




回溯的本质实际上是带撤销操作的 DFS(深度优先搜索),其精神为“小步探索,随时剪枝”。实际上,它是一种解空间搜索策略:从初始状态出发,每一步选择一个可行操作,沿着这条路径尝试构造完整解。如果发现当前路径不可行或者无法产生合法解,则回退到上一步,撤销刚才的操作,尝试另一条可行路径。这个“试探—失败—撤销—继续尝试”的过程是回溯的核心,它保证了搜索的完整性,同时又能通过剪枝优化性能。
回溯与 DFS 密切相关,因为每一次递归就对应于解空间(回溯树)的一层,每一层的分支表示当前状态的可选方案。相比 BFS(广度优先搜索),回溯的优势在于它只需维护当前路径及相关状态,而 BFS 通常需要存储所有“部分解”的状态队列,容易导致内存占用急剧增加,尤其在解空间指数级增长时,这一点尤为明显。
另外,回溯算法非常适合处理“带约束的组合问题”,比如全排列、N 皇后、数独、括号生成、分割回文串等。这里的约束可以是合法性检查、重复性判断、最大最小限制等。回溯不仅保证了解的完整性,还允许在探索过程中随时剪掉不可能的分支,这就是它“小步探索,随时剪枝”的精髓。
一个形象的比喻是:回溯就像在迷宫中寻找出口。每次走到一个分叉路口,你选择一条路前进;如果走到死路,你退回上一个路口,尝试另一条路。这个“走不通就退回”的策略,使你能够系统而完整地遍历整个迷宫,而不必把每一条可能的路径都同时记在脑海中。我总结出了一些经典的DFS回溯的题目,我们一起来看看。
一.组合型回溯
刚看到这道题我也揣摩了半天,看似很简单但是想要直接get到要点并不容易。相信朋友们短暂思考之后一定会想到一个问题:到底会产生多少种组合?这就涉及到高中数学计数原理学的排列组合公式了。惭愧地说,我已经把这个知识还给高中数学老师了,查阅了一下发现,对于范围 [1, n] 中所有可能的 k 个数的组合数为C(n,k)=n(n-1)/2。
要确定一个组合内的所有可能,很显然,我们先要在组合当中建立一个“基准”进行讨论。在这道题中便是固定一个数i。那么剩下的可能性就是在剩下的n-i个数中选k-1个数,即C(n-i,k-1)。后续过程本质上就是在枚举。我们举个例子来观察一下:n=4,k=2。
按照前面给出的公式,会形成C(4,2)=6个不同的组合。假设我们固定i=1,枚举其他数字就会形成[1,2],[1,3],[1,4]这三个组合。此时发现i=1的情况已经枚举完了,发现“撞了南墙”,那我们回头开始枚举i=2的过程(这一步就是回溯),后面的过程同理。我们发现在没有“撞南墙”之前,实际上执行的操作都是相同的枚举行为,于是我们想到了DFS。这其实就是一个树形结构的DFS+回溯,下面我会给出一张图示,相信朋友们看过之后会有更深刻的理解。我在第一次思考的时候完全没想到树形结构,理由是我把[1,x]视为根节点,而实际上,这种问题根节点的状态往往是[]。
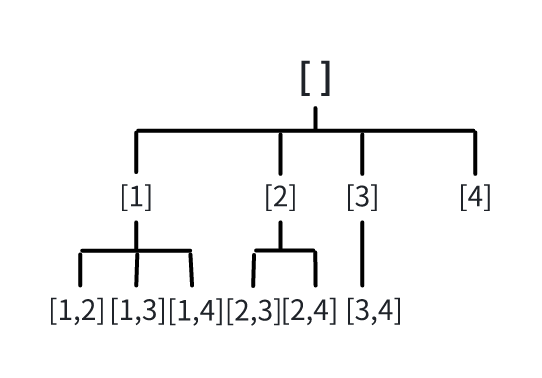
我们观察这棵DFS树,不难发现,一条路径要走到深度 k 才收集答案,往往这种题目会给定“窗口大小k”。这也就是“组合”类题目的最大特点。示例代码如下:
class Solution {
public:
int n_global;
int k_global;
void dfs(vector<vector<int>>& ans, int start, vector<int>& path) {
if (path.size() == k_global) {//一条路径走到深度k才收集答案
ans.push_back(path);
return;
}
for (int i = start; i <= n_global; ++i) {
path.push_back(i);
dfs(ans, i + 1, path);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
n_global = n;
k_global = k;
vector<vector<int>> ans;
vector<int> path;
dfs(ans, 1, path);
return ans;
}
};二.子集型回溯
题设给我们的整数数组是可能包含重复元素的,但是解集不能包含重复子集,要求我们返回全部的子集。与前面“组合型”的回溯不同,子集并不严格限制元素个数,而且我们不考虑顺序。哪怕是空集也是其中一个子集。实际上我们在考虑问题的时候可以从子集的定义出发,实际上每个元素都有两种状态:被选进子集和不被选进子集。由此我们可以自然地想到:对于每一个元素,递归地考虑“选”和“不选”这两种情况,最后把路径保存下来,我们不难发现这是一个二叉树结构。对于用例[1,2,2]我们可以结合下面的回溯树来理解:

这里又有一个新问题,就是集合中存在重复元素。像上面的回溯树演示的那样,在不同路径下,子集[1,2]和子集[2]会重复出现两次,这是题设不允许的,我们必须设计一个去重逻辑。实际上我们希望对于集合内重复的元素,只在第一次出现的时候引出一条分支。由此我们先对数组进行排序,保证相同的元素一定是左右相邻的。然后在回溯的同一层循环中如果遇到和前一个数相等就跳过。这条规则保证同一层只在第一个相同值上分叉一次,从而避免产生重复子集。示例代码如下:
class Solution {
public:
void dfs(vector<vector<int>>& ans,vector<int>&path,vector<int>& nums,int start){
ans.push_back(path);
for(int i=start;i<=nums.size()-1;i++){
if(i>start&&nums[i]==nums[i-1]){//去重逻辑
continue;
}
path.push_back(nums[i]);
dfs(ans,path,nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<vector<int>> ans;
vector<int> path;
sort(nums.begin(),nums.end());
dfs(ans,path,nums,0);
return ans;
}
};拿到这道题其实一开始我会习惯性的想到利用栈结构来解决,好像看到类似括号匹配的问题就会往这方面想。但是在这道题目中我发现有一种思考方向,就是对于每一个括号,只有删除或者保留两种选择,这让我联想到前面子集问题每个元素“选或不选”的特征,于是开始考虑能否使用DFS回溯的方式来解决这道题。目前看来框架确实很像,但是我们观察一下题目中给出的数据量,字符串s中可能会有20个括号,如果全部枚举递归的话,时间复杂度大约在2^20级别,极其容易导致超时,所以我们需要设计剪枝策略,限制删除的括号数量。
这道题目有一个极其重要的约束点:删除最少数量的无效括号。一开始我没有注意到,导致第一次做这道题时思路出现了偏差。实际上,在正式开始DFS回溯之前,需要删除的括号数量是可以提前统计出来的。比如“()())()”,由于多了一个")",所以至少要删除一个右括号。左括号则不需要删,我们做一次线性扫描就可以实现。如果当前删除的括号数量大于我们之前算出来的需要删除的括号数量,这就不满足“删除最少数量的无效括号”的题设,剪枝,这样删多了的路径都会被剪掉。之后在DFS过程中,我们需要随时保证“部分合法”,我们分别用两个变量来记录当前保留的左右括号数量,只要当前保留的右括号数量大于左括号数量,没得商量那一定不合法,剪枝。如果当前遇到的是非括号字符,则一律保留,接着往下走。根据我们前几道题的经验,DFS是有可能产生相同结果的,而显然这道题目是不允许有重复的,得益于C++ STL的封装,我们可以使用可去重的数据结构set来进行结果收集,这样就自动完成了去重,最后输出结果时转换为vector即可。示例代码如下:
class Solution {
public:
void dfs(const string& s, int idx, int leftRem, int rightRem,
int leftCount, int rightCount, string& path, unordered_set<string>& res) {
if (idx == (int)s.size()) {
if (leftRem == 0 && rightRem == 0 && leftCount == rightCount) {
res.insert(path);
}
return;
}
char c = s[idx];
if (c != '(' && c != ')') {
path.push_back(c);
dfs(s, idx + 1, leftRem, rightRem, leftCount, rightCount, path, res);
path.pop_back();
return;
}
if (c == '(') {
if (leftRem > 0) {
dfs(s, idx + 1, leftRem - 1, rightRem, leftCount, rightCount, path, res);
}
path.push_back('(');
dfs(s, idx + 1, leftRem, rightRem, leftCount + 1, rightCount, path, res);
path.pop_back();
}
else {
if (rightRem > 0) {
dfs(s, idx + 1, leftRem, rightRem - 1, leftCount, rightCount, path, res);
}
if (rightCount < leftCount) {
path.push_back(')');
dfs(s, idx + 1, leftRem, rightRem, leftCount, rightCount + 1, path, res);
