



第15章 28 nm和14 nm FinFET中的模拟电路
卢卡斯·多勒、弗朗茨·库特纳、弗朗切斯科·孔扎蒂和帕特里克·托尔塔
15.1 引言
新工艺节点的引入总是伴随着专家们关于其在模拟和射频设计中可用性的讨论。由于转向FinFET设计,这一讨论涉及晶体管世界突然变得量子化的事 实。设计人员可以选择使用一个、两个或任意离散数量的晶体管并联或堆叠。
模拟尺寸缩放已不再可能。然而,将模拟和射频设计迁移到FinFET技术是 可行的。我们在测试芯片中证明了这一点,并且可以进一步指出,FinFET 中模拟和射频设计的困难并不在于晶体管的量子化,而在于光刻波长限制, 这导致金属层中需要双重甚至未来多重要图案化。增加的金属密度在寄生电 容、电阻和物理设计工作量方面的负面影响不容忽视。FinFET晶体管也被 称为三栅晶体管。
15.2 英特尔三栅极鳍式场效应晶体管技术
FinFET晶体管的栅极从三个侧面环绕沟道,如图15.1所示。三栅结构增强 了横向静电控制,使FinFET晶体管在饱和时表现出卓越性能

电流、漏电流和其他模拟参数,以及改进的短沟道效应[1](图15.2)。
为FinFET技术设计电路与平面技术的电路设计相对类似。区别在于通 过鳍片的并联连接来获得所需的晶体管宽度,以及通过器件堆叠来增加有效 长度。图15.3展示了在平面技术和FinFET技术中实现的一些晶体管的显微 镜图像。尽管电流源需要堆叠多达上百个晶体管,但其寄生电容足够小,不 会像平面CMOS那样降低性能(图15.4)。
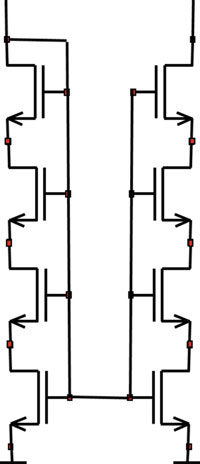
这些鳍片阵列的主要问题在于布局生成,因为所有鳍片都必须连接在一起。

在大电流或高频电路中必须特别注意。鳍式场效应晶体管自加热( FISH)可能是一个严重问题,因为鳍式场效应晶体管沟道到衬底的热阻远 高于平面CMOS,导致鳍片内的最高温度升高 [2]。此外,由于金属间距较 小,底层金属层的电阻以及寄生电容也增加了。
15.2.1 光刻技术与双重图案技术
双重图案技术是一类用于制造集成电路的光刻技术,旨在提高特征密度。该 技术对于14纳米工艺的底层金属层是必需的。
