







一、程序提速的方法
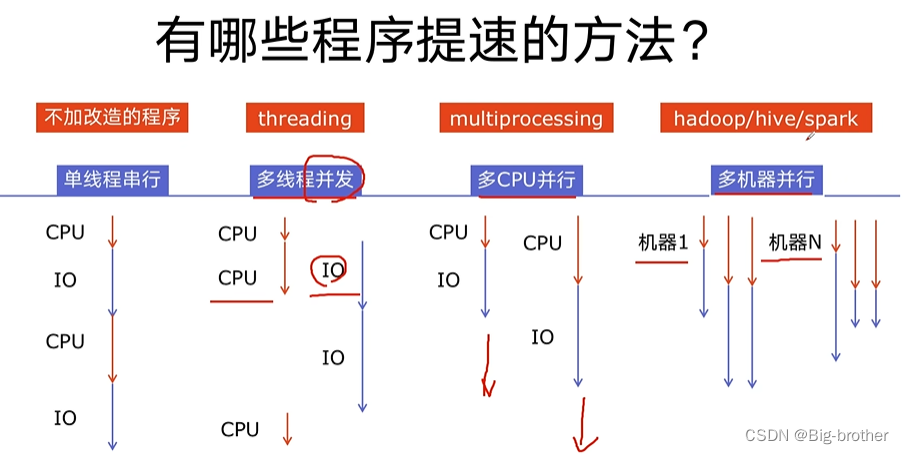
二、python对并发编程的支持
- 多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成;
- 多进程:multiprocess,利用多核CPU的能力,真正的并行执行任务;
- 异步IO:asyncio,当线程比较多时,切换线程也会占用CPU资源,可在单线程中利用CPU和IO同时执行的原理,实现函数异步执行;
- 使用Lock对资源加锁,防止冲突访问;
- 使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式;
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交,等待结果、获取结果;
- 使用subprocess启动外部程序的进程,并进行输入输出交互;
python子进程的启动方法:fork与spawn,参考子进程启动方式
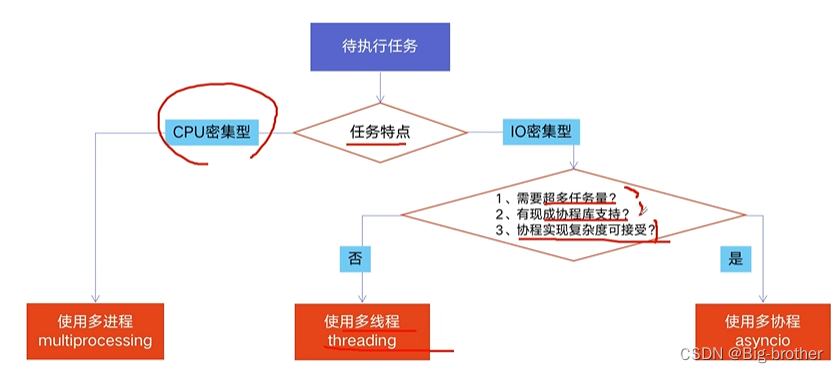
三、python并发编程的三种方式
3.1 3种方式的区别和选择
多线程Thread,多进程Process,多协程Coroutine。

