







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python爬虫抓取网络小说《伏天氏》的章节内容,并将其保存为TXT文件。通过分析XPath表达式获取章节链接,结合Python代码实现批量下载,详细步骤与代码展示确保了数据抓取的实现。
本文介绍了如何使用Python爬虫抓取网络小说《伏天氏》的章节内容,并将其保存为TXT文件。通过分析XPath表达式获取章节链接,结合Python代码实现批量下载,详细步骤与代码展示确保了数据抓取的实现。
原文链接:https://yetingyun.blog.youkuaiyun.com/article/details/107916769
创作不易,未经作者允许,禁止转载,更勿做其他用途,违者必究。
利用 Python 爬虫爬取网络小说保存到txt,熟悉利用 Python 抓取文本数据的方法。
以爬取《伏天氏》这本小说的章节内容为例,目标url:http://www.xbiquge.la/0/951/
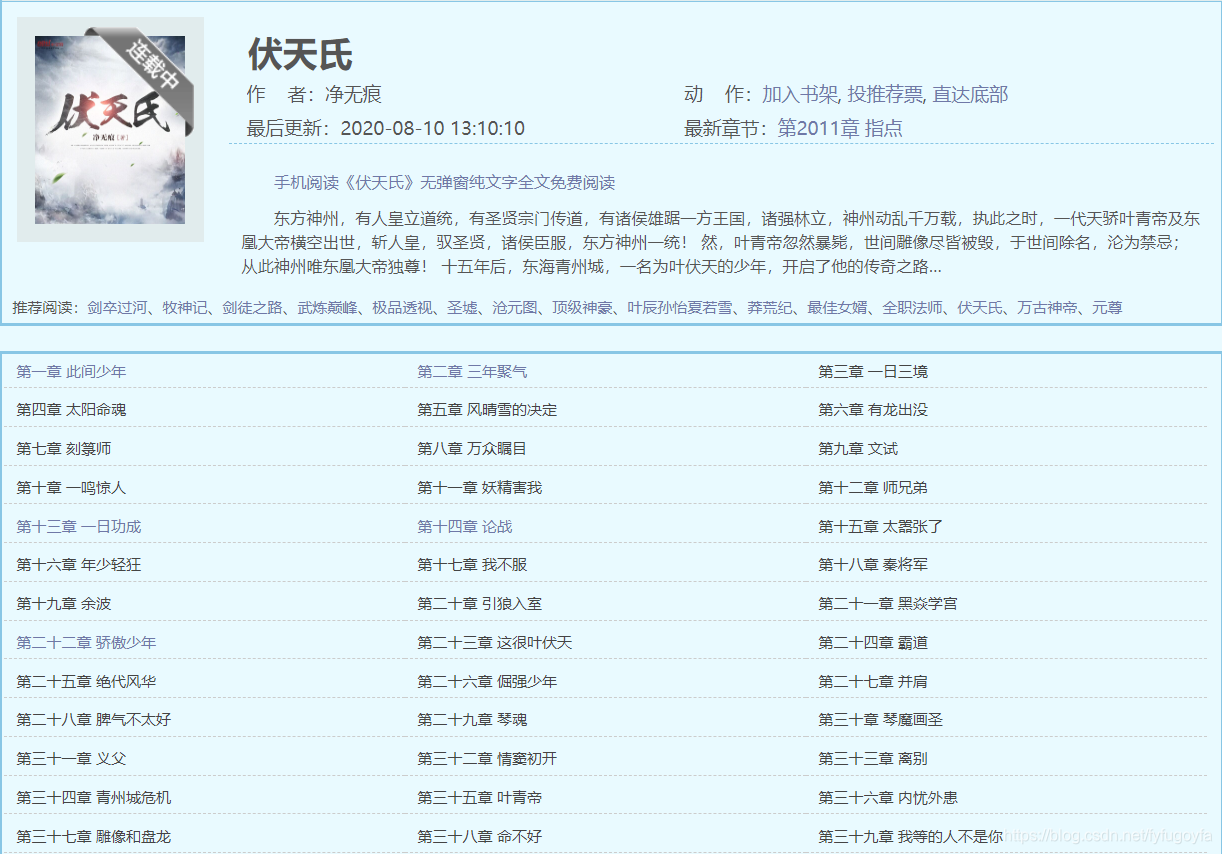
选取其中某一章,检查网页,可以找到这本小说所有章节的链接和名称。
写出xpath表达式提取出href里的内容://div[@id=“list”]/dl/dd/a/@href
分析网页可得,提取出来的内容里每个元素前面应加上 http://www.xbiquge.la 得到的才是是每个章节真正的链接

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2979
2979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