如图 15.5 所示,由于需要先打印一系列线条然后再进行切割,因此需要 多次光刻曝光。由于双重图案技术的应用,FinFET技术的布局复杂度增加。
一个布局被分解为两个光照掩膜(两种颜色),因此有效节距加倍。双重图 案技术带来了设计限制。当设计的关键层可以被拆分为两个分离的、高度规 律性的模式,并以可预测的方式对准时,双重图案技术的效果最佳。这意味 着产生类似折射光栅的布局是理想的,而布满对角线、折线以及层间万向孔 的设计则可能无法有效拆分。双重图案技术将对准问题引入到了关键层上, 而不是像以前那样存在于层与层之间,这可能会对设计性能和生产收率产生 影响。双重图案技术成本较高,因为它使用了两个光照掩膜来定义原本仅需 一个光照掩膜即可定义的层。这意味着需要购买更多的步进机以维持制造吞 吐量。对于模拟设计师而言,双重图案技术的缺点在物理设计中显而易见。
较高的金属密度和较小的金属间距导致更高的寄生电容和电阻。主要缺点在 于布局开发和优化所需的时间。(例如),为了降低28 纳米中的寄生电容, 可以通过简单地移动金属线以增加间距来轻松实现,但由于工艺离散化的影响,在14 纳米等更小的技术节点上实现这一点更加困难。
15.3 设计比较
在本节中,我们比较了电容数模转换器、两步式闪速ADC和西格玛‐德尔塔 ADC的平面设计与FinFET设计。我们分析了针对相似约束条件的设计,并 描述了电路实现方案如何受到技术的增强或限制。
15.3.1 数字IQ电容数模转换器
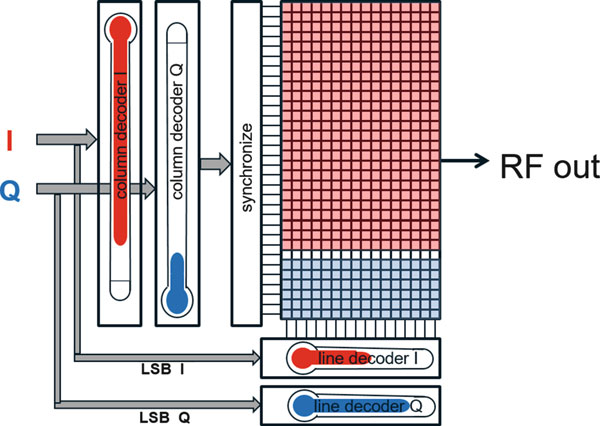
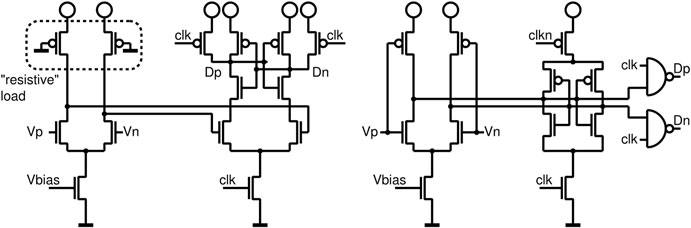
一种用于RFDAC的新架构在28 nm和14 nm工艺上并行开发。在这两种技术中, RFDAC均在测试芯片上实现并进行了测量[3]。该RFDAC为极化/数字IQ组合, 可在高效率的极化模式下运行,也可在高调制带宽的IQ模式下运行,后者适用 于DPLL无法在如此高的带宽下进行调制的情况。图15.6所示的数模转换器由 10位温度计码和5位二进制编码的电容单元组成的电容阵列构成,可直接为射频 发射机生成信号。
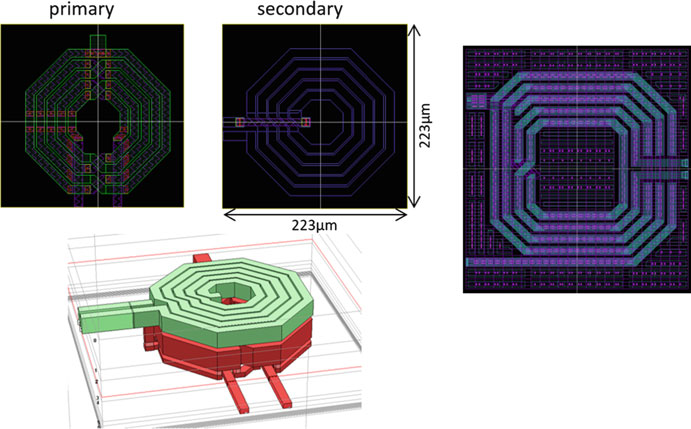