path.pop_back();
}
}
}
vector<string> removeInvalidParentheses(string s) {
unordered_set<string> res;
string path;
int leftRem = 0, rightRem = 0;
for (char c : s) {
if (c == '(') leftRem++;
else if (c == ')') {
if (leftRem > 0) leftRem--;
else rightRem++;
}
}
dfs(s, 0, leftRem, rightRem, 0, 0, path, res);
return vector<string>(res.begin(), res.end());
}
};三.排列型回溯
题设给出了一个可能包含重复元素的序列(假设序列中有k个元素),要返回的是不同顺序的全排列。首先全排列这个字眼就意味着一条路径要走到深度 k 才收集答案。这里可能会有朋友们觉得这个场景和我们介绍过的组合问题基本一样,实际上区别还是很大的。我们来打个比方:想象你有 3 张不同的牌:A、B、C。对于组合问题,你只需要关心有哪些牌,不关心顺序,比如[A,B]和[B,A]是被视为一种情况的。而对于全排列问题,你不仅要关心有哪些牌,还要决定出牌顺序!比如[A,B,C]和[B,A,C]就是两种完全不同的情况。
区别于前面子集问题选或不选的二叉树结构,全排列问题递归的核心是在还没用过的元素中挑一个!也就是说,全排列的递归 不是二叉树,而是“多叉树”,每一层的分叉数取决于“还剩多少个元素”。每一层都能尝试所有元素,但不能重复用,所以要挂个 mem[i] 布尔缓存进行标记,这便实现了同层去重。由于题设中给出的集合可能包含重复元素,所以我们最终得到的全排列也可能会包含重复元素。同层去重只在前一个相同数字没被用过时才跳过;如果前一个已经用过,说明是同枝,可以继续用。同层重复被跳过,而同枝(路径延伸)可以继续使用。和之前子集问题一样,可能会出现相同的全排列,我们采用的去重方式(排序去重)和子集II问题中的策略完全相同,此处不再赘述,大家可以结合下面的回溯树来理解: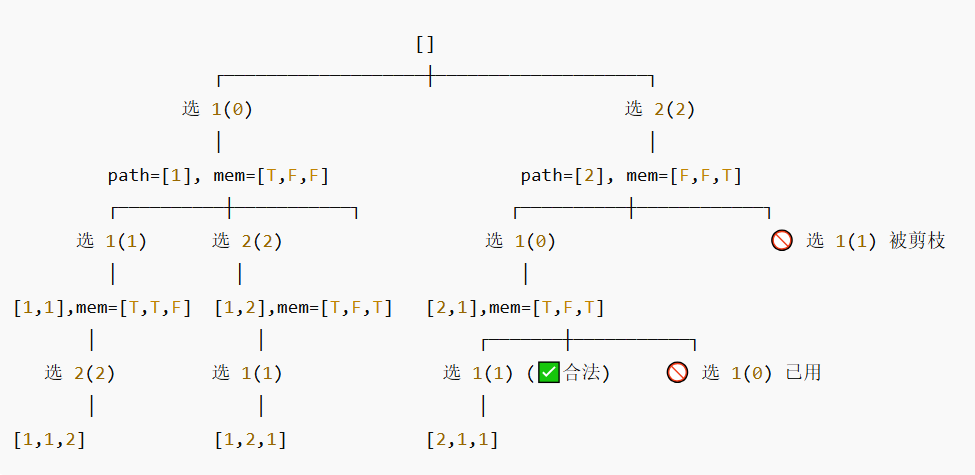
示例代码如下:
class Solution {
public:
void dfs(vector<vector<int>>& ans,vector<int>& path,vector<int>& nums,vector<bool>& mem){
if(path.size()==nums.size()){
ans.push_back(path);
return;
}
for(int i=0;i<=nums.size()-1;i++){
if(mem[i]) continue;
if(i>0&&nums[i]==nums[i-1]&&!mem[i-1]){
continue;
}
path.push_back(nums[i]);
mem[i]=true;
dfs(ans,path,nums,mem);
path.pop_back();
mem[i]=false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<vector<int>> ans;
vector<int> path;
vector<bool> mem(nums.size(),false);
sort(nums.begin(),nums.end());
dfs(ans,path,nums,mem);
return ans;
}
};这道题可谓是赫赫有名,属于经典中的经典了!还记得大一的时候初入门算法就被这道题目复杂的外表劝退。两年之后再回来做这种题目,那一定是游刃有余。题设给了一个n*n的棋盘,上面放置n个“皇后”,当皇后之间处于同行,同列,同斜线时就认定“皇后”之间会相互攻击。要求我们返回不同N皇后问题的解决方案。对于这个问题而言,最好处理的两个约束条件就是每行和每列恰好只放一个“皇后”。实际上到目前为止,这个问题就是一个列的全排列问题。对于全排列问题而言,回溯树上的每一层放的是一个位置,分支表示可选元素;而对于目前为止的N皇后问题而言,回溯树上的每一层放的是棋盘行,分支表示安全可放置的列。但是这道题目真正棘手的约束条件在斜线方向上,所以N皇后问题的本质是带约束条件的全排列问题。
在棋盘中有左对角线和右对角线两条斜线(以左/右上角为准),现在对于我们而言最重要的便是探索出同斜线上两个“皇后”的数学关系。如果两个“皇后”在左对角线方向上同斜线,则行数和列数差值一定为0,这里我们需要注意一个问题,r-c的取值范围是-(n-1)到n-1,存在负数,而数组索引不能为负,所以我们需要加上n-1的偏移量;而如果两个“皇后”在右对角线方向上同斜线,则行数和列数的和一定相等。我们只需要用两个布尔数组(att1,att2)来进行标记,就可以在O(1) 时间判断某条对角线是否已有皇后,回溯效率更高。示例代码如下:
class Solution {
public:
void dfs(vector<vector<string>>& ans,
vector<string>& board,
vector<bool>& col,
vector<bool>& att1,
vector<bool>& att2,
int r) {
int n = board.size();
if (r == n) {
ans.push_back(board);
return;
}
for (int c = 0; c < n; c++) {
int plus = r + c;
int minus = r - c + n - 1;
if (!col[c] && !att1[plus] && !att2[minus]) {
board[r][c] = 'Q';
col[c] = att1[plus] = att2[minus] = true;
dfs(ans, board, col, att1, att2, r + 1);
col[c] = att1[plus] = att2[minus] = false;
board[r][c] = '.';
}
}
}
vector<vector<string>> solveNQueens(int n) {
vector<vector<string>> ans;
vector<string> board(n, string(n, '.'));
vector<bool> col(n, false), att1(2 * n - 1, false), att2(2 * n - 1, false);
dfs(ans, board, col, att1, att2, 0);
return ans;
}
};这里可能会有朋友感觉DFS函数里传参好长好多啊,有没有比较简洁的写法呢?有的,可以使用C++11新特性提供的lambda表达式(匿名函数),这样可以不用跨作用域传参,推荐大家去学习一下lambda表达式,如果有需要的话后期我也会出专题文章介绍。这里我和大家分享一个我写这道题时犯的错误:我是这么定义lambda表达式的:auto dfs=[&](int r)->void。这么些逻辑上确实是没问题的,但是dfs在还没定义完时自身还不存在,lambda内部递归调用dfs会报未定义。正确的做法是用function进行包装,function是可拷贝对象,可以在lambda内部引用自己,这是C++lambda递归调用的标准做法。我这里先给出这道题用lambda表达式的解法供大家参考,用这种方式代码量就能少很多了:
class Solution {
public:
vector<vector<string>> solveNQueens(int n) {
vector<vector<string>> ans;
vector<string> board(n, string(n, '.'));
vector<bool> col(n, false), att1(2 * n - 1, false), att2(2 * n - 1, false);
function<void(int)> dfs = [&](int r) {
if (r == n) {
ans.push_back(board);
return;
}
for (int c = 0; c < n; c++) {
int plus = r + c;
int minus = r - c + n - 1;
if (!col[c] && !att1[plus] && !att2[minus]) {
board[r][c] = 'Q';
col[c] = att1[plus] = att2[minus] = true;
dfs(r + 1);
col[c] = att1[plus] = att2[minus] = false;
board[r][c] = '.';
}
}
};
dfs(0);
return ans;
}
};老实和大家说,我对于这道题仿佛有一种原生的心理阴影。原因好像小学或者初中的时候看过这种数独智力题,但是我是个很笨的人,脑子不太好使,做不出来很挫败。没想到若干年后会用计算机编程来解决这种数独类的题目。在题目中数独的解法需要遵循以下三种规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。下面给出lc的示例图来辅助理解

首先,我们来看最直观的约束条件:每行每列数字不能重复。这和 N 皇后问题的“每行每列只能放一个皇后”的约束逻辑非常类似。在 N 皇后问题中,我们用 col 数组标记某一列是否已有皇后;在数独中,我们同样用二维布尔数组来标记数字 x 在第 i 行或第 j 列是否已经出现过。这样,我们就可以在 O(1) 时间判断某个数字能否放在当前行列。但是与 N 皇后问题相比,数独多了一个关键约束:每个 3×3 宫内数字也不能重复。也就是说,每个数字的位置不仅受行列限制,还受局部区域的限制。这个约束可通过一个三维布尔数组来规定,我们可以快速判断数字 x 是否已经在对应的 3×3 宫中出现,从而保证填入的数字合法性。
