐较⾼。
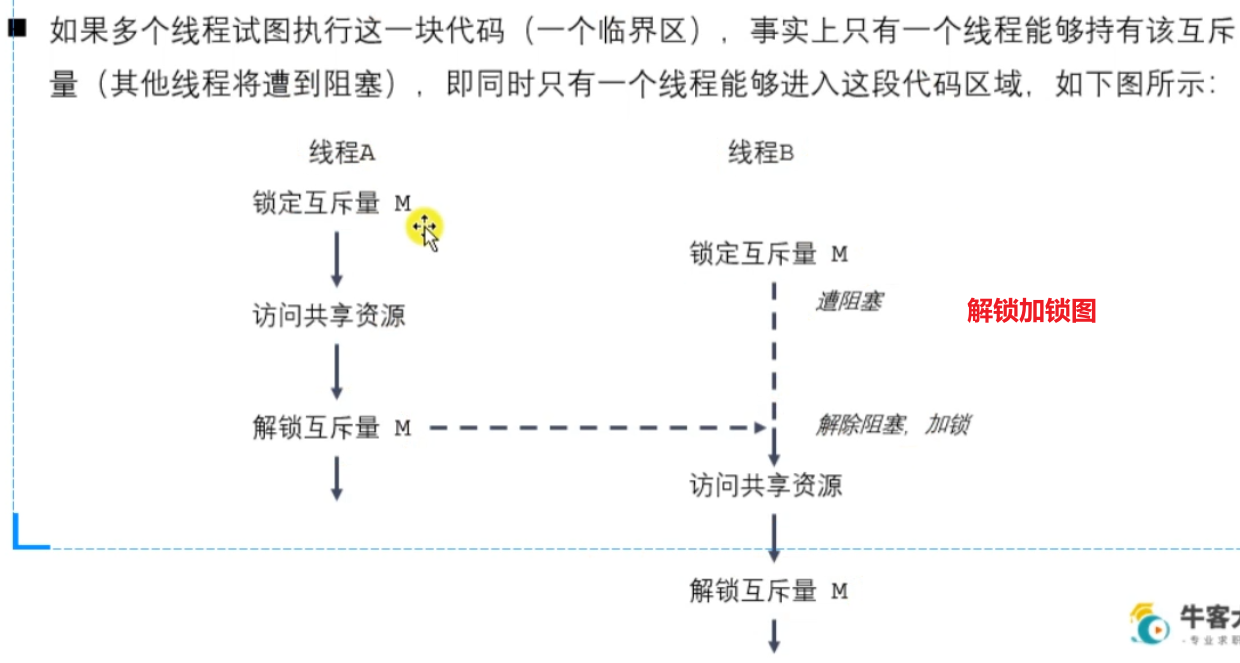
3.2 互斥量(互斥锁)
为避免线程更新共享变量时出现问题,可以使用互斥量(mutex 是mutual exclusion 的缩写)来确保同时仅有一个线程可以访问某项共享资源。可以使用互斥量来保证对任意共享资源的原子访问。
互斥量有两种状态:已锁定(locked) 和未锁定(unlocked) 。任何时候,至多只有一个线程可以锁定该互斥量。试图对已经锁定的某一互斥量再次加锁, 将可能阻塞线程或者报错失败,具体取决于加锁时使用的方法。
一旦线程锁定互斥量,随即成为该互斥量的所有者,只有所有者才能给互斥量解锁。
3.3 互斥量的相关函数
代码放在 lesson30 selltickets.c
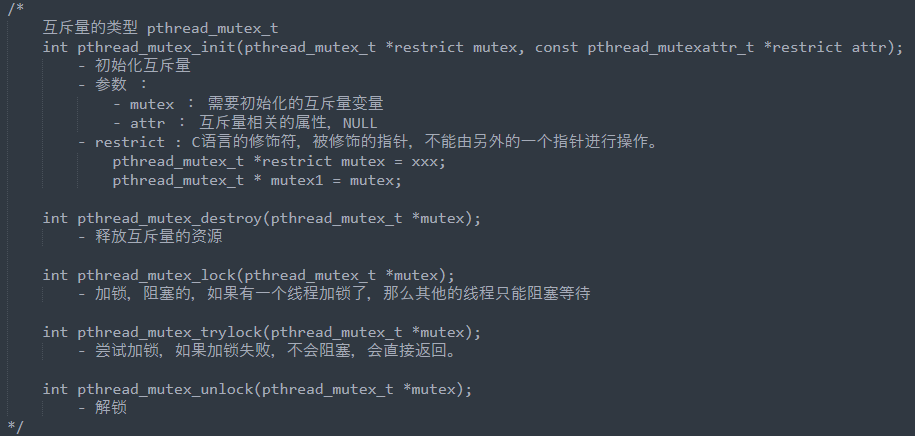
互斥量类型:pthread_mutex_t
1.API

2.代码
Step1:在全局中定义一个互斥量
定义在全局可以在不同的函数中访问
pthread_mutex_t mutex;
Step2:在 main 函数中初始化互斥量
// 初始化互斥变量
pthread_mutex_init(&mutex,NULL);
Step3:在 main 函数的最后释放资源
// 释放互斥量资源
pthread_mutex_destroy(&mutex);
Step4:为某段临界资源进行加锁和解锁
下面是对于子线程的回调函数,在访问 ticket 这个数据时进行了加锁,使用完成后进行解锁
加锁和解锁是定义在判断语句中的,不是定义在临界资源那个变量上的
void*sellticket(void * arg){
while(1){
// 加锁
pthread_mutex_lock(&mutex);
if(tickets>0){
printf("%ld 正在卖第 %d 张门票\n",pthread_self(),tickets);
tickets--;
}else{
// 解锁
pthread_mutex_unlock(&mutex);
break;
}
// 解锁
pthread_mutex_unlock(&mutex);
}
return 0;
}
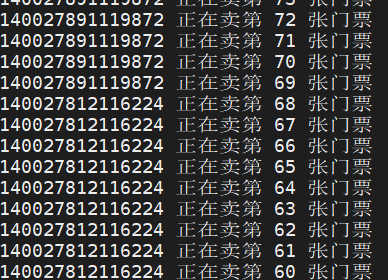
3.代码效果
最后可以看出来有多个线程在使用同一个变量,并且没有之前的重复访问和负数的问题
4.死锁
4.1 死锁基础知识
1.什么是死锁,以及死锁的场景
线程 A 占有锁1 ,线程 B 占有锁 2 ,但是 A 想用锁 2 ,B 想用锁 1 ,二者都得不到自己想用的资源,导致两个线程都没有办法进行下去
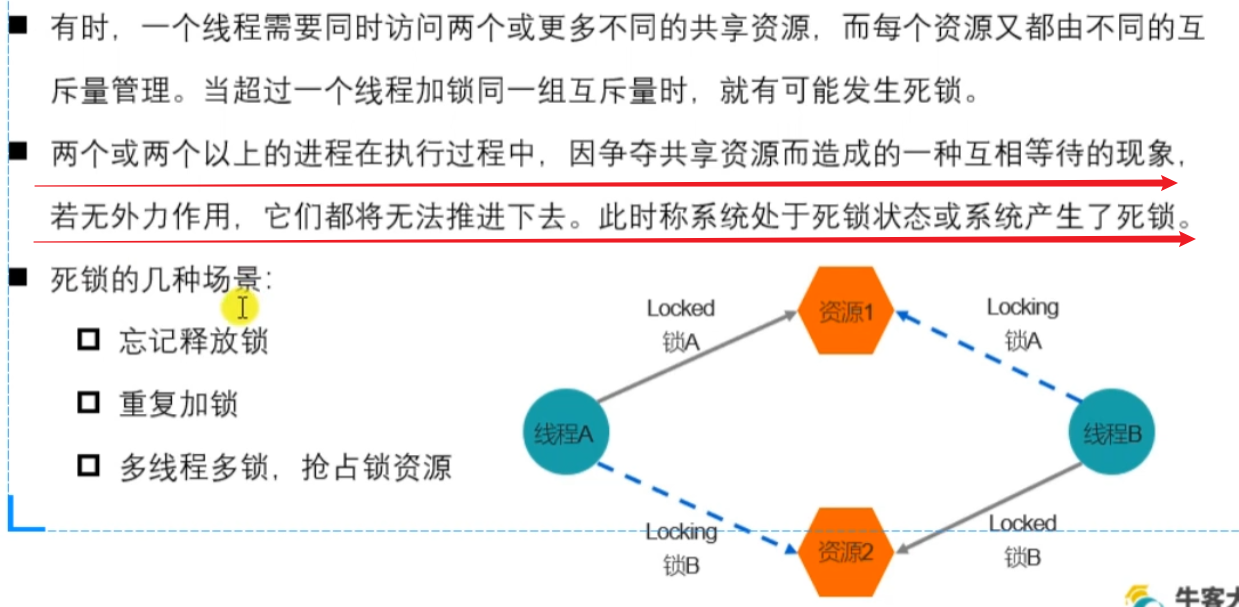
重复加锁:A 对临界资源加锁,B又对临界资源加锁。A 想用的时候 A 解锁,但是发现还有一个锁
4.2 模拟死锁
本代码保存在 lesson30 deadlock.c 中
