







AlexNet 深度卷积神经网络
一、前言
在LeNet出现后的十几年里,目标识别领域的主流还是传统目标识别算法,当然也与算力限制有关。直到2012年AlexNet赢ImageNet挑战赛,才使得卷积神经网络再次引起人们的关注,也因此一发不可收拾,不断推陈出新。
2012 年,Alex Krizhevsky等人提出的AlexNet模型在ILSVRC挑战赛中取得骄人成绩,这一成果使得CNN成为了当时最先进的图像识别模型。
AlexNet模型很大程度上推动了深度学习的发展,并为今天的卷积神经网络模型奠定了基础。截止2023.07.30,论文引用次数约12万。
-
AlexNet论文地址:
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf

二、AlexNet网络的亮点、创新点:
1.卷积神经网络(Deep Convolutional Neural Networks)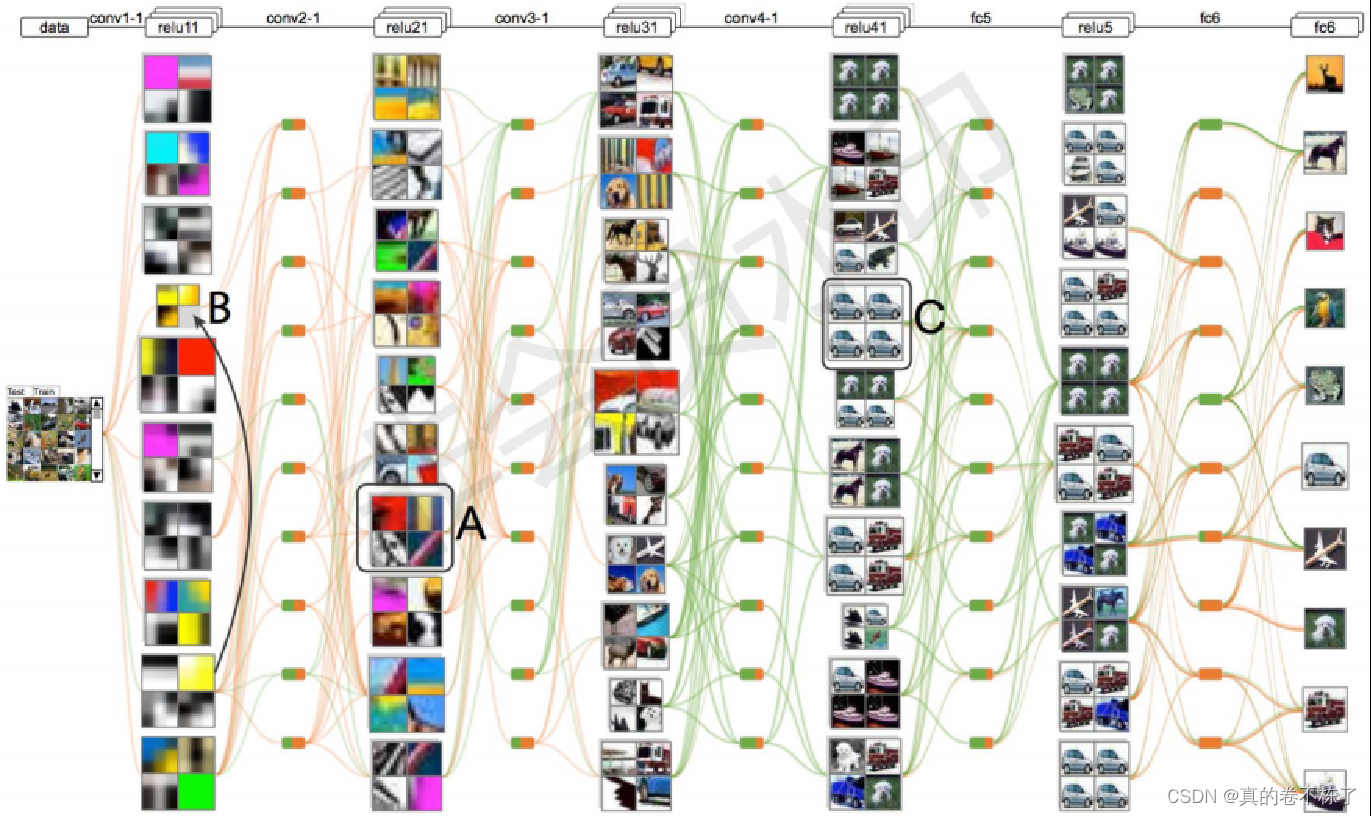
2.首次使用了双GPU进行网络加速训练。
GPU进行网络加速训练,双GPU实现。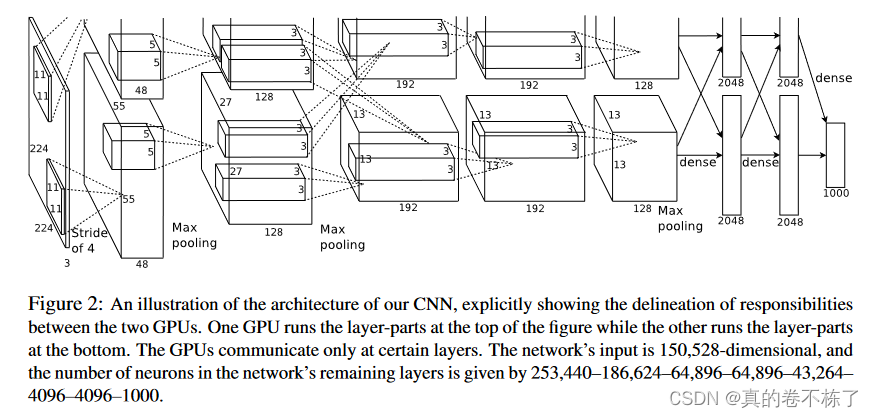
3.使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。
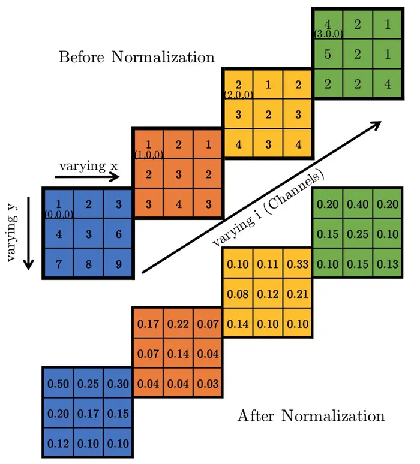
4.使用了LRN局部响应归一化。
Local Response Normalization,LRN

超参数:论文中使用的值是k=2,n=5,α=0.0001,β=0.75。
5.在全连接层的前两层中使用了Droupout随机失活神经元操作,以减少过拟合。

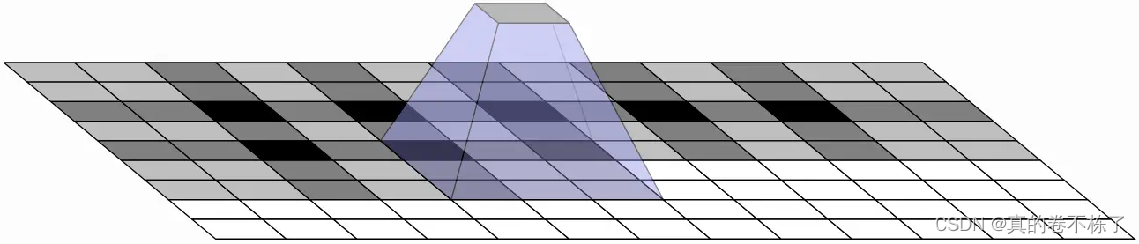
6.重叠池化Overlapping Pooling
7.数据增强
8.端到端训练
将每个像素减去训练集的像素均值。
三、AlexNet网络模型
AlexNet整体网络结构:1个输入层(input layer)、5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)。
AlexNet输入为RGB三通道的224 × 224 × 3大小的图像(也可填充为227 × 227 × 3 )。AlexNet 共包含5 个卷积层(包含3个池化)和 3 个全连接层。其中,每个卷积层都包含卷积核、偏置项、ReLU激活函数和局部响应归一化(LRN)模块。第1、2、5个卷积层后面都跟着一个最大池化层,后三个层为全连接层。最终输出层为softmax,将网络输出转化为概率值,用于预测图像的类别。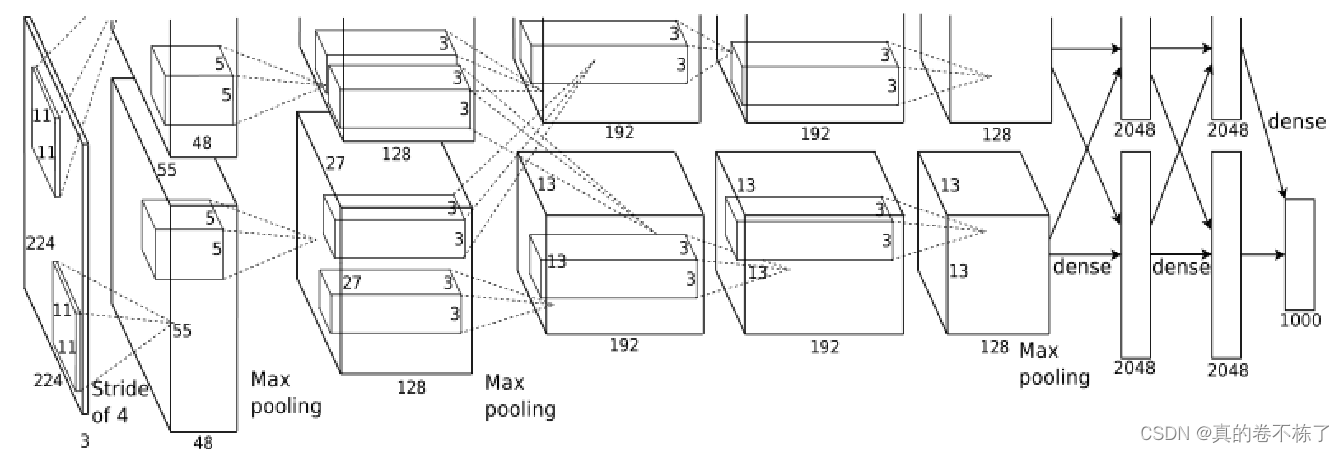
1.第一层卷积层(卷积、池化)
Conv1
输入数据:227×227×3,卷积核:11×11×3;步长:4;数量(也就是输出个数):96
由输入数据矩阵的尺寸W1 * H1 * D1 (输入层:227 * 227* 3) ,求输出特征图组尺寸W2 * H2 * D2 ,公式如下:
得出公式W2=(227-11+2*0)/4+1=55。
-
featuremap为:55 * 55
卷积后数据:55×55×96 (原图N×N,卷积核大小n×n,卷积步长大于1为k,输出维度是(N-n)/k+1) relu1后的数据:55×55×96
Maxpool1
Max pool1的核:3×3,步长:2
W2=(55-3+2*0)/2+1=27
-
featuremap为:27 * 27
Max pool1后的数据:27×27×96 norm1:local_size=5 (LRN(Local Response Normalization) 局部响应归一化) 最后的输出:27×27×96
AlexNet采用了Relu激活函数,取代了之前经常使用的S函数和T函数,Relu函数也很简单:
ReLU(x) = max(x,0)
AlexNet另一个创新是LRN(Local Response Normalization) 局部响应归一化,LRN模拟神经生物学上一个叫做 侧抑制(lateral inhibitio)的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。LRN局部响应归一化借鉴侧抑制的思想实现局部抑制,使得响应比较大的值相对更大,提高了模型的泛化能力。LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。LRN概念是在AlexNet模型中首次提出,在GoogLenet中也有应用,但是LRN的实际作用存在争议,如在2015年Very Deep Convolutional Networks for Large-Scale Image Recognition 论文中指出LRN基本没什么用。
