



还在为一堆复杂的PDF、CAD图纸头大吗? 尤其是看合同、审票据、扒工程图...光是想想就“CPU过载”了!
最近多模态大模型(尤其是能看懂图片表格)杀疯了! 它们在“高精度表格、公式、CAD图字符&语义混合识别”方面表现超神,用在专业领域文档的合规性审核上简直了。
但是!问题来了,自己训练一个模型,对成本、技术的要求太高了,直接调用,又达不到理想的效果...
01 RAG是PDF理解低成本落地的实用思路
所以,从成本和落地效率的角度来看,检索增强生成(RAG)绝对是非常“轻量级”+“务实”的方案。
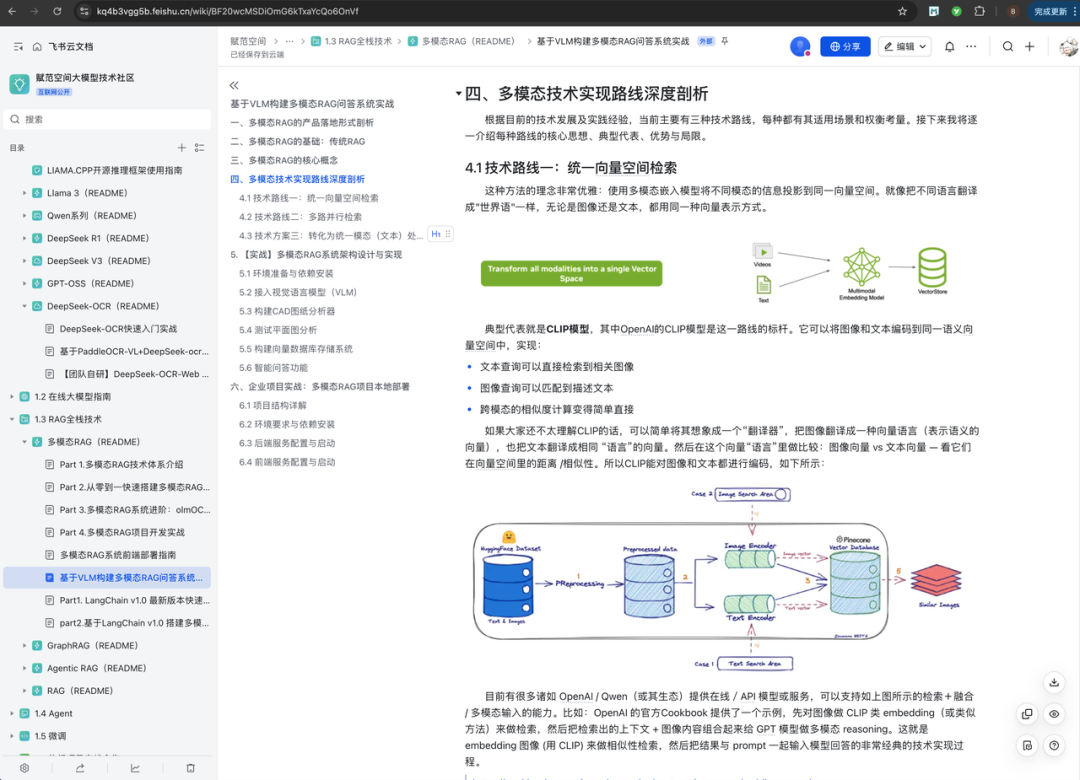
今天,我们就来0-1带你搭建一个能自动解析多模态PDF、CAD、工程图纸和复杂架构原型图的多模态RAG系统!源码➕文字视频教学内容已📦链接自取⬇️
https://kq4b3vgg5b.feishu.cn/wiki/space/725779442539157916402 企业落地的三大难点
当前的多模态识别,核心难点还是在于比较复杂的图片识别(比如包含各种图表的pdf及CAD、复杂架构原型图等),主要有以下几个难点
难点一:无法识别
图表尤其是像CAD工程图,包含各种长宽数据、小字、符号等元素的精准识别,传统OCR是很难去做的,大多数情况咱们在使用的时候还要先写好相关的解析代码(如下)。理解不了,识别不准确,回答当然不行
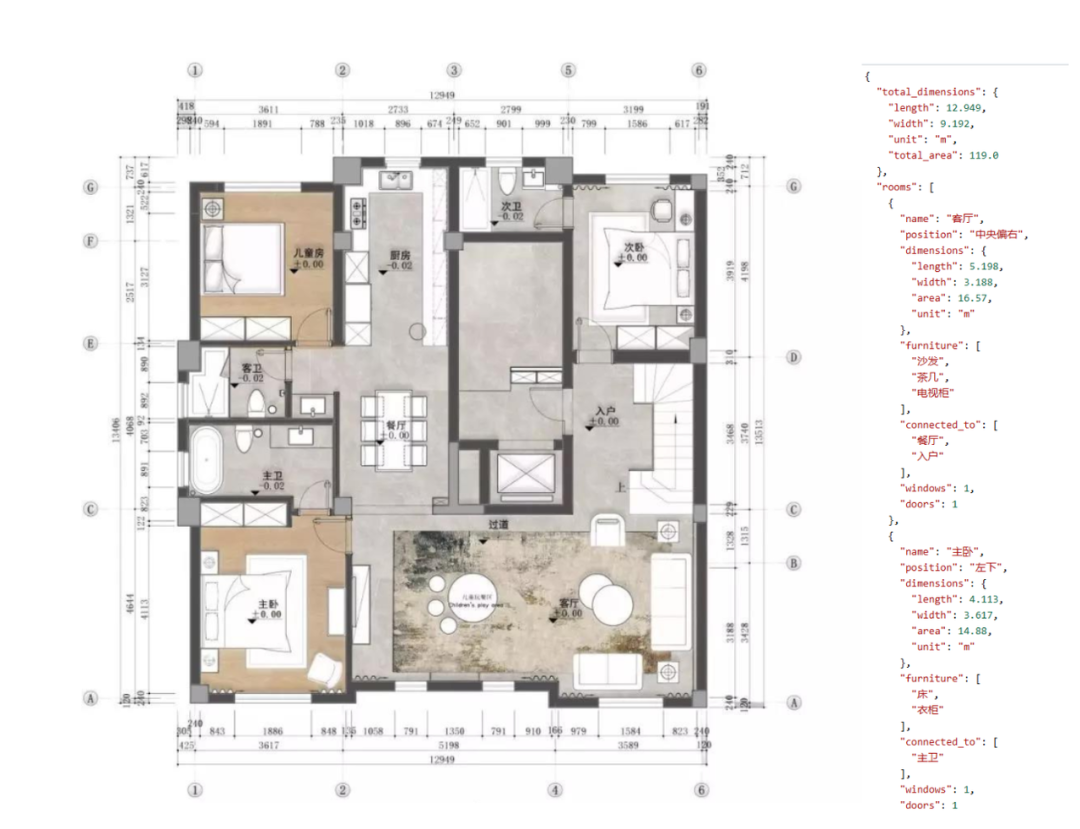