4.2.1 模拟忘记释放锁
1.代码
当某个线程访问临界资源之后不对临界资源进行解锁,导致后面的继承无法访问
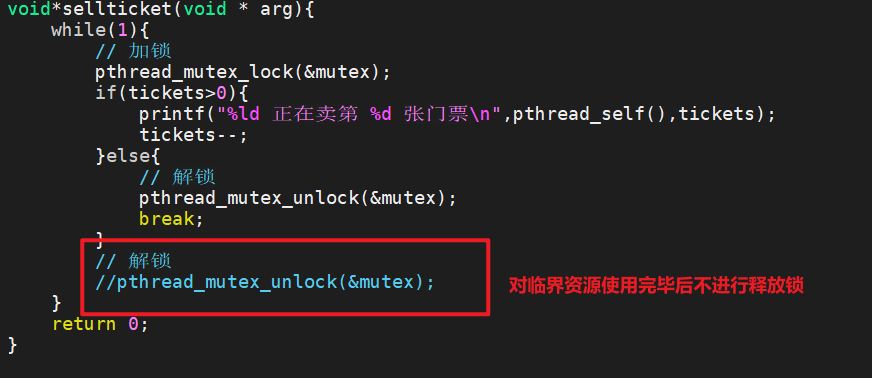
2.代码演示

4.2.2 模拟多线程多锁抢占资源
死锁代码当中看似抢占临界资源,其实是抢的是锁资源
本代码保存在 lesson30 deadlock1.c 中
1.代码
线程 A 先使用锁1 进行加锁,休息 1s 。线程 B 使用锁2 对数据进行加锁,也休息 1s 钟。这时候线程 A 想使用锁 2 进行加锁发现锁 2 被占用,所以就等着 B 释放锁 2,但是这时候 B 发现锁 1 被占用所以想等 A 释放锁 1 ,所以两个线程都在等另一方先释放锁资源。
关键代码:
A进程子线程处理方法,先调用锁1,再调用锁 2
void* workA(void *arg){
// 锁
pthread_mutex_lock(&mutex1); // 先调用锁1
sleep(1); // 等着 B 调用锁 2
pthread_mutex_lock(&mutex2); // 这时候想再占用锁2发现无法占用,因为 B 还没有释放
printf("WorkA....");
// 释放
pthread_mutex_unlock(&mutex1);
pthread_mutex_unlock(&mutex2);
return NULL;
}
B进程子线程处理方法,先调用锁2,再调用锁 1
void* workB(void *arg){
// 锁
pthread_mutex_lock(&mutex2); // 先占用锁2,但是不释放他
sleep(1);
pthread_mutex_lock(&mutex1); // 这时候想再占用锁1发现无法占用
printf("WorkB....");
// 释放
pthread_mutex_unlock(&mutex1);
pthread_mutex_unlock(&mutex2);
return NULL;
}
2.代码演示
最后可以看到两个进程都没办法运行,都在等着彼此释放锁

4.3读写锁
本代码保存在 lesson30 rwlock.c 中
4.3.1 读写锁的定义
解决互斥锁中只能有一个线程进入该临界资源的现象
多个读者可以同时进⾏读
写者必须互斥(只允许⼀个写者写,也不能读者写者同时进⾏)
写者优先于读者(⼀旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
4.3.2 读写锁的相关函数

try 尝试加锁
1.代码
创建 8 个进程,其中 3 个进程是对临界资源进行写操作,即改变某个变量的值;剩下的 5 个线程是对临界资源进行读操作
关键代码 :
(1) main 函数中创建读写锁
// 创建读写锁
pthread_rwlock_init(&rwlock,NULL);
销毁锁资源
// 销毁锁资源