AlexNet还应用了Overlapping(重叠池化),重叠池化就是池化操作在部分像素上有重合。池化核大小是n×n,步长是k,如果k=n,则是正常池化,如果 k<n, 则是重叠池化。官方文档中说明,重叠池化的运用减少了top-5和top-1错误率的0.4%和0.3%。重叠池化有避免过拟合的作用。
2.第二层卷积层(卷积、池化)
Conv2
输入数据:27×27×96,卷积核:5×5;步长:1;数量(也就是输出个数):256,
卷积后数据:27×27×256(做了Same padding(相同补白),使得卷积后图像大小不变。)
relu2后的数据:27×27×256
Max pool2
Max pool2的核:3×3,步长:2
Max pool2后的数据:13×13×256 ((27-3)/2+1=13 ) norm2:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:13×13×256
在AlexNet的conv2中使用了same padding,保持了卷积后图像的宽高不缩小。
3.第三层卷积层(卷积、池化)
Conv3
输入数据:13×13×256
卷积核:3×3;步长:1;数量(也就是输出个数):384 卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。) relu3后的数据:13×13×384 最后的输出:13×13×384
无Max pool3
conv3层没有Max pool层和norm层
4.第四层卷积层(卷积、池化)
Conv4
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):384 卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。) relu4后的数据:13×13×384 最后的输出:13×13×384
无Max pool4
conv4层也没有Max pool层和norm层
5.第五层卷积层(卷积、池化)
Conv5
输入数据:13×13×384 卷积核:3×3;步长:1;数量(也就是输出个数):256 卷积后数据:13×13×256 (做了Same padding(相同补白),使得卷积后图像大小不变。) relu5后的数据:13×13×256
无Max pool5
Max pool5的核:3×3,步长:2 Max pool2后的数据:6×6×256 ((13-3)/2+1=6 ) 最后的输出:6×6×256
conv5层有Max pool,没有norm层
6.第六层fc6阶段
输入数据:6×6×256,全连接输出:4096×1,relu6后的数据:4096×1
drop out6后数据:4096×1 最后的输出:4096×1
AlexNet在fc6全连接层引入了drop out的功能。dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率(一般是50%,这种情况下随机生成的网络结构最多)将其暂时从网络中丢弃(保留其权值),不再对前向和反向传输的数据响应。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而相当于每一个mini-batch都在训练不同的网络,drop out可以有效防止模型过拟合,让网络泛化能力更强,同时由于减少了网络复杂度,加快了运算速度。还有一种观点认为drop out有效的原因是对样本增加来噪声,变相增加了训练样本。
7.第七层fc7阶段
输入数据:4096×1
全连接输出:4096×1 relu7后的数据:4096×1 drop out7后数据:4096×1 最后的输出:4096×1
8.第八层fc8阶段
输入数据:4096×1 全连接输出:1000 fc8输出一千种分类的概率。
四、AlexNet代码实现
1.定义AlexNet网络模型
