 DeepSeek V3.2发布:性能对标Gemini Pro
DeepSeek V3.2发布:性能对标Gemini Pro




DeepSeek V3.2 正式版模型重磅发布
它不仅仅是性能的又一次迭代,更是一次革命性的突破:DeepSeek V3.2 模型在数学、编程(A的性能)等方面,已全面领先于GBT模型的第一梯队。更令人振奋的是,根据官方和实测数据,DeepSeek V3.2 Speciale 模型在多项评测指标上,整体追平了全球性能最强大的模型 gemini 3.0 Pro!
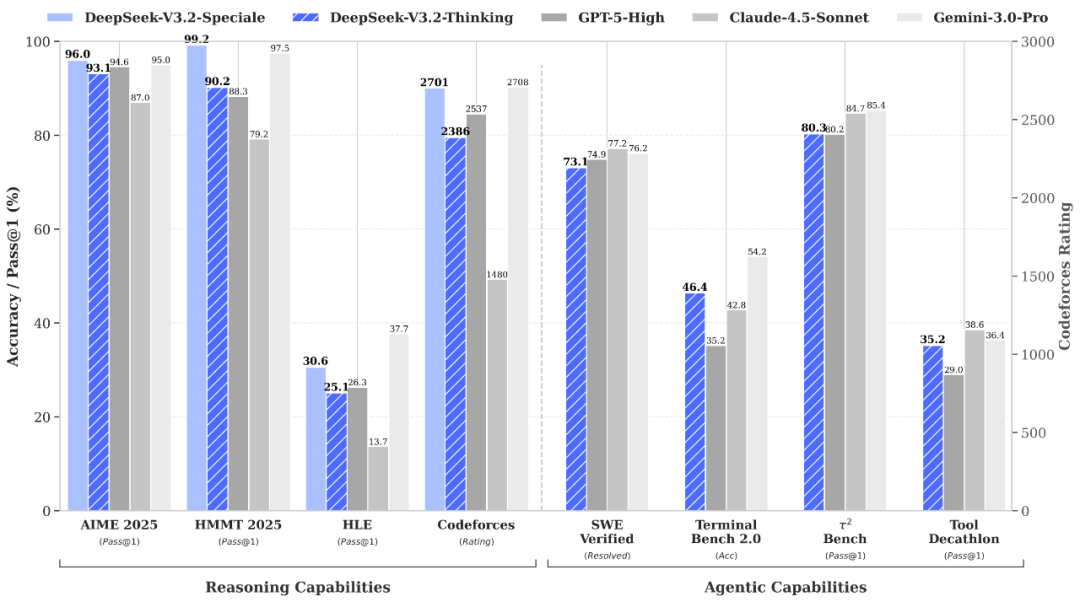
但最关键的是什么?性价比! DeepSeek V3.2 模型的价格,不到 Gemini3.0 的五分之一,不到 GPT 5.1 模型的四分之一,可以说是真正的“性价比拉满”。
国产大模型终于打破了在线模型的垄断地位,并凭借自主技术创新,为中国大模型乃至整个开源大模型界都注入了一针强心剂。如果你正在寻找全球顶尖性能、且完全开源、成本极低的基础模型,DeepSeek V3.2 绝对是你的首选!
技术深度剖析:V3.2 如何实现性能飞跃?
DeepSeek V3.2 的成功,并非偶然,而是建立在一系列扎实的技术积累之上。在过去的半年里,DeepSeek 团队通过保持更快的创新速度,不断进行自主技术创新,以对抗国外大模型厂商深厚的技礎基电和海量数据。
1. 成本革命:DSA 吸疏注意力机制的威力
早在两个月前发布的 DeepSeek V3.2 Exp实验版模型中,就首次提出了 DSA(吸疏注意力机制)。这项机制实现了在维持模型性能不变的情况下,将模型推理和训练成本报价降低 50% 以上。成本的巨大优化是 V3.2 能够提供极致性价比的基石。
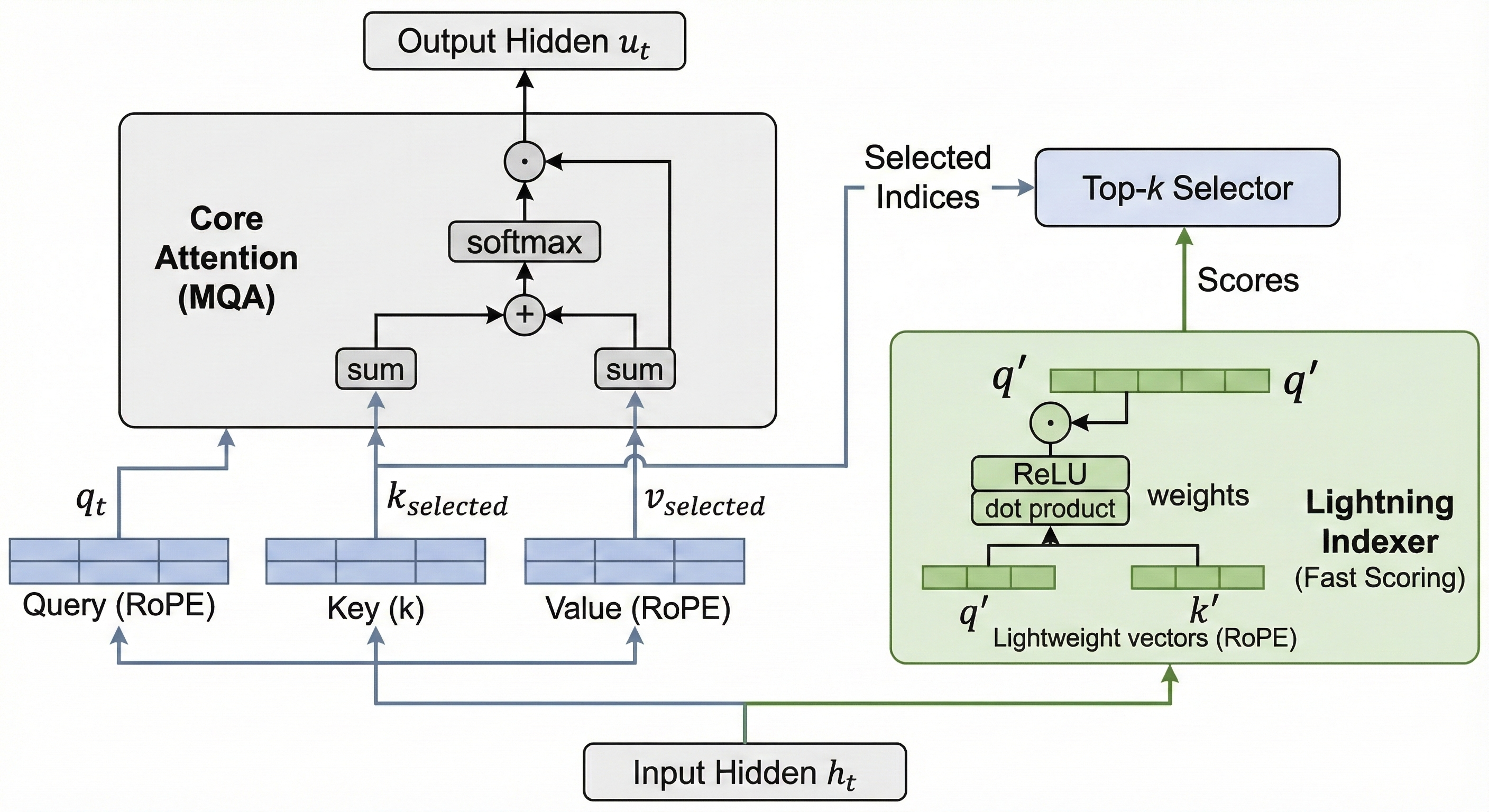
2. 训练升级:GRPU框架与大规模Agent数据
DeepSeek V3.2 正式版在实验版的基础上,引入了更高级别的训练框架和数据策略:
- 可拓展的 GRPU 训练框架:为了解决 GRPO 在长期训练过程中不稳定的问题,V3.2 创新性地引入了无偏 KL 估计和 OF policy 序列研,搭配 GRPU 框架,帮助模型突破性能极限。
- Agent 任务数据创建流水线:V3.2 首次提出了大规模合成 Agent 任务数据创建流水线。依靠 1800 多组智能体以及 85000 多组提示词,创建了海量的训练数据,并通过海量强化学习的后训练大力出奇迹。