pthread_rwlock_destroy(&rwlock);
(2)定义 8 个线程
// 创建 8 个线程
pthread_t wtids[3],rtids[5];
for(int i=0;i<3;i++) pthread_create(&wtids[i],NULL,writeNum,NULL);
for(int i=0;i<5;i++) pthread_create(&rtids[i],NULL,readNum,NULL);
(3) 写线程的执行代码
void* writeNum(void*arg){
// 写子进程,不断的将 num++
while(1){
// 将临界资源用锁锁起来
pthread_rwlock_wrlock(&rwlock);
num++;
printf("++write, tid : %ld, num : %d\n", pthread_self(), num);
// ++ 完成后释放锁
pthread_rwlock_unlock(&rwlock);
usleep(100); // 休息 100 纳秒
}
return NULL;
}
(4)读线程的执行代码
void* readNum(void*arg){
// 写子进程,不断的将 num++
while(1){
// 将临界资源用锁锁起来
pthread_rwlock_wrlock(&rwlock);
printf("===read, tid : %ld, num : %d\n", pthread_self(), num);
// ++ 完成后释放锁
pthread_rwlock_unlock(&rwlock);
usleep(100); // 休息 100 纳秒
}
return NULL;
}
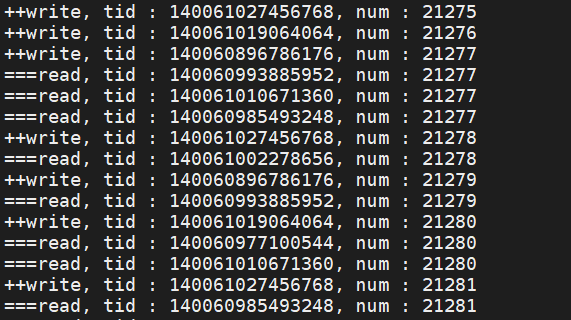
2.代码演示
从效果来看写进程的值比读进程的值要大,所以是先进行写锁在进行读锁,与此同时锁与锁之间交替进行
4.4 生产者消费者模型
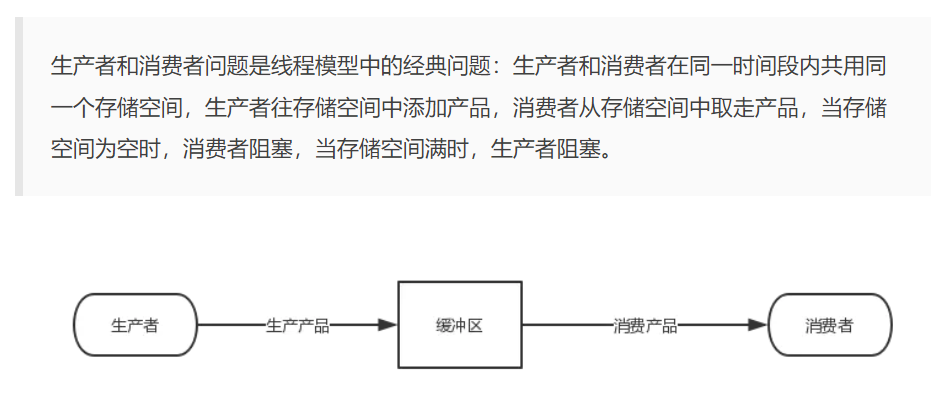
4.4.1 生产者消费者定义
4.4.2 条件变量(pthread_cond_t)的相关函数
代码保存在 lesson30 cond_newcode.c
条件变量的作用就是阻塞一个线程
条件变量是另外一种同步机制,可以用于线程和管程中的进程互斥。通常与互斥量一起使用。
条件变量允许线程由于一些暂时没有达到的条件而阻塞。通常,等待另一个线程完成该线程所需要的条件。条件达到时,另外一个线程发送一个信号,唤醒该线程。
条件变量对应的一组操作是pthread_cond_wait和pthread_cond_signal。
条件变量与互斥量一起使用,一般情况是:一个线程锁住一个互斥量,然后当它不能获得它期待的结果时,等待一个条件变量;最后另外一个线程向它发送信号,使得它可以继续执行。