import torch import torch.nn as nn class AlexNet(nn.Module): def __init__(self, config): super(AlexNet, self).__init__() self._config = config # 定义卷积层和池化层 self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, stride=1, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, stride=1, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) # 自适应层,将上一层的数据转换成6x6大小 self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # 全连接层 self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 1024), nn.ReLU(inplace=True), nn.Linear(1024, self._config['num_classes']), ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x
2.定义模型保存与模型加载函数
def saveModel(self): torch.save(self.state_dict(), self._config['model_name']) def loadModel(self, map_location): state_dict = torch.load(self._config['model_name'], map_location=map_location) self.load_state_dict(state_dict, strict=False)
3.数据集预处理
这里选择采用CIFAR-10数据集。
import torchvision from torch.utils.data import DataLoader import torchvision.transforms as transforms # 定义构造数据加载器的函数 def Construct_DataLoader(dataset, batchsize): return DataLoader(dataset=dataset, batch_size=batchsize, shuffle=True) # 图像预处理 transform = transforms.Compose([ transforms.Resize(96), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # 加载CIFAR-10数据集函数 def LoadCIFAR10(download=False): # Load CIFAR-10 dataset train_dataset = torchvision.datasets.CIFAR10(root='../CIFAR10', train=True, transform=transform, download=download) test_dataset = torchvision.datasets.CIFAR10(root='../CIFAR10', train=False, transform=transform) return train_dataset, test_dataset
4.模型训练函数封装
from torch.autograd import Variable
from torch.utils.data import DataLoader
import torch.nn as nn
class Trainer(object):
# 初始化模型、配置参数、优化器和损失函数
def __init__(self, model, config):
self._model = model
self._config = config
self._optimizer = torch.optim.Adam(self._model.parameters(),\
lr=config['lr'], weight_decay=config['l2_regularization'])
self.loss_func = nn.CrossEntropyLoss()
# 对单个小批量数据进行训练,包括前向传播、计算损失、反向传播和更新模型参数
def _train_single_batch(self, images, labels):
y_predict = self._model(images)
loss = self.loss_func(y_predict, labels)
# 先将梯度清零,如果不清零,那么这个梯度就和上一个mini-batch有关
self._optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 梯度下降等优化器 更新参数
self._optimizer.step()
# 将loss的值提取成python的float类型
loss = loss.item()