正是这些技术积累,让全新一代 DeepSeek V3.2 模具几乎容纳了此前全部的技术创新,并提供了与 Gemini3.0 Pro 模型一决高下的资本。
核心性能实测:编程、数学、Agent能力全面对标顶尖水平
DeepSeek V3.2 在关键的生产力领域展现出了令人震惊的能力提升。
编程能力:思考链更清晰,千行代码信手拈来
根据官方数据,DPS V3.2 在编程、数学和 Agent 等领域均达到了 GPT-5 模型的水平。
- 巨大提升:相较于上一代模型,V3.2 的编程性能有巨大提升。
- 意愿增强:模型的编程意愿明显提升,思考链更加简单清晰。
- 效率革命:一次硬编写上千行代码已成了家常便饭。
- 综合素质:模型的前端审美、指令跟随能力和代码审查能力也进步显著。
尽管在物理遵循、项目代码逻辑理解方面,它与顶尖大模型仍存在 10% 左右的性能差距,但其核心优势在于更低的成本和完全开源,使其在实际开发中极具竞争力。
此外,DeepSeek V3.2 也已全面接入了 Claude Code,开发者只需将模型名称改为 DeepSeekk Reasoner 即可无缝调用 V3.2 模型。
Agent 能力:引入“边思考边调用工具”模式
DeepSeek V3.2 模型的 Agent (AG) 性能得到了巨大的提升,与 Gemini3.0、Claude 3.5 等模型的差距已不到 5%。
为了实现这一突破,DeepSeek 引入了思考模式下的工具调用功能。这意味着模型在单任务调用中可以保持多步工具调用思考链记忆。
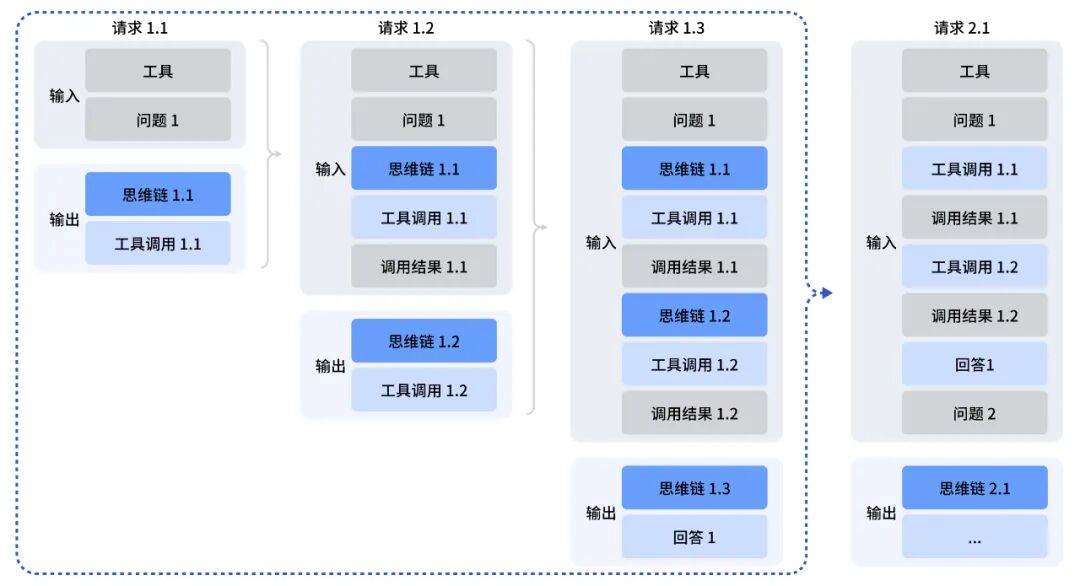
这就像人类一样,可以一边思考,一边调用工具。
这一创新大幅提升了模型多步调用工具的前后一致性,显著增强了 Agent 的性能。
实战检验:复杂 Agent 系统的基座模型
在团队测试中,将 DeepSeek V3.2 作为基座模型带入基于 Banana 的 AIPPT Agent 和 Aentic RAG 本地知识库检索系统等复杂的 Agent 架构中时:
- 性能对齐:无论是多 PPT 的任务拆解、自主提示编写,还是外部工具调用,都达到了和 gemini 3.0 Pro 的同等水平。
- 精度提升:在最复杂的知识库检索问答架构中,切换为 V3.2 之后,无论是用户意图理解的准确率,还是检索关键词提取的准确率,或是 Agent 调用的准确率,以及长文档编写的性能,都得到了显著的提升。
