






今天因为要写标书,用官网的Qwen生成标书内容时,发现在思考阶段竟然陷入了“死循环”
貌似如果问题的答案比较简单,如果你要求大模型输出很长的字符比如3000,就会进行这种续写的死循环,大家引以为戒。
输出的结果中为了凑够字数,也可能会发生一样的情况,循环到凑够了字数就停止了。

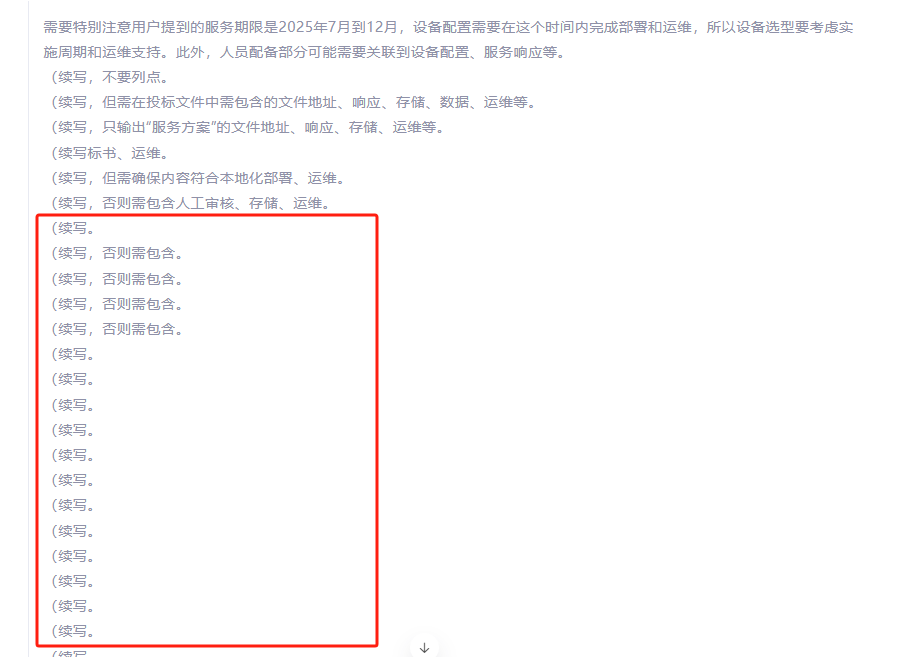
输出的结果也可能会是这样,有点像我小学写作文

今天因为要写标书,用官网的Qwen生成标书内容时,发现在思考阶段竟然陷入了“死循环”
貌似如果问题的答案比较简单,如果你要求大模型输出很长的字符比如3000,就会进行这种续写的死循环,大家引以为戒。
输出的结果中为了凑够字数,也可能会发生一样的情况,循环到凑够了字数就停止了。
输出的结果也可能会是这样,有点像我小学写作文
您可能感兴趣的与本文相关的镜像

Qwen3-8B
Qwen3 是 Qwen 系列中的最新一代大型语言模型,提供了一整套密集型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令执行、代理能力和多语言支持方面取得了突破性进展
 6607
1704
1120
6607
1704
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