# 计算训练精确度
# 这里的y_predict是一个多个分类输出,将dim指定为1,即返回每一个分类输出最大的值以及下标
_, predicted = torch.max(y_predict.data, dim=1)
return loss, predicted
def _train_an_epoch(self, train_loader, epoch_id):
"""
训练一个Epoch,即将训练集中的所有样本全部都过一遍
"""
# 设置模型为训练模式,启用dropout以及batch normalization
self._model.train()
total = 0
correct = 0
# 从DataLoader中获取小批量的id以及数据
for batch_id, (images, labels) in enumerate(train_loader):
images = Variable(images)
labels = Variable(labels)
if self._config['use_cuda'] is True:
images, labels = images.cuda(), labels.cuda()
loss, predicted = self._train_single_batch(images, labels)
# 计算训练精确度
total += labels.size(0)
correct += (predicted == labels.data).sum()
# print('[Training Epoch: {}] Batch: {}, Loss: {}'.format(epoch_id, batch_id, loss))
print('Training Epoch: {}, accuracy rate: {}%%'.format(epoch_id, correct / total * 100.0))
def train(self, train_dataset):
# 是否使用GPU加速
self.use_cuda()
for epoch in range(self._config['num_epoch']):
print('-' * 20 + ' Epoch {} starts '.format(epoch) + '-' * 20)
# 构造DataLoader
data_loader = DataLoader(dataset=train_dataset, batch_size=self._config['batch_size'], shuffle=True)
# 训练一个轮次
self._train_an_epoch(data_loader, epoch_id=epoch)
# 用于将模型和数据迁移到GPU上进行计算,如果CUDA不可用则会抛出异常
def use_cuda(self):
if self._config['use_cuda'] is True:
assert torch.cuda.is_available(), 'CUDA is not available'
torch.cuda.set_device(self._config['device_id'])
self._model.cuda()
# 保存训练好的模型
def save(self):
self._model.saveModel()
5.训练+测试过程
对模型进行训练与测试,最终打印输出测试准确率。
from torch.autograd import Variable
# 定义参数配置信息
alexnet_config = \
{
'num_epoch': 20, # 训练轮次数
'batch_size': 500, # 每个小批量训练的样本数量
'lr': 1e-3, # 学习率
'l2_regularization':1e-4, # L2正则化系数
'num_classes': 10, # 分类的类别数目
'device_id': 0, # 使用的GPU设备的ID号
'use_cuda': True, # 是否使用CUDA加速
'model_name': '../AlexNet.model' # 保存模型的文件名
}
if __name__ == "__main__":
####################################################################################
# AlexNet 模型
####################################################################################
train_dataset, test_dataset = LoadCIFAR10(True)