可以毫不夸张地说,DeepSeek V3.2 是目前国内被团队公认为 Agent 技能最好的基座模型。
大胆的尝试:DeepSeek V3.2 Speciale——挑战复杂问题的终极利器
除了面向生产力环境的 V3.2 正式版之外,DeepSeek 本次还同步开源了一款实验性质的模型:DeepSeek V3.2 Speciale。
这是一个非常大胆的尝试,Speciale 模型的定位是通过更长的思考链来解决更加复杂的问题。
Speciale 模型的训练秘籍:
- 纯推理数据训练:Speciale 模型在训练过程中采用了纯推理数据。
- 解除推理长度限制:它放宽了普通模型都会有的推理长度惩罚力度,使其更擅长通过长思考来解决问题。
- 自验证数学推理:同时引入了 DeepSeek math V2 模型提出的自验证数学推理训练法,借此来突破数学能力的极限。
最终,DeepSeek V3.2 Speciale 模型在各项主流评测数据上,无论数学、编程还是 HLE 性能,均达到了 gemini 3.0 Pro 模型的同等水平。实测表明,Speciale 模型确实达到了 MO 金牌级别的水平,能够完美解决复杂的数学和编程问题。
注意:目前 Speciale 模型仍处于实验阶段,虽然它擅长解决复杂的数学和代码问题,但无法很好地应对普通的对话问题。但 Speciale 模型的出现,也预示着基于该技术积累的下一代全新 DeepSeek 模型,很可能在不久的将来正式发布。
结语:开源的力量与学习资源
在 ChatGPT、Claude、Gemini 几乎统治整个大模型技术领域的今天,DeepSeek V3.2 模型的开原无疑是一股清流。它让我们真正看到了技术创新带来的大模型性能革命。
目前,DC V3.2 和 Speciale 两款模型的 API 已经全面上线,模型的权重也已全面开源。大家登录官网即可尝试。
如果你想要进一步深入系统地学习大模型技术、加入赋范空间 免费获取 DeepSeek V3.2 学习资料、模型部署和 Agent 开发教程。
我们期待 DeepSeek V3.2 的开源,能为国产大模型的发展带来更多的支持和突破。

















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