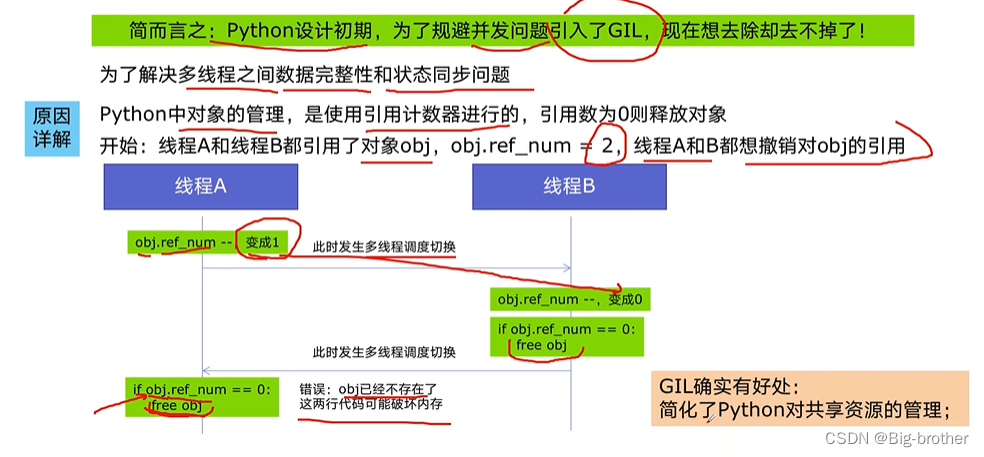
3.2 GIL
四、实战
4.1 多线程

4.1.1 多线程网页爬虫示例代码
- blog_spider.py
import requests
from bs4 import BeautifulSoup
urls = [
f"https://www.cnblogs.com/sitehome/p/{page}"
for page in range(1, 50 + 1)
]
def craw(url):
#print("craw url: ", url)
r = requests.get(url)
return r.text
def parse(html):
# class="post-item-title"
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
if __name__ == "__main__":
for result in parse(craw(urls[2])):
print(result)
- producer_consumer_spider.py
import queue
import blog_spider
import time
import random
import threading
# 生产者
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.current_thread().name, f"craw {url}",
"url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2))
# 消费者
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name, f"results.size", len(results),
"html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
#创建生产者线程
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue),
name=f"craw{idx}")
t.start()
fout = open("02.data.txt", "w")
# 创建消费者线程
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout),
name=f"parse{idx}")
t.start()
4.1.2 线程安全问题
线程安全指某个函数在多线程环境中被调用时,能够正确的处理多个线程之间的共享变量,使程序功能正确完成。由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全。
使用Lock解决线程安全:
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name,
"取钱成功")
account.balance -= amount
print(threading.current_thread().name,
"余额", account.balance)
else:
print(threading.current_thread().name,
"取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()
4.2 多进程