图 15.7展示了电容式RFDAC的数字特性。设计中的主要工作是使电容器的切换时序误差小于皮秒。该电容式RFDAC主要由电容器和逻辑单元构成,因此非常适合迁移到缩小的数字技术。
在1850 MHz和850 MHz下测得的总正弦波输出功率分别为14.2 dB m和13.5 dBm。在14纳米和28纳米工艺下的测量结果相似。在14纳米工艺 中可实现25%的功耗降低,这是由于数模转换器的数字架构所致。尽管输送 到输出端的功率必须保持相同,但开关数字信号的损耗显著减少。数模转换 器的面积减少了超过50%,但发射机的整体面积由输出端的匹配网络决定。
匹配网络中的变压器是占据主要面积的部分,其尺寸由所选频率下的匝数决 定。因此,整个发射机的总面积缩小了约25%(图15.8)。
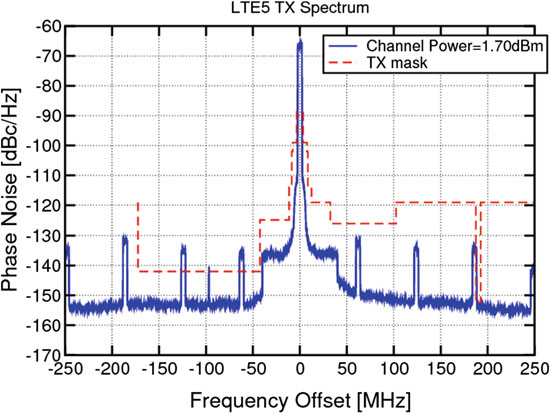
在IQ模式下,LTE5模式中测得的噪声基底极佳,为‐153dBc/Hz(见图 15.9)。在1850 MHz和850 MHz的LTE5模式下,进一步测得较低的误差矢量 幅度(EVM)分别为3%和1.5%。采用数字预失真后,在LTE20模式下的 EVM可降低至0.8%。图15.9中的周期性杂散是由数字路径中测试芯片RAM引起的伪影,因此可以轻松避免。预期通过更优的布局可改善噪声基底,因为电源 连接尚未完全优化。
15.3.2 两步式闪速ADC8位4Gs/s
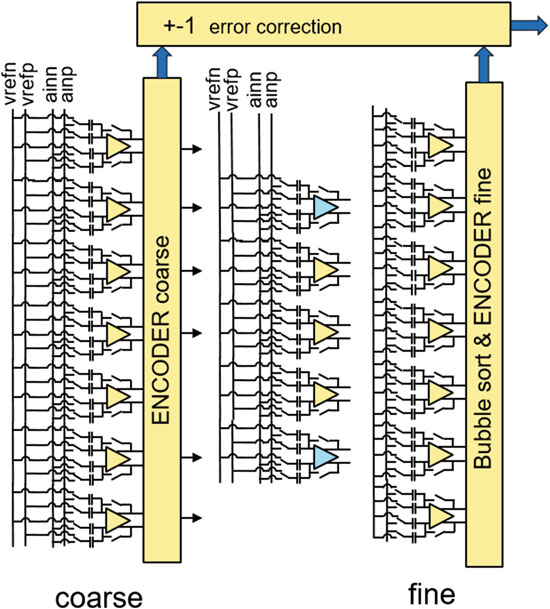
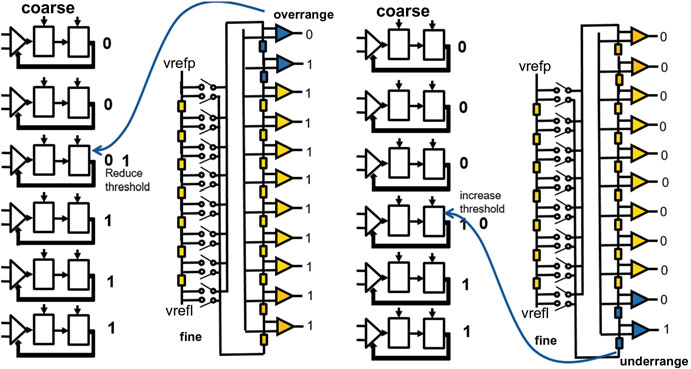
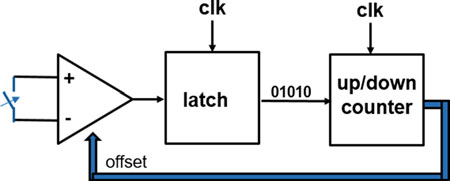
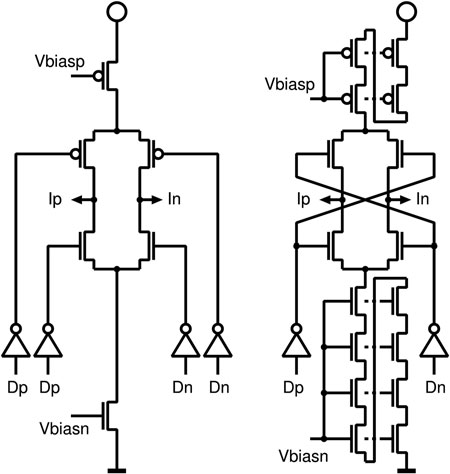
对于5G应用,需要带宽在GHz范围内的高速模数转换器。其基本架构在文献[4, 5]中有描述。模数转换器的分辨率主要受限于系统的功耗。对于该应用中8到9位分辨率已足够。同时在28纳米和14纳米工艺上开发了折叠式 模数转换器;其概念如图15.10所示。利用小型工艺技术,可以对每个比较器 的偏移进行数字校准,并且还开发了一种新的背景校准方法。