难点二:复杂检索
当咱们问一个拐了几个弯的复杂问题时,模型需要联系多处细节,如果只是简单的关键词检索,很容易检索到一大堆不相关的信息,在生成答案时就会被干扰
难点三:混合语义识别
尤其是PDF这种包含了文本、图片、表格等等各种信息的文档,如何把不同模态的信息有效地融合、对齐、让模型真正理解文档的语义关系,依然是个巨大挑战
03 解决方案实现-多模态RAG问答系统搭建
咱们这个基于VLM构建的多模态RAG问答系统,已经过企业级真实环境开发验证实现落地的!整体采用模块化设计,核心结构如下:

我们为你准备了三种多模态RAG的实现路径(含代码级讲解实战):统一向量空间检索、多路并行检索、转化为统一模态(文本)处理。
最后一种也是目前就是目前应用最广泛、也最务实的方案: 🔥 模态归一化(Grounding)!即将所有非文本信息在预处理阶段转成文本表示~
“说人话”就是:管你是图片、表格还是音频,统统给我转成文本!
-
对图像:运行OCR提取文字说明
-
对表格:转成CSV/文本
-
对音频:跑语音识别得到文本
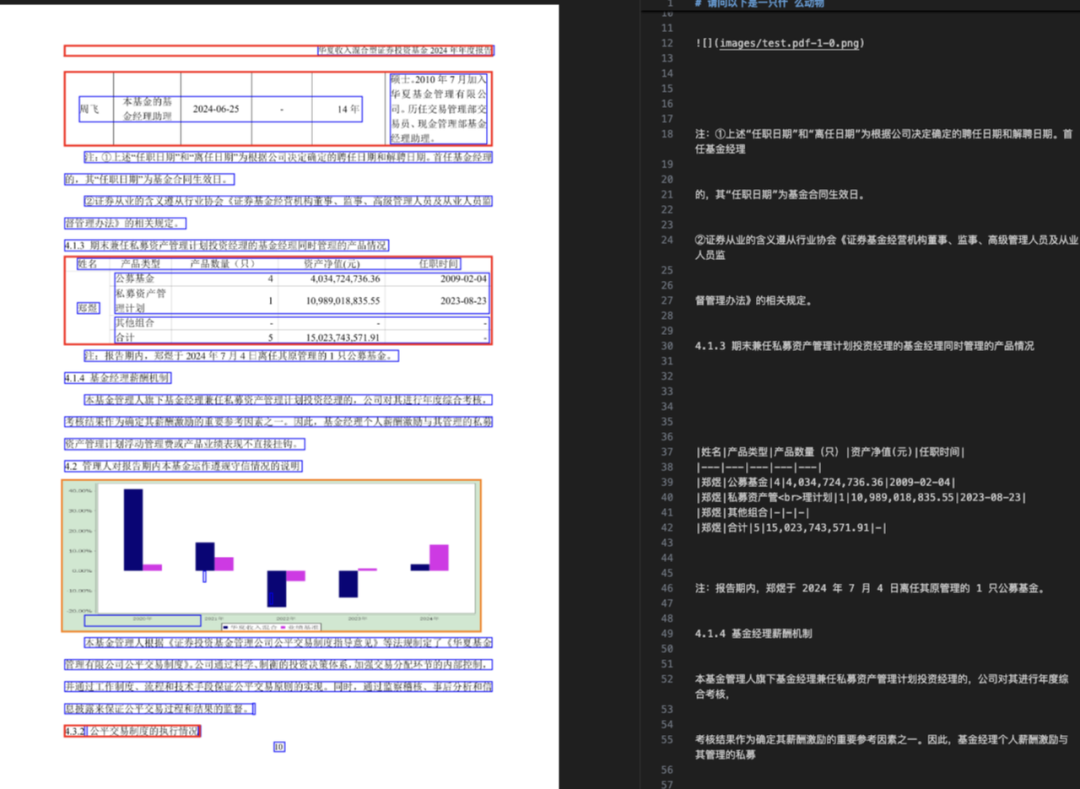
通过这个过程,把多模态内容全变成可索引的文本块,再用咱最熟悉的常规文本向量检索技术构建索引。
就这么干,简直不要太爽:架构简单!完美复用成熟的文本RAG技术!再也不用训练复杂的多模态模型了!
那我们这个项目,从零开始,逐步实现一个能够"读懂"CAD图纸、自动提取关键信息、并智能回答用户问题的系统,其核心实现思路如下:
