 PaddleOCR多模态RAG实战
PaddleOCR多模态RAG实战




挖到宝了!🤩就是这个超级实用的开源项目:PaddleOCR-MultiRAG!完美解决了包含复杂图片、表格的PDF识别落地难题~
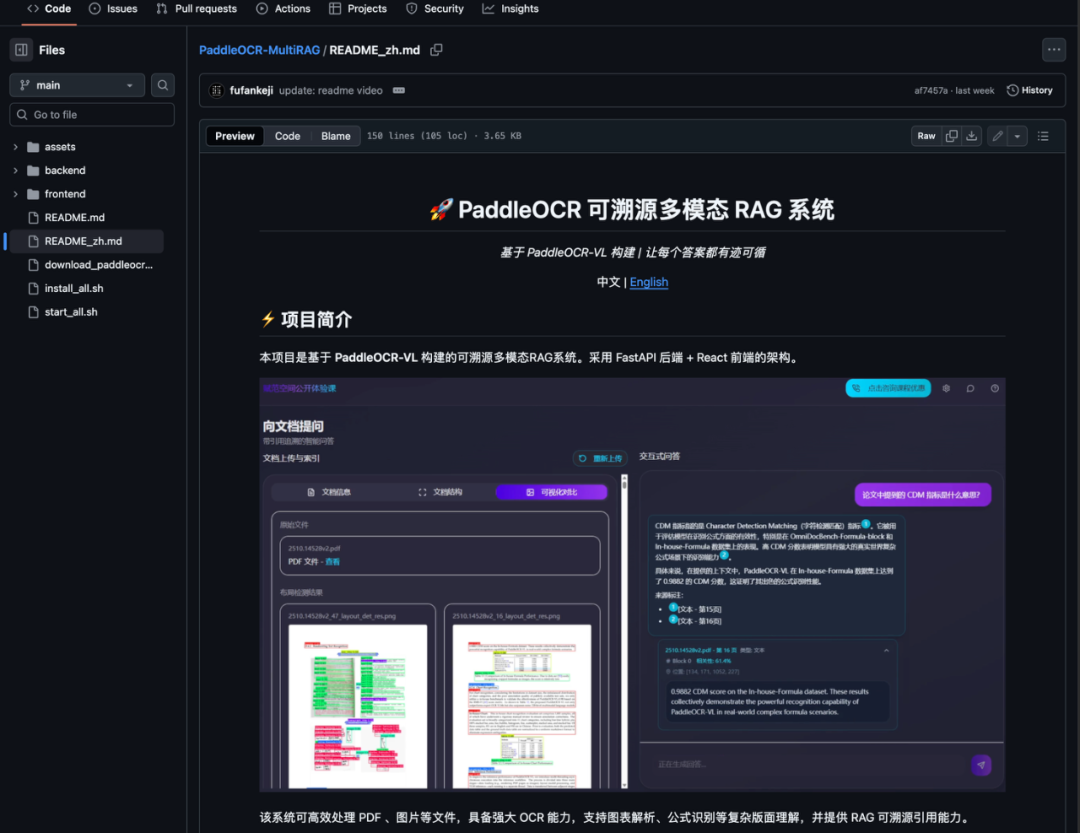
📦完整源码+讲解视频已打包👇:
https://kq4b3vgg5b.feishu.cn/wiki/space/7257794425391579164
很多做RAG的友友,在真正梳理文档的时候,十有八九都会被“非结构化”数据搞得焦头烂额。那些扫描的PDF、多栏排版、带水印的合同、还有海量图表的研报,用传统的 RAG 方案去提,简直就是大型灾难现场!
但这个 PaddleOCR-MultiRAG 项目,我想跟大家聊聊它为什么这么“香”~
01 功能角度:从“文本提取”升级到“文档解构”
很多 RAG 方案在提取PDF时,用的还是 PyPDF这类简单的工具,它只能粗暴地把文字抽出来,而这个项目,真的不一样!!