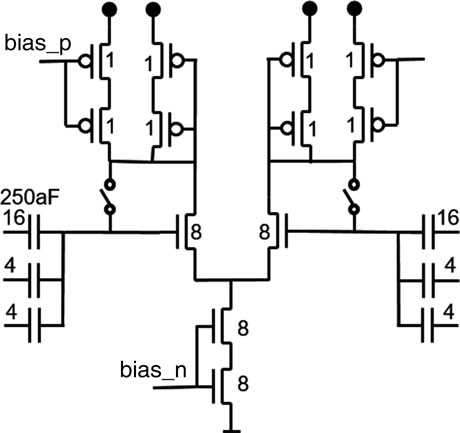
比较器是非常简单的差分级,后接一个针对低反冲调谐的锁存器。图15.11显示 了粗调阶段的比较器。
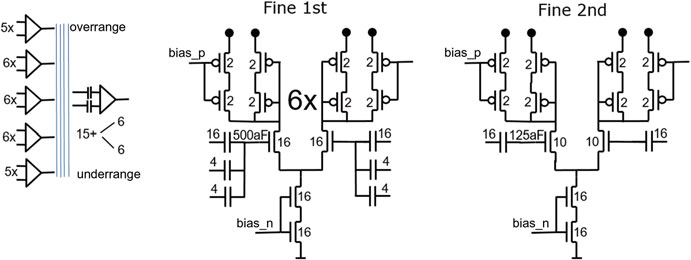
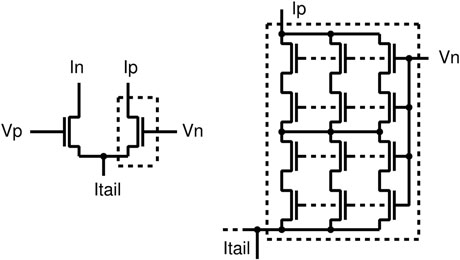
数字表示所使用的鳍片或电容器的数量。对于细调阶段,采用基于切片 的设计以简化布局。并非单独调整每个比较器的尺寸,而是使用统一尺寸, 并联切换以根据噪声要求产生所需的电容和电流(图15.12)。
在14 纳米的前置放大器中,由于电源电压与阈值电压的比值更优,可以堆叠更多的 器件。利用小型工艺技术,能够对每个比较器的偏移进行数字校准(图15.13和 15.14)。
粗调阶段的比较器首先进行失调校准[4]。剩余误差通过监测粗调和细调结 果之间的差值来纠正。当产生欠量程或超量程信号时,明显发生了误差。在14 纳米工艺下的实现更加紧凑且速度更快。仿真表明,在相同的功耗下,14纳米 工艺中的采样率可以提高一倍。因此,在28纳米工艺中,模数转换器在15 mW下最高可运行至2Gs/s,而在14纳米工艺中则可达4Gs/s。在14纳米工艺中, 面积缩小了50%。已有28纳米工艺下的测量结果,显示在奈奎斯特频率下有效 位数可达7.2 ENOBs。
15.3.3 三阶连续时间西格玛-德尔塔ADC
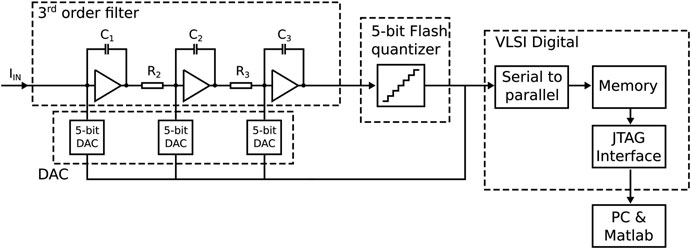
作为最后一个对比示例,连续时间Sigma Delta ADC也在两种工艺技术中进行了开发和测量。该模数转换器是一个良好的测试平台,可用于探索和比较技术性能的提升或限制,因为其功能模块涉及纯模拟、混合模式和纯数字电路。有关类似模数转换器设计的一些文献可参见[6, 7]。
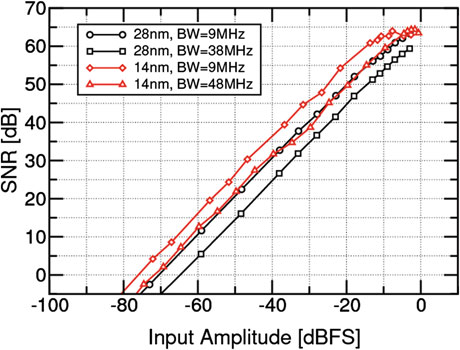
