



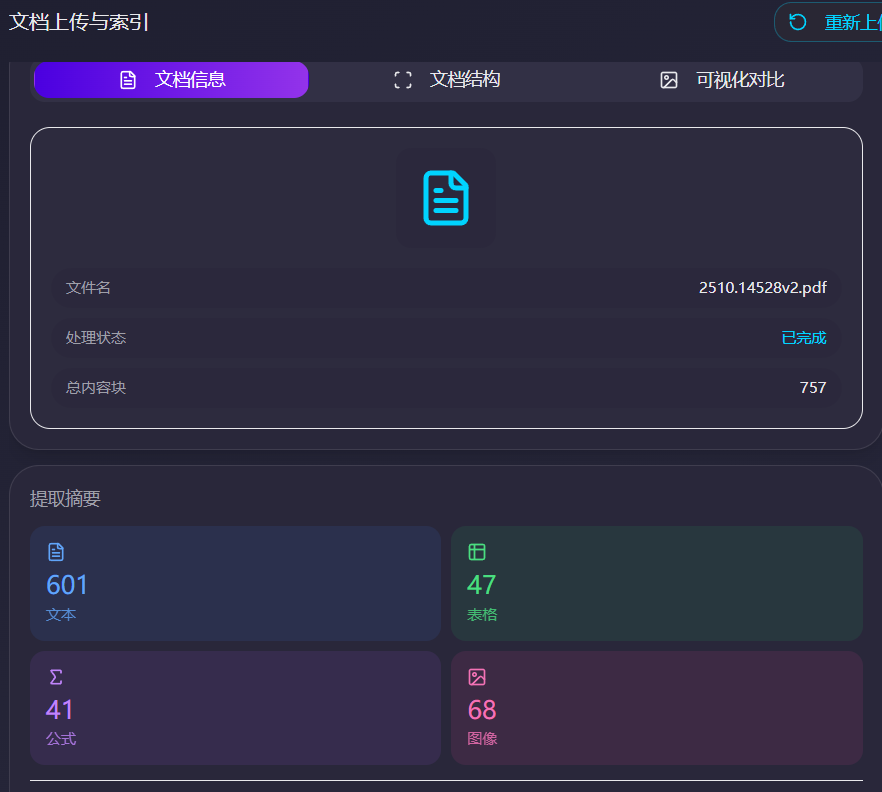
PaddleOCR-VL 构建多模态RAG系统
本章内容,我们将详细介绍如何部署和运行这个基于PaddleOCR-VL的多模态AgenticRAG智能问答系统。该系统支持复杂PDF文档、图片、表格、公式等多种格式的智能分析和问答,并具备精准的溯源能力。
应用场景与价值
1. 企业文档管理
- 技术文档检索:快速定位技术规范、操作手册中的关键信息
- 合同条款查询:精准检索合同条款,支持法务审查
- 报告分析:智能解析财务报告、研究报告等复杂文档
2. 教育培训领域
- 教材问答:支持教科书、学术论文的智能问答
- 考试辅导:基于教材内容生成问答对,辅助学习
3. 科研学术应用
- 论文检索:快速定位相关研究内容和数据
- 文献综述:自动整理和分析大量学术文献
- 实验数据分析:解析实验报告中的表格和图表数据
项目核心模块代码详解
PaddleOCR-VL 的输出格式非常适合构建多模态 RAG 系统,如果想要明确的区分出图像、表格、普通文本等信息,一个基本的处理流程是这样的:
PaddleOCR-VL JSON 输出
↓
1. 数据预处理
├── 按 block_order 排序
├── 过滤无用内容(footer等)
└── 合并相邻同类型块
↓
2. 分类处理
├── 文本类 → 标准 chunk
├── 表格类 → 结构化提取 + 文本描述
├── 公式类 → 保留格式 + 语义转换
└── 图片类 → 多模态向量 / 标题关联
↓
3. 元数据增强
├── block_id(溯源ID)
├── block_bbox(位置坐标)
├── block_type(元素类型)
├── page_index(页码)
└── 上下文信息(前后标题、图表编号)
↓
4. 向量化与索引
├── 文本 Embedding
├── 表格 Embedding(多策略)
└── 建立多级索引
↓
5. 检索与溯源
├── 语义检索
├── 坐标定位
└── 可视化标注
添加小助理加入 赋范空间 免费领取完整源码及更多持续更新的大模型Agent、RAG、MCP、微调课程