# define AlexNet model
alexNet = AlexNet(alexnet_config)
####################################################################################
# 模型训练阶段
####################################################################################
# # 实例化模型训练器
trainer = Trainer(model=alexNet, config=alexnet_config)
# # 训练
trainer.train(train_dataset)
# # 保存模型
trainer.save()
####################################################################################
# 模型测试阶段
####################################################################################
alexNet.eval()
alexNet.loadModel(map_location=torch.device('cpu'))
if alexnet_config['use_cuda']:
alexNet = alexNet.cuda()
correct = 0
total = 0
# 对测试集中的每个样本进行预测,并计算出预测的精度
for images, labels in Construct_DataLoader(test_dataset, alexnet_config['batch_size']):
images = Variable(images)
labels = Variable(labels)
if alexnet_config['use_cuda']:
images = images.cuda()
labels = labels.cuda()
y_pred = alexNet(images)
_, predicted = torch.max(y_pred.data, 1)
total += labels.size(0)
temp = (predicted == labels.data).sum()
correct += temp
print('Accuracy of the model on the test images: %.2f%%' % (100.0 * correct / total))
6.运行结果
D:\Anaconda\envs\pytorch\python.exe E:/pythoncode/深度学习/AlexNet.py
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../CIFAR10\cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [00:42<00:00, 4057573.25it/s]
Extracting ../CIFAR10\cifar-10-python.tar.gz to ../CIFAR10
-------------------- Epoch 0 starts --------------------
Training Epoch: 0, accuracy rate: 20.375999450683594%%
-------------------- Epoch 1 starts --------------------
Training Epoch: 1, accuracy rate: 38.96799850463867%%
-------------------- Epoch 2 starts --------------------
Training Epoch: 2, accuracy rate: 49.88399887084961%%
-------------------- Epoch 3 starts --------------------
Training Epoch: 3, accuracy rate: 55.60199737548828%%
-------------------- Epoch 4 starts --------------------
Training Epoch: 4, accuracy rate: 59.9219970703125%%
-------------------- Epoch 5 starts --------------------
