






 本文介绍了如何利用pandas的统计方法describe()来计算数据的众数及其频数。对于数值型数据,describe()提供8种统计指标;对于非数值型数据,返回4种指标。要统计数值型数据的众数频率,需要先将其转换为类别型数据,再应用describe()函数。
本文介绍了如何利用pandas的统计方法describe()来计算数据的众数及其频数。对于数值型数据,describe()提供8种统计指标;对于非数值型数据,返回4种指标。要统计数值型数据的众数频率,需要先将其转换为类别型数据,再应用describe()函数。
1.numpy统计函数
| max() | 最大值 |
| min() | 最小值 |
| ptp() | 极差 |
| mean() | 平均值 |
| var() | 方差 |
| std() | 标准差 |
| mode() | 众数 (返回一个dataframe格式的数据) |
| count() | 非空数目 |
| median() | 中位数 |
| cov() | 协方差 |
2.pandas统计方法describe()
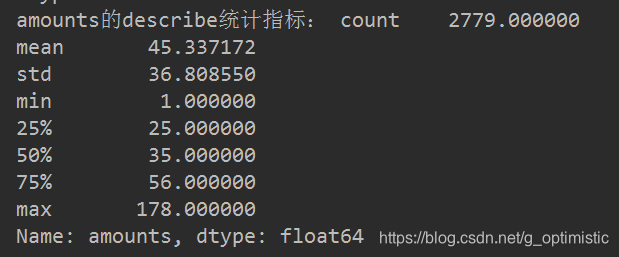
(1)数值型数据 返回8种指标
count mean std min 25% 50% 75% max
import pandas as pd
detail=pd.read_excel('./meal_order_detail.xlsx',sep=',',encoding='gbk')
print('amounts的describe统计指标:',detail['amounts'].describe())
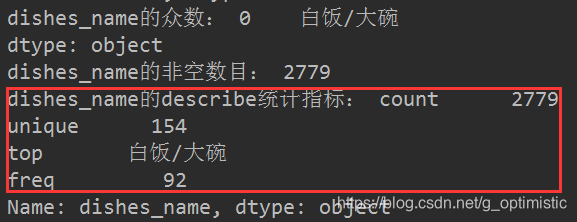
(2)非数值型数据 返回四种指标
count unique top freq
print(detail.dtypes)
# 选择dishes_name 类型为object
# 众数
print('dishes_name的众数:', detail['dishes_name'].mode())
print('dishes_name的非空数目:', detail['dishes_name'].count())
# 使用describe()进行非数值型数据统计分析
print('dishes_name的describe统计指标:', detail['dishes_name'].describe()) # 返回4种指标
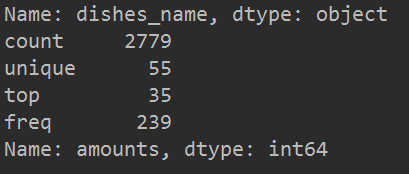
(3)统计数值型数据的众数出现的频数
先将数值型数据转换成类别型数据,然后用describe()进行统计
类型转换用astype()实现
detail['amounts'] = detail['amounts'].astype('category')
# 再进行describe()统计分析
print(detail['amounts'].describe())

















 3980
3980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