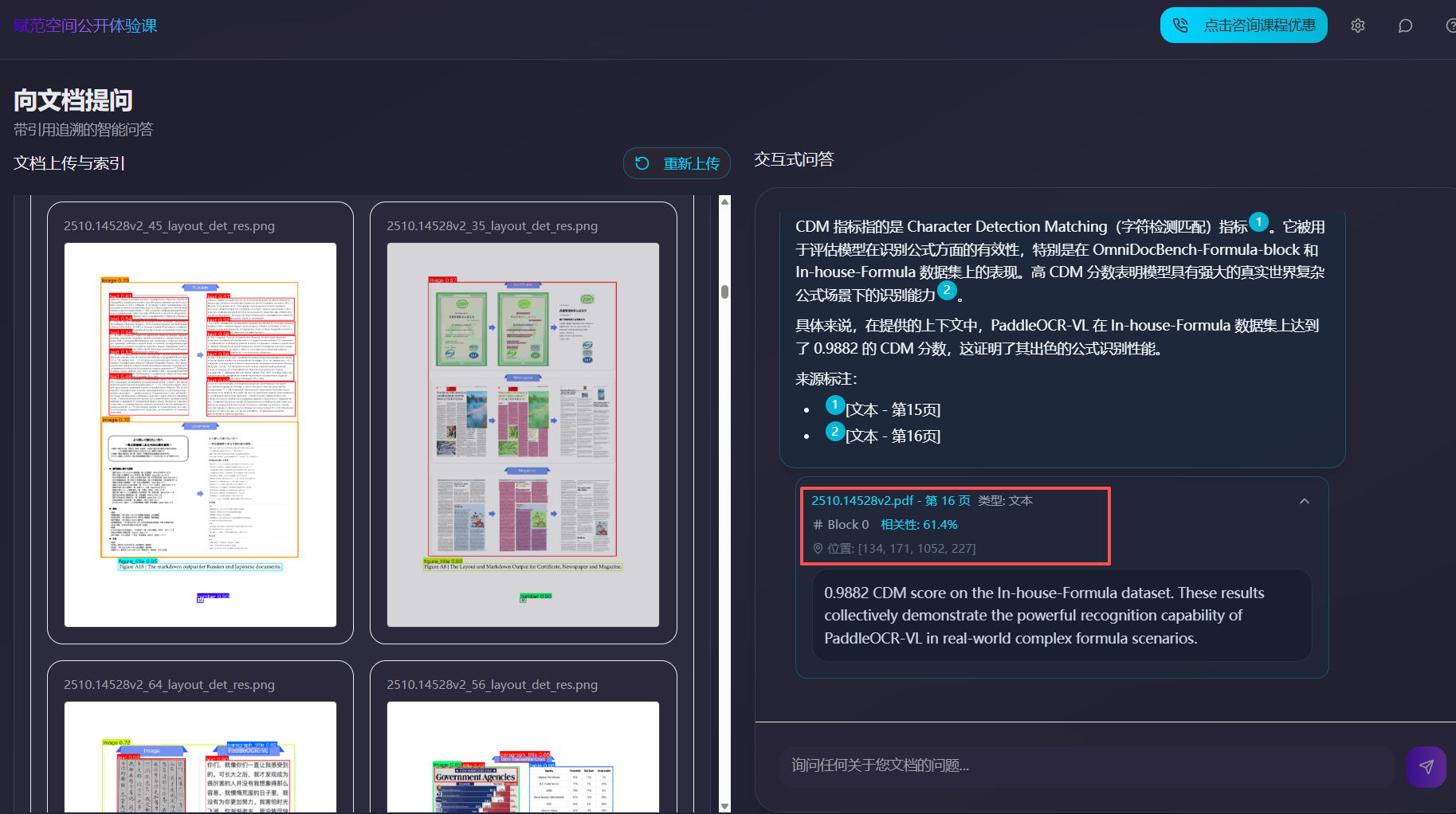
首先第一步做的就是完成PaddleOCR-VL模型的接入及实现解析过程。核心代码文件为:ocr_service.py
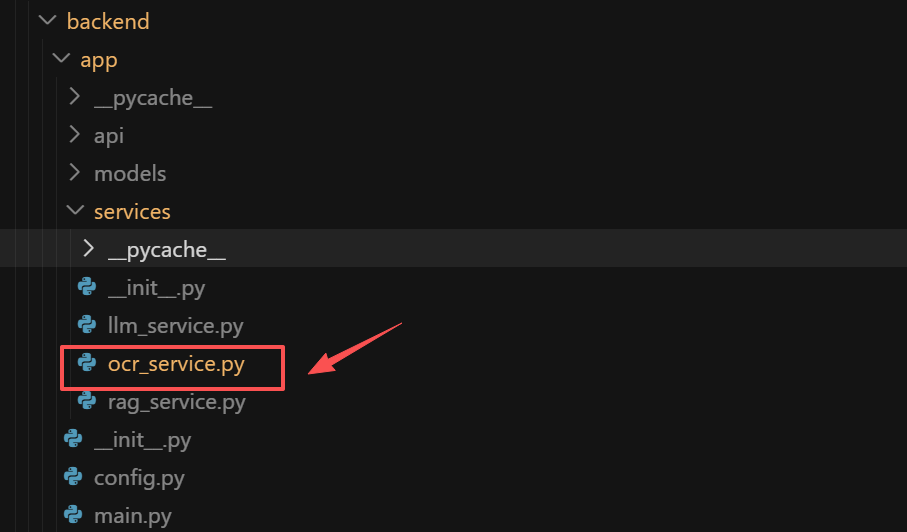
这个服务的核心流程是:初始化时异步加载 PaddleOCRVL 模型到,然后在 parse_document() 中通过线程池执行阻塞的 OCR 调用,PaddleOCR 会将文档解析为多页结果并保存为 JSON/Markdown/可视化图片到磁盘。服务优先从生成的 *_res.json 文件中读取每页的 parsing_res_list,将其中的每个 block(包含 block_id、block_label、block_content、block_bbox、block_order 等字段)转换为 ParsedBlock 对象,最后通过 calculate_stats() 按 label 关键词(table/image/formula/其他)统计各类型块的数量并返回 DocumentStats。即:
- 初始化 → 加载 PaddleOCR 模型
- 执行 OCR → 调用 pipeline.predict() 生成 JSON/Markdown/图片
- 解析结果 → 从 JSON 文件转为 ParsedBlock 对象
- 计算统计 → 按类型分类统计块数量
分类逻辑
| 判断条件 | 分类结果 | 示例 label |
|---|---|---|
'table' in label | table_blocks | table, table_cell |
'image/figure/chart' in label | image_blocks | image, figure, chart |
'formula/equation' in label | formula_blocks | display_formula, inline_formula |
| 其他 | text_blocks | text, paragraph_title, footer |