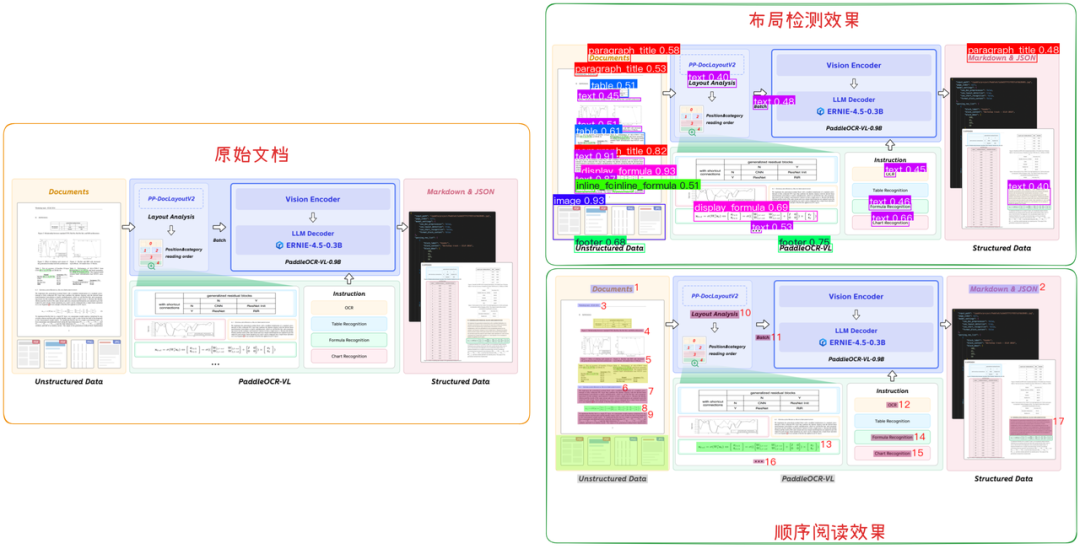
-
它直接上了 PaddleOCR,能处理扫描件、图片,实现高精度的版面分析和文字识别;
-
它能智能地解构文档。遇到正文文本,就进行常规切片;遇到表格,就将其识别并序列化为 Markdown 或 JSON;遇到图片,可能会调用VLM(多模态大模型)进行处理;
-
流程可编排,这种复杂的异构数据处理流程,构建了一个复杂的 Agent 流程,而不是一条道走到黑的简单 pipeline。
一句话总结:它不是在“提取”文本,而是在“理解”文档结构,为下游 RAG 提供高质量、高结构化的数据。
02 企业落地:直击“非结构化”数据的核心痛点
为什么说它落地性强?因为在企业环境中,90% 的高价值数据都以非结构化(或半结构化)的形式存在,比如:

-
金融/法务:扫描的合同、财报、监管文件。
-
制造业/工程:技术手册、图纸、质检报告。
-
医疗:病例、影像报告。
传统的 RAG 在这些场景下几乎“不可用”。而 PaddleOCR-MultiRAG提供的方案,恰恰是企业数字化转型的“最后一公里”——它解决了最棘手的“数据清洗”和“信息结构化”问题。一个能稳定处理复杂PDF和扫描件的RAG系统,其商业价值远超那些只能处理 .txt 的“玩具”项目~