第一步:接入VLM模型
↓
第二步:解析本地CAD图片
↓
第三步:提取结构化元数据
↓
第四步:存入向量数据库
↓
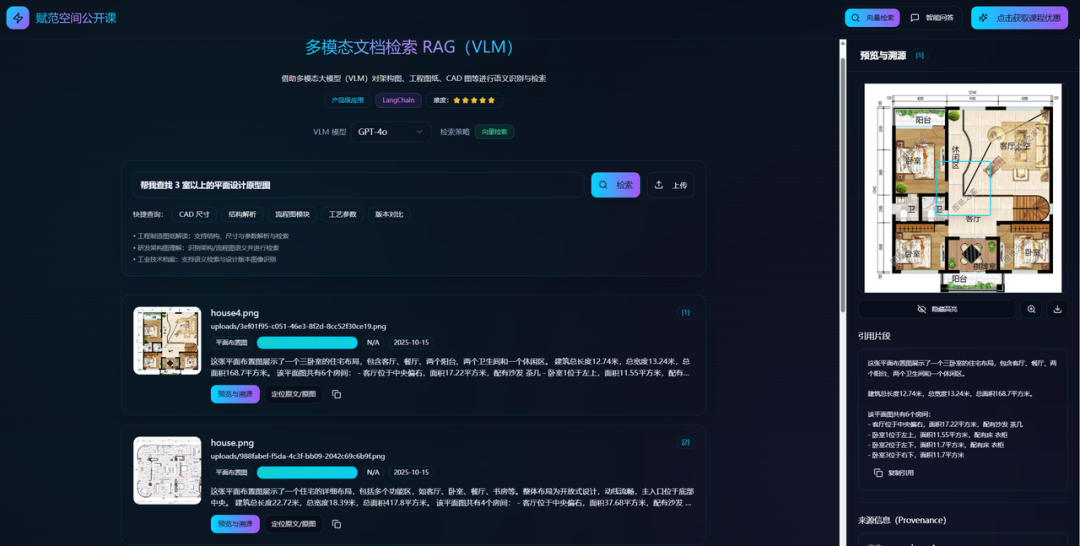
第五步:智能问答(直接问答 + 图像检索)这套系统到底有多顶?三大核心功能:
1、支持在线上传并自动解析多模态PDF及CAD、工程图纸和复杂架构原型图;
2、通过自然语言问答,直接检索图片原型及文档原件,并支持溯源和在线预览;
3、支持实时上传多模态PDF及CAD、工程图纸和复杂架构原型图,并直接对文件内容进行提问,实现智能问答
04 免费!开源!快来领源码!
前后端架构完全开源,我们把📦【完整源码】➕【文字/视频教学内容】已打包至👇大模型技术社区:
https://kq4b3vgg5b.feishu.cn/wiki/space/7257794425391579164都是免费开放给大家学习的,需要更多大模型技术内容学习,都收录在咱们社区知识库了哦~欢迎加入一起升级打怪!


















&spm=1001.2101.3001.5002&articleId=154501167&d=1&t=3&u=1524b6bf3961426186c01351ce54c6d2)
 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