接下来,在第二步我们要封装 AgenticRAG 的构建逻辑,核心代码文件为rag_service.py:
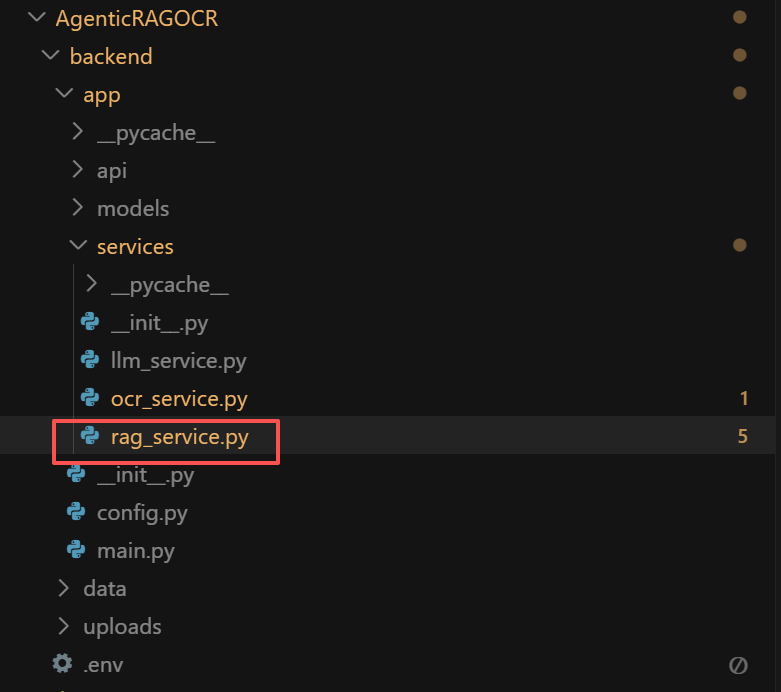
其中核心的分块策略是根据内容类型差异化处理
分块策略
| 内容类型 | 分块策略 | 原因 |
|---|---|---|
长文本 (text) | ✂️ 分块(chunk_size=500) | 避免单个向量损失局部语义 |
| 短文本 | ✅ 不分块 | 保持完整性 |
表格 (table) | ✅ 整体存储 | 表格结构不能拆分 |
公式 (formula) | ✅ 整体存储 | LaTeX 公式语义完整 |
图片 (image) | ✅ 整体存储 | 图片标题/caption 整体索引 |
每个 chunk 存储以下元数据:
metadata = {
"doc_id": "uuid", # 文档ID
"file_name": "example.pdf", # 原始文件名
"page_index": 0, # 页码(PDF多页)
"block_id": 5, # OCR block ID
"block_type": "text", # 类型(text/table/image/formula)
"block_label": "paragraph_title", # OCR 原始标签
"block_bbox": "[100,200,300,400]", # 坐标(JSON字符串)
"block_order": 3, # 阅读顺序
"chunk_index": 0, # 分块索引(如果分块)
"total_chunks": 2, # 总分块数
"is_chunked": True # 是否分块
}
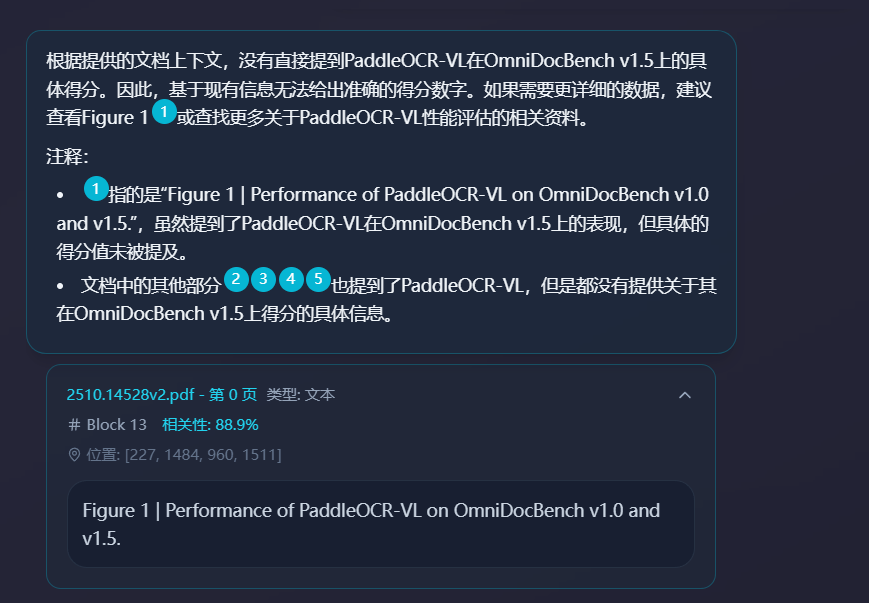
其次,对于溯源的策略,则主要是通过对元数据的格式化处理 + 大模型生成描述的引用来完成。核心代码文件llm_service.py:
在 Prompt 中明确引用:
system_prompt = """你是一个专业的文档问答助手。你的任务是:
1. 基于提供的文档上下文,准确回答用户的问题
2. 在回答中使用【数字】标记引用来源(例如【1】【2】) ⬅️ 关键