在本研究中,我们比较了两种在反馈配置中的相似模数转换器设计。模数转换器架构如图15.15所示。通过改变滤波器系数,该模数转换器可重新配置,以分别覆盖9兆赫和47兆赫两种带宽模式。采用低分辨率的5位闪速量化器和三个电流导向反馈DAC来闭合环路并对模拟输入信号进行数字化。在两个设计中,均使用一个高速数字模块来采集输出数据,并通过4路并行化后经32位总线存储到芯片上实现的96Kb存储器中。通过JTAG接口在个人计算机上读取并评估存储器内容。
在模块级,该滤波器由三个级联积分器构成,这些积分器实现有源放大器,并在第三级和第二级之间有一个谐振器。

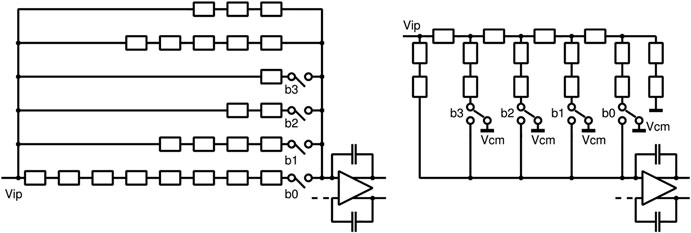
带宽模式选择通过电容重编程实现。为了调节由制造失配引起的RC乘积,滤波器中的每个电阻都进行了数字修调。在平面28纳米变体中,使用多晶硅层构建单位电阻。在鳍式场效应晶体管14纳米变体中,采用专用的电阻层,该层会向衬底和地引入显著的寄生效应。增加的寄生电容限制了器件的最大带宽。为了克服这一限制,设计从纯并联改为如图15.16所示的R2R实现。由于尺寸和布局的影响,设计中尽量减少了电阻的使用。
在滤波器中,第一个放大器在噪声和线性度方面具有非常严格的要求。
为了实现这一点,输入差分对的尺寸非常大。通常在平面技术中,两个差分对晶体管会被拆分为多个较小的晶体管,这些晶体管并联连接并共享相同的长度。在14纳米的实际实现中,通过使用包含多个堆叠晶体管的已表征子电路,力求减少布局和设计中的器件数量。这会引入新的节点,如图15.17所示。
由此产生的晶体管簇可被视为一个等效器件。当上层晶体管处于饱和状态时,即可确保该晶体管簇的饱和条件。尽管此条件可确保晶体管簇的饱和行为,但可能导致过度设计。
将多个器件连接成网格网络的优势在于,与平面技术相比,电流不会流入单根导线中。这会因功耗和鳍式场效应晶体管自加热(FISH)而自动放宽可靠性要求。簇器件的缺点是需要仿真的元件数量和节点数量急剧增加。
滤波电容器已采用横向电容实现。随着技术的发展,金属线之间的间距减小,如图15.18所示,实现目标值所需的面积大大减小。由于为所需最低带宽设计的滤波电容约占ADC面积的40%,该技术对总ADC面积缩小起到了显著作用。
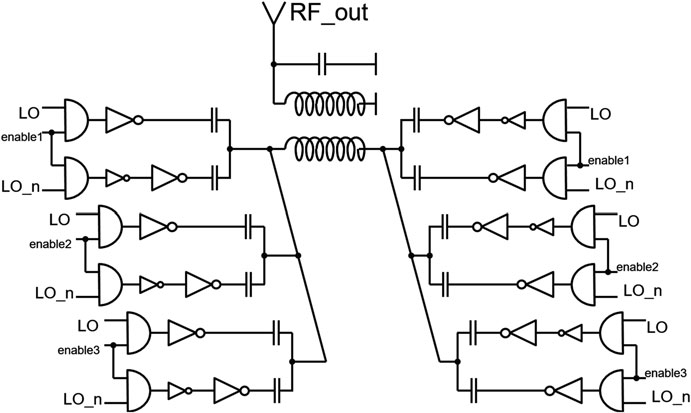