Training Epoch: 5, accuracy rate: 62.67799758911133%%
-------------------- Epoch 6 starts --------------------
Training Epoch: 6, accuracy rate: 66.00999450683594%%
-------------------- Epoch 7 starts --------------------
Training Epoch: 7, accuracy rate: 68.08200073242188%%
-------------------- Epoch 8 starts --------------------
Training Epoch: 8, accuracy rate: 70.26399993896484%%
-------------------- Epoch 9 starts --------------------
Training Epoch: 9, accuracy rate: 71.89399719238281%%
-------------------- Epoch 10 starts --------------------
Training Epoch: 10, accuracy rate: 73.50599670410156%%
-------------------- Epoch 11 starts --------------------
Training Epoch: 11, accuracy rate: 74.86000061035156%%
-------------------- Epoch 12 starts --------------------
Training Epoch: 12, accuracy rate: 76.73400115966797%%
-------------------- Epoch 13 starts --------------------
Training Epoch: 13, accuracy rate: 76.947998046875%%
-------------------- Epoch 14 starts --------------------
Training Epoch: 14, accuracy rate: 78.78999328613281%%
-------------------- Epoch 15 starts --------------------
Training Epoch: 15, accuracy rate: 79.88599395751953%%
-------------------- Epoch 16 starts --------------------
Training Epoch: 16, accuracy rate: 80.88600158691406%%
-------------------- Epoch 17 starts --------------------
Training Epoch: 17, accuracy rate: 81.64599609375%%
-------------------- Epoch 18 starts --------------------
Training Epoch: 18, accuracy rate: 83.03600311279297%%
-------------------- Epoch 19 starts --------------------
Traceback (most recent call last):
File "E:\pythoncode\深度学习\AlexNet.py", line 176, in <module>
trainer.save()
File "E:\pythoncode\深度学习\AlexNet.py", line 145, in save
self._model.saveModel()
File "D:\Anaconda\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 1265, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'AlexNet' object has no attribute 'saveModel'
Training Epoch: 19, accuracy rate: 83.73799896240234%%


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