再来看搜索策略。我认为这道题目的关键点就在这里:解数独问题时我们通常从候选数字最少的格子出发(上图中的(4,4位置)),实际上这是一种贪心策略,也正因为这样我们需要引入一个特殊的数据结构--小根堆作为候选队列。由此我们首先统计所有空格的位置,并为每个空格计算可填数字的候选数。每次我们从候选队列中选择一个空格,尝试填入一个合法数字,然后更新三个布尔数组,表示该数字在对应行、列、宫中已经使用。然后我们生成新的候选队列,根据剩余空格的候选数重新排序,这样可以尽早选择约束最紧的空格,提高回溯效率。
如果某一步填入数字导致后续空格无法继续填入合法数字,递归会回溯:恢复数字为空格,同时把布尔数组对应标记恢复为 false,继续尝试下一个数字。整个回溯树的每一层表示一个空格,每个分支表示该空格可以选择的数字。逻辑上,这道题和全排列问题非常类似,只不过全排列关注的是数字是否已经使用,而数独更关注数字在位置上的合法性。示例代码如下,当然,我个人还是更推荐用lamba表达式来写,毕竟传参实在是有点多:
class Solution {
public:
void solveSudoku(vector<vector<char>>& board) {
bool row_ex[9][9]{}, col_ex[9][9]{}, part_ex[3][3][9]{};
vector<pair<int,int>> empty_pos;
for(int i=0;i<9;i++){
for(int j=0;j<9;j++){
char c=board[i][j];
if(c=='.') empty_pos.emplace_back(i,j);
else {
int x=c-'1';
row_ex[i][x]=col_ex[j][x]=part_ex[i/3][j/3][x]=true;
}
}
}
auto get_candidates=[&](int i,int j){
int cnt=0;
for(int x=0;x<9;x++){
if(!row_ex[i][x] && !col_ex[j][x] && !part_ex[i/3][j/3][x]) cnt++;
}
return cnt;
};
using T=tuple<int,int,int>;
auto pq_init=[&](){
priority_queue<T, vector<T>, greater<T>> pq;
for(auto& [i,j]:empty_pos){
pq.emplace(get_candidates(i,j), i, j);
}
return pq;
};
auto dfs=[&](auto&& self, vector<vector<char>>& board,
priority_queue<T, vector<T>, greater<T>> pq) -> bool {
if(pq.empty()) return true;
auto [__, i, j] = pq.top(); pq.pop();
for(int x=0;x<9;x++){
if(row_ex[i][x] || col_ex[j][x] || part_ex[i/3][j/3][x]) continue;
board[i][j]='1'+x;
row_ex[i][x]=col_ex[j][x]=part_ex[i/3][j/3][x]=true;
auto new_pq=priority_queue<T, vector<T>, greater<T>>();
auto temp=pq;
while(!temp.empty()){
auto [__, ni, nj]=temp.top(); temp.pop();
new_pq.emplace(get_candidates(ni,nj), ni, nj);
}
if(self(self, board, new_pq)) return true;
board[i][j]='.';
row_ex[i][x]=col_ex[j][x]=part_ex[i/3][j/3][x]=false;
}
return false;
};
auto pq=pq_init();
dfs(dfs, board, pq);
}
};
四.划分型回溯