在14纳米工艺中,由于需要连接更小的晶体管,金属互连的宽度和高度减小,导致电阻增加。为了确保模数转换器的正常性能,必须使用低阻金属来布线量化器、数模转换器和滤波器之间的线路。这意味着在14纳米工艺中需要使用高层金属。如前所述,14纳米的电流转向DAC单元得益于开关的阈值电压相对于电源电压更低。这些单元仅采用NMOS开关和简化的驱动逻辑实现(图15.19)。在两种工艺中,电流源均较长,并由多个晶体管串联而成。
这导致14纳米设计的布局和仿真时间投入更大。
由于14纳米工艺具有更优的阈值电压与电源电压之比,量化器设计也更为容易。在14纳米工艺中,级联前置放大器加锁存器的实现相比28纳米能够获得高得多的增益,因为前置放大器中可以采用CMOS输入,如图15.20所示。
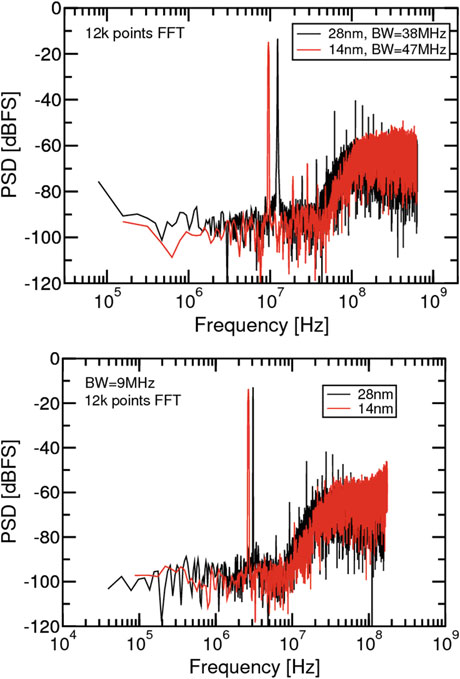
量化器的数字化输出被收集到数字超大规模集成电路领域的存储器中。如预期所示,图15.15中在14纳米鳍式场效应晶体管工艺下的数字VLSI模块在所有方面均显著优于平面设计。
实测性能的比较如图15.21和15.22以及表15.1所示。
尽管这两个模数转换器并不完全相同,但它们表现出类似的性能,因此可以进行比较。更为重要的是,在这两种设计中,仿真结果与测量结果都非常吻合。在14纳米工艺下,提取的顶层设计视图的仿真由于包含大量无法忽略或简化/缩减的网表元件,导致仿真耗时显著增加。
| V DD [V] | BW [MHz] | 电流 [mA] | DR [dB] |
|---|---|---|---|
| 28 纳米 | 1.1 | 9 | 6.75 |
| 14 纳米 | 1.0 | 9 | 8 |
注 :表格中数据可能存在排版错位,原始文本未明确字段对应关系。根据上下文推断,应为两组数据分别对应28nm与14nm工艺下的不同带宽(9MHz 和 47MHz)条件下的性能参数。
15.4 结论
针对射频收发器的关键高性能模数和数模构建模块已在英特尔14纳米三栅极鳍式场效应晶体管和28纳米平面技术中设计完成。已确定其在性能上的竞争优势,并识别出在具有竞争力的实施时间表下实现商业化的障碍。

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









