




本人特别爱看网络小说,但是呢,有些小说网站的弹窗广告啊、悬浮广告太烦人,正好最近在研究Python,就来试试利用Python把小说站的小说爬下来,并保存到txt文件里。这样就可以直接使用手机打开txt来看了。并且呢,我也能熟悉利用python抓取文本数据的方法。
以爬取靠谱小说网的《伏天氏》这本小说的章节内容为例,目标url:http://www.kpxsw.com/0_479.html
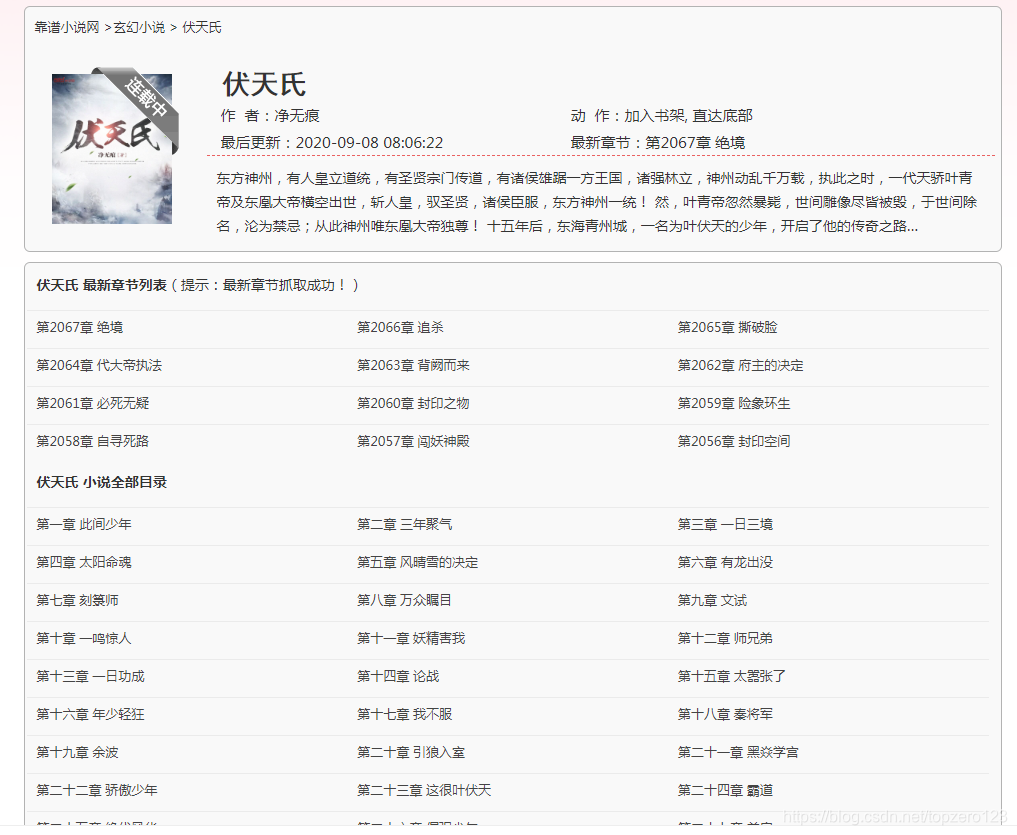
第一步:选取文章列表其中某一章,检查网页,可以找到这本小说所有章节的链接和名称。
写出xpath表达式提取出href里的内容://div[@id=“list”]/dl/dd/a/@href
分析网页可得,提取出来的内容里每个元素前面应加上 http://www.kpxsw.com 得到的才是是每个章节真正的链接
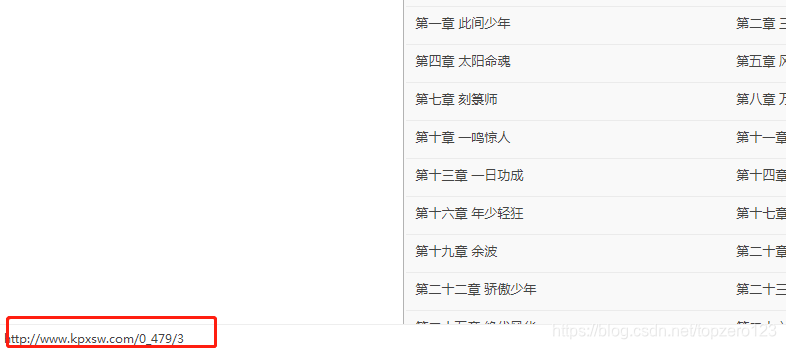
第二步:接下来编写抓取章节的代码,抓取所有章节的链接,代码如下:
def get_urls():
url = "http://www.kpxsw.com/0_479.html"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9493
9493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