4.3 异步IO(协程)
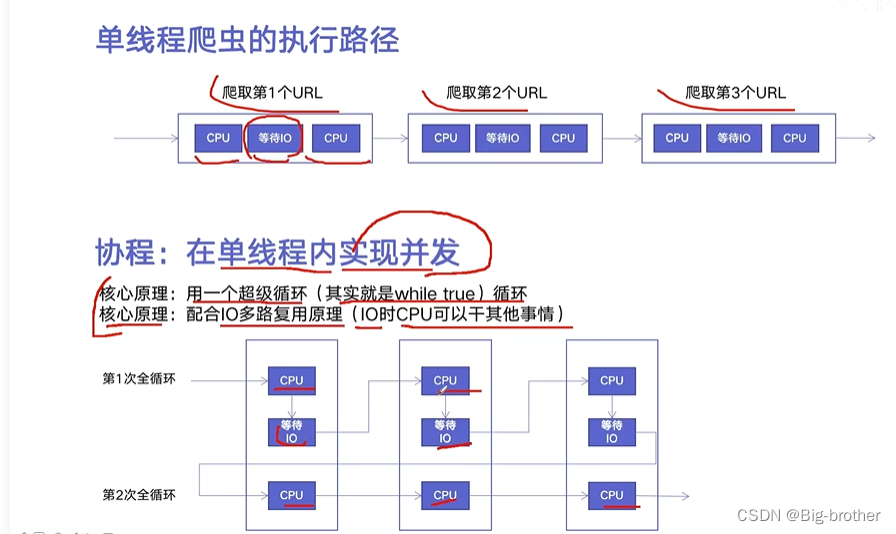
使用协程的时候,要确保使用的库要支持协程,比如requests库不支持协程,可使用aiohttp.
import asyncio
import aiohttp
import blog_spider
# 信号量控制协程的并发度
semaphore = asyncio.Semaphore(10)
async def async_craw(url):
async with semaphore:
print("craw url: ", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
await asyncio.sleep(5)
print(f"craw url: {url}, {len(result)}")
# 创建时间循环
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog_spider.urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
4.4 多线程之间通信
多线程之间要完成的任务是相互独立互不干扰的话,那么线程之间是不需要进行通信的,自己干自己的事就行。但是如果多线程之间要进行合作,那么就必须要进行线程通信。
4.4.1 使用共享变量通信
特点:使用共享变量通信的方式是线程不安全的,一般要结合线程锁使用。
from threading import Thread, Lock
from time import sleep, time
# 两个共享变量
urls = [] # 任务列表,用于存放要爬取的文章详情url
is_finished = False
lock = Lock()
def get_detail_content(urls, name):
global is_finished
print("%s开始爬取文章内容" % name)
while not is_finished or len(urls): # 如果生产者没有生产完或者生产者生产完了但消费者没有消费完就从urls取出url进行爬取
try:
with lock:
url = urls.pop()
sleep(0.001) # 爬取1个内容页花0.001秒
print("%s 文章:%s 爬取结束" % (name, url))
except: # 这里是为了防止消费者消费太快,当生产者还在生产但urls元素为0时,pop会报错。此时应该重新判断urls中是否有元素
continue
print("所有文章内容爬取结束")
def get_detail_url(urls):
global is_finished
print("开始爬取文章列表页")
art_id = 10000 # 假设共有10000个文章url
page_url_num = 100
start_id = 1
while start_id < 10000:
end_id = start_id + page_url_num
for id in range(start_id, end_id): # 假设有100页列表页,每一页有100个url,共10000个url
url = "http://www.zbpblog.com/blog/%d.html" % id
with lock:
urls.append(url)
sleep(0.01) # 爬一个列表页花0.01秒
start_id = end_id
with lock:
is_finished = True
print("文章列表页爬取结束")
if __name__ == "__main__":
st = time()
print("主线程负责计时")
# 创建1个生产者线程
producer = Thread(target=get_detail_url, args=(urls,))
consumers = []
for i in range(3): # 创建3个消费者线程
name = "Thread %d" % (i + 1)
consumer = Thread(target=get_detail_content, args=(urls, name))
consumers.append(consumer)
producer.start()
sleep(0.1) # 睡0.1秒是为了让生产者先生产些链接到urls中
for consumer in consumers:
consumer.start()
producer.join()
for consumer in consumers:
consumer.join()
et = time()
print("任务结束,耗时:%.2f" % (et - st))
4.4.2 使用队列通信
Queue相比于普通的list结构而言,Queue是线程安全的,而list不是线程安全的。原因是Queue内部使用了锁和条件变量来进行线程同步,但是list没有用到线程同步技术。
备注:
- 设置进程不等待消费者线程和生产者线程执行结束而结束,所以对消费者和生产者线程使用 setDaemon(True) 设置为守护线程;
- 进程需要等待任务队列中的任务被执行完才结束,使用队列的join()方法, 必须配合task_done()方法使用
from threading import Thread
from time import sleep, time
from queue import Queue
urls = Queue(500)
is_finished = False
def get_detail_content(urls, name):
print("%s开始爬取文章内容" % name)
while True:
url = urls.get()
sleep(0.001)
urls.task_done() # 标记这一次取出来的url任务已经执行完
print("%s 文章:%s 爬取结束" % (name, url))
print("所有文章内容爬取结束")
def get_detail_url(urls):
global is_finished
print("开始爬取文章列表页")
art_id = 10000 # 假设共有10000个文章url
page_url_num = 10
start_id = 1
while start_id < 10000:
end_id = start_id + page_url_num
for id in range(start_id, end_id):
url = "http://www.zbpblog.com/blog/%d.html" % id
urls.put(url)
sleep(0.01)
start_id = end_id
# 生产者全部生产完成标志位
is_finished = True
print("文章列表页爬取结束")
if __name__ == "__main__":
st = time()
print("主线程负责计时")
producer = Thread(target=get_detail_url, args=(urls,))
producer.setDaemon(True) # 设置为守护线程
consumers = []
for i in range(10):
name = "Thread %d" % (i + 1)
consumer = Thread(target=get_detail_content, args=(urls, name))
consumer.setDaemon(True) # 设置为守护线程
consumers.append(consumer)
producer.start()
for consumer in consumers:
consumer.start()
while not is_finished:
urls.join() # 等待urls队列的任务被执行完才往下执行
et = time()
print("任务结束,耗时:%.2f" % (et - st))
4.4.3 线程同步
线程同步是为了解决多线程编程中,由于竞争使用资源或修改变量而造成数据不一致的问题。
(1)使用锁进行同步,比如互斥锁Lock、重入锁RLock
- 缺点:
- 加锁和释放锁会消耗时间,所以锁会影响程序性能
- 锁可能会引起死锁
(2)使用条件变量进行同步
条件变量必须要配合互斥锁使用,因为条件变量是一种多线程竞争的共享资源。通过条件变量可以实现等待和通知的机制。
cond = Condition() # 创建一个条件变量
cond.acquire() # 给条件变量上锁
cond.wait() # 等待,会阻塞下面的代码执行,当其他线程调用notify的时候才会被唤醒
do_something()
cond.notify() # 通知和唤醒其他使用了条件变量cond的线程
cond.release()
from threading import Condition,Thread
cond = Condition()
a_say = [1,3,5]
b_say = [2,4,6]
class A(Thread):
def __init__(self,cond,say):
super(A,self).__init__(name="A")
self.cond = cond
self.say = say
def run(self):
self.cond.acquire()
for i in range(len(self.say)):
print("%s say %d" % (self.name,self.say.pop(0)))
self.cond.notify() # A说完就要通知B,让B开始说
if len(self.say):
self.cond.wait() # A说完就不能在说,而是等待B说完,等B通知到A,A才能继续说
self.cond.release()
class B(Thread):
def __init__(self,cond,say):
super(B,self).__init__(name="B")
self.cond = cond
self.say = say
def run(self):
self.cond.acquire()
for i in range(len(self.say)):
self.cond.wait() # 一开始是A先说而不是B先说,所以一开始B是处于等待状态
print("%s say %d" % (self.name,self.say.pop(0)))
self.cond.notify() # B说完就要通知A,让A继续说
self.cond.release()
if __name__=="__main__":
a = A(cond,a_say)
b = B(cond,b_say)
b.start() # 必须让b线程先启动,a后启动,如果a先启动,那么a会在b没有执行wait()的情况下执行notify(),所以这个notify()通知相当于无效。之后a执行wait().b也执行wait()双方都处于等待,于是这个进程就卡住
a.start()

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