pthread_cond_signal : 生产者生产出一个数据时使用此方法向消费者发送信号消费,这个时候生产者的线程被挂起,不再占用 CPU
pthread_cond_wait : 消费者消耗了一个数据之后提醒生产者生产数据,这个时候消费者的线程被挂起
这个也是操作系统中的 PV 操作
链表的使用
1.为链表定义节点
struct Node{
int num;
struct Node* next;
};
2.定义链表的头结点
struct Node* head = NULL;
3.创建一个正常节点 cur
Node* newNode = (struct Node*)malloc(sizeof(struct Node));
4.将 cur 节点插入链表
将 head 节点的后面节点给 newCode ,将 newCode 设置为 head
newNode->next = head;
head = newNode;
newNode->num = rand()%1000;
2.代码
创建一个生产者和一个消费者线程,生产者向链表中不断插入数据,消费者将链表的数据读取并进行删除,生产者插入数据后通知消费者取数据,消费者拿走数据后生产者继续生产。
(1) 生产者线程插入数据
void * producer(void * arg) {
// 不断的创建新的节点,添加到链表中
while(1) {
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->next = head;
head = newNode;
newNode->num = rand() % 1000;
printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());
// 只要生产了一个,就通知消费者消费
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
usleep(100);
}
return NULL;
}
(2) 消费者线程删除节点
void * customer(void * arg) {
while(1) {
pthread_mutex_lock(&mutex);
// 保存头结点的指针
struct Node * tmp = head;
// 判断是否有数据
if(head != NULL) {
// 有数据
head = head->next;
printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());
free(tmp); // 删除指针
pthread_mutex_unlock(&mutex);
usleep(100);
} else {
// 没有数据,需要等待
// 当这个函数调用阻塞的时候,会对互斥锁进行解锁,当不阻塞的,继续向下执行,会重新加锁。
pthread_cond_wait(&cond, &mutex);