03 技术稀缺:到“结构化RAG”的稀缺范例
现在 GitHub 上 RAG 项目多如牛毛,但绝大多数都是“Naive RAG”(朴素RAG),即“加载 -> 切分 -> 嵌入 -> 检索”。
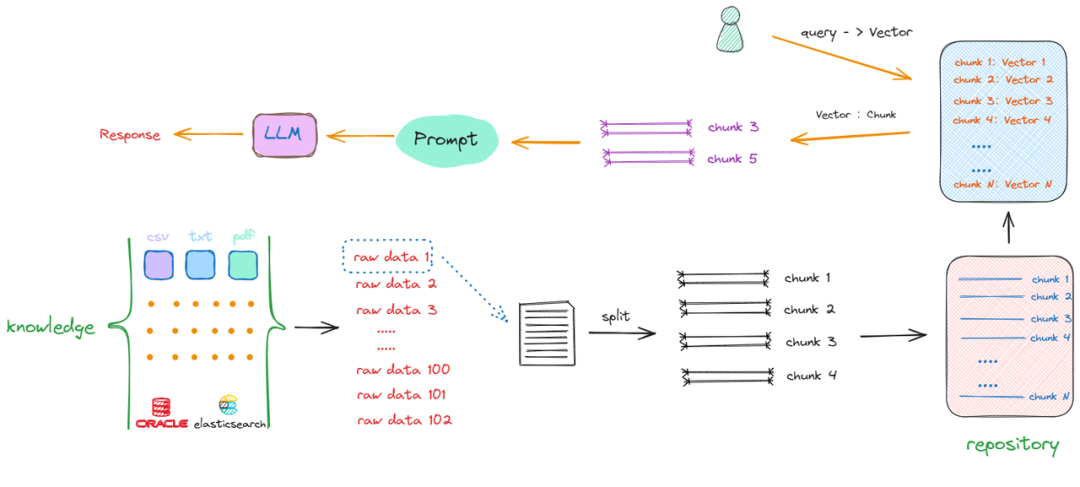
但真正的技术瓶颈在于“结构化RAG”和“多模态RAG”。
-
稀缺的OCR整合方案:很多人知道 OCR 很重要,但如何将 OCR 引擎与 RAG 流程无缝结合,处理坐标、遮挡、多栏等问题,并将其输出转化为 LLM 友好的格式?这套完整的、开源的解决方案非常稀缺。
-
稀缺的Multi-RAG实现:如何根据内容类型(文本、表格、图片)执行不同的处理策略,并最终在检索时智能地融合这些不同模态的信息源?这更是技术深水区。
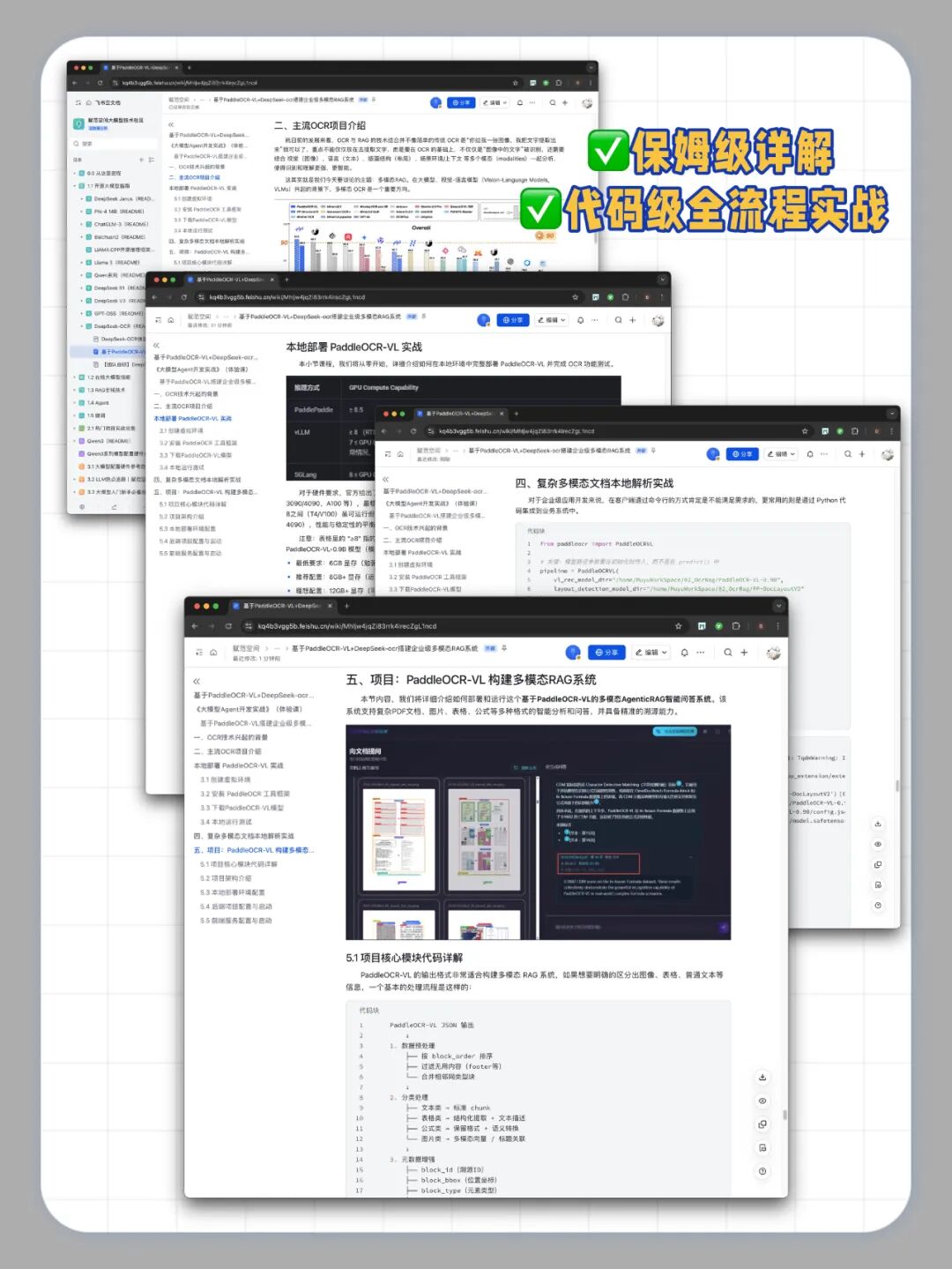
💥这个项目,绝对是“结构化RAG”的一个优秀实战案例,清晰地展示了一条从“混乱的原始文档”到“精准的智能问答”的技术路径,欢迎伙伴们进行复现尝试,目前已收录进赋范大模型技术社区,我们提供完整源码+工具包🔧+讲解视频,扫码即可获取~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