3. 对于表格、图像、公式等特殊内容,明确指出其类型
4. 如果上下文中没有相关信息,诚实地说明
5. 回答要准确、简洁、结构清晰
引用标注规则:
- 使用【1】【2】【3】等数字标记,对应检索到的文档块
- 每个关键信息点都应该标注引用来源
- 多个来源可以连续标注,如【1】【2】
"""
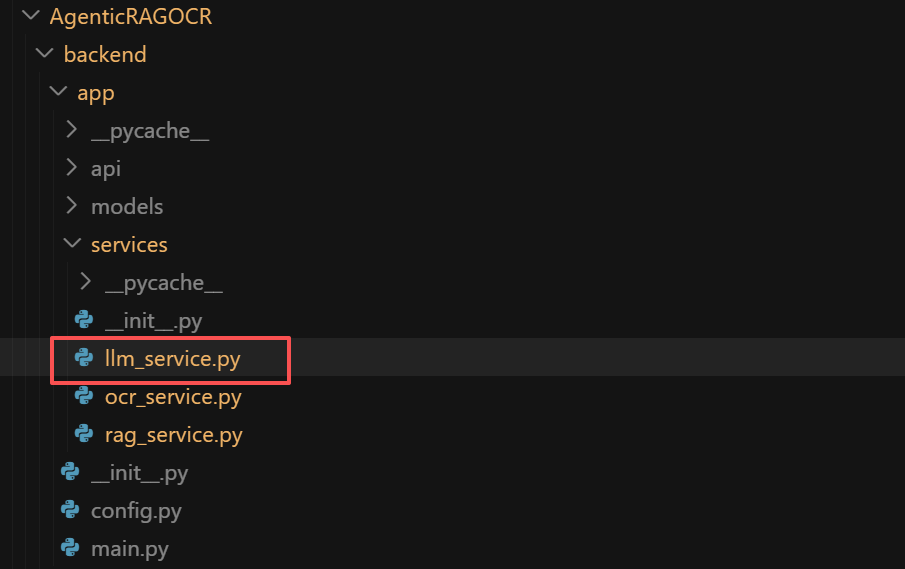
项目架构介绍
AgenticRAGOCR 项目采用前后端分离的模块化设计,核心结构如下:
AgenticRAGOCR/ # 项目根目录
├── 📁 backend/ # 后端服务层
│ ├── app/ # 主应用目录
│ │ ├── main.py # FastAPI主服务 - 多模态RAG API
│ │ ├── config.py # 配置管理
│ │ ├── services/ # 业务服务层
│ │ │ ├── ocr_service.py # PaddleOCR-VL 服务
│ │ │ ├── rag_service.py # RAG 检索服务
│ │ │ └── llm_service.py # LLM 问答服务
│ │ ├── models/ # 数据模型
│ │ └── api/ # API 路由
│ ├── requirements.txt # Python 依赖
│ ├── .env # 环境配置
│ ├── data/ # 数据目录
│ │ └── chroma_db/ # ChromaDB 向量数据库存储
│ └── uploads/ # 上传文件存储目录
│
├── 📁 frontend/ # 前端界面(React + TypeScript)
│ ├── src/ # 源代码
│ │ ├── components/ # UI 组件
│ │ ├── lib/ # 工具库
│ │ │ └── api.ts # API 客户端
│ │ └── App.tsx # 主应用
│ ├── package.json # Node.js 依赖
│ └── vite.config.ts # Vite 配置
│
├── restart_all.sh # 一键重启脚本