pthread_mutex_unlock(&mutex);
}
}
return NULL;
}
(3)初始化互斥锁和条件变量
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
(4)销毁
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
4.5 信号量
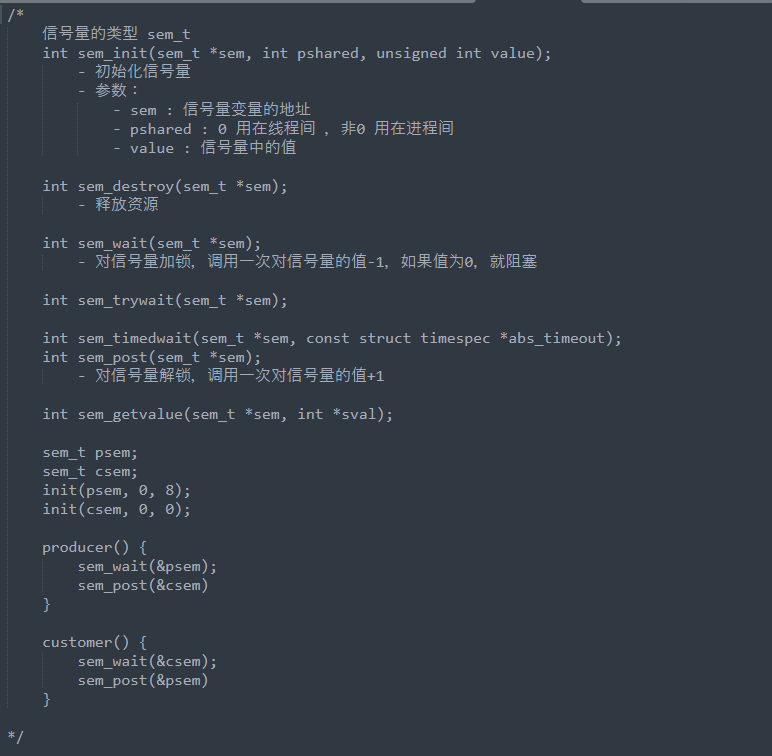
条件变量与信号量的不同:
条件变量是生产者生产一个数据就通知一次消费者;信号量中允许生产者生产多个信息然后通知消费者
信号量的代码中不需要销毁操作
2.代码
如同条件变量代码,消费者使用信号量的方式通知消费者获取数据
(1)初始化
// 全局变量:创建两个信号量
sem_t psem;
sem_t csem;
// 信号量初始化
sem_init(&psem, 0, 8);
sem_init(&csem, 0, 0);
(2)生产者代码
void * producer(void * arg) {
// 不断的创建新的节点,添加到链表中
while(1) {
sem_wait(&psem);
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->next = head;
head = newNode;
newNode->num = rand() % 1000;
printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());
pthread_mutex_unlock(&mutex);
sem_post(&csem);
}
return NULL;
}
(3) 消费者代码
void * customer(void * arg) {
while(1) {
sem_wait(&csem);
pthread_mutex_lock(&mutex);
// 保存头结点的指针
struct Node * tmp = head;
head = head->next;
printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());
free(tmp);
pthread_mutex_unlock(&mutex);
sem_post(&psem);
}
return NULL;
}
3.代码演示
代码和上面执行一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yonrSUAB-1644492844291)(/Users/xuguagua/Documents/typora_image/image-20211122121807390.png)]

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