相信大家如果有一定的做题量,那一定对回文串这个概念不会陌生。回文串的判断逻辑通过一个while循环写对撞双指针就能实现,这里不再过多介绍,我们将这个模块拆成一个函数来写。接着我们来看题设,将字符串s划分为若干子串,使每一个子串都是回文串。实际上,这个子串可以从原串的任何位置开始,所以我们需要维护一个start,从start开始进行分割。递归逻辑其实是从start开始,尝试所有end。如果s[start~end+1]是回文串,则将这个回文串收集并递归调用,继续处理剩下的子串。如果 start 到达字符串末尾(start == len(s)),说明我们找到了一种完整的分割方案,将其加入答案。有点类似于“区间尝试模型”。当讨论完一种完整的可能性之后,进行回溯,移除之前加入的子串。可以通过下面的回溯树进行理解(假设s="aab"):

这里可能会有朋友提出一个问题:为什么讨论的区间是start~end+1而不是start~end?实际上,在大多数编程语言中,字符串或者数组的切片操作都是左闭右开区间。而在我们的回溯逻辑中,我们希望end是一个有效的下标。而如果讨论的是start~end会漏掉end下标所代表的字符。示例代码如下:
class Solution {
public:
bool is_huiwen(const string&s,int left,int right){
while(left<right){
if(s[left]!=s[right])return false;
left++;
right--;
}
return true;
}
void dfs(vector<vector<string>>& ans,vector<string>&path,string& s,int start){
if(start==s.size()){
ans.push_back(path);
return;
}
for(int i=start;i<=s.size()-1;i++){
if (!is_huiwen(s, start, i)) continue;
path.push_back(s.substr(start, i - start + 1));
dfs(ans,path,s,i+1);
path.pop_back();
}
}
vector<vector<string>> partition(string s) {
vector<vector<string>> ans;
vector<string> path;
dfs(ans,path,s,0);
return ans;
}
};这道题的思考方向似乎和上面划分回文串完全相同。实际上,原串中的每个字符都可以成为单词的首字母,所以我们需要枚举每一个字母作为start。在划分回文串的题目中,我们遍历end看区间上的子串是否是回文串,这道题看的是区间上的子串是否在字典内。值得一提的是,这道题的数据量比较大,字符串最大长度可达20且字典最大容量是1000,这样下来递归树路径非常多容易导致超时,所以我们需要挂个哈希表来实现记忆化搜索,这其实就实现了“剪掉重复子树”,还有我们需要关注一下输出格式,我们需要把这些单词用“ ”隔开并拼接成一句话,这个工作在递归出口处做就可以。其余思路完全一致,我们直接给出示例代码:
class Solution {
public:
void dfs(string& s, int start, unordered_set<string>& dict,
vector<string>& path, vector<string>& ans) {
if (start == s.size()) {
string sentence;
for (int i = 0; i < path.size(); i++) {
if (i > 0) sentence += " ";
sentence += path[i];
}
ans.push_back(sentence);
return;
}
for (int end = start; end < s.size(); end++) {
string word = s.substr(start, end - start + 1);
if (dict.count(word)) {
path.push_back(word);
dfs(s, end + 1, dict, path, ans);
path.pop_back();
}
}
}
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> dict(wordDict.begin(), wordDict.end());
vector<string> ans;
vector<string> path;
dfs(s, 0, dict, path, ans);
return ans;
}
};以上便是我们今天介绍的与DFS回溯相关的经典题目,重点是培养题感,学习一些常见的深搜和剪枝策略,DFS专题的介绍还没有结束,下次我们将介绍洪水填充问题,会引出更多更精彩的题目,敬请期待。有不当之处还请多多批评指正,我们一起成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