└── start_frontend.sh # 前端启动脚本
添加小助理加入 赋范空间 免费领取完整源码及更多持续更新的大模型Agent、RAG、MCP、微调课程
核心组件功能说明
| 层级 | 技术栈 | 主要功能 | 关键文件 |
|---|---|---|---|
| API服务层 | FastAPI + Pydantic | RESTful API、文件上传、智能问答 | main.py |
| OCR解析层 | PaddleOCR-VL-0.9B | 文档解析、布局检测、内容识别 | ocr_service.py |
| 向量检索层 | ChromaDB + Qwen Embeddings | 语义检索、相似度计算、分块策略 | rag_service.py |
| 问答生成层 | 通义千问大模型 | 智能问答、溯源引用、上下文理解 | llm_service.py |
| 数据存储层 | 文件系统 + 向量数据库 | 原文件存储、向量索引、元数据管理 | uploads/ + chroma_db/ |
| 前端界面层 | React + TypeScript + Vite | 文档可视化、问答交互、溯源展示 | frontend/ |
本地部署环境配置
系统基于Python 3.11+开发,需要确保环境满足以下要求:
环境要求
| 组件 | 版本要求 | 安装方式 | 验证命令 |
|---|---|---|---|
| Python | ≥ 3.11 | 官网下载或conda | python --version |
| Node.js | ≥ 18.0 | 官网下载或nvm | node --version |
| pip | 最新版 | 随Python安装 | pip --version |
| npm | ≥ 9.0 | 随Node.js安装 | npm --version |
| GPU | 推荐8GB+ | CUDA 12.6 | nvidia-smi |
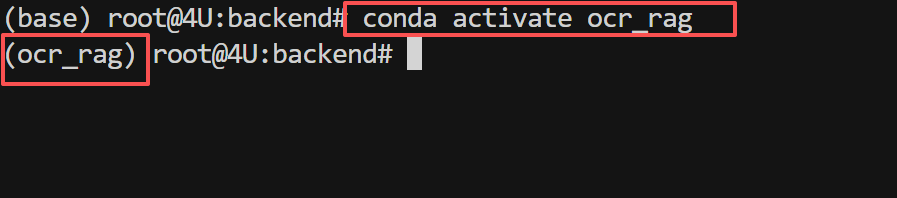
本项目使用 ocr_rag 虚拟环境(与之前的PaddleOCR环境一致):
# 如果还没有创建,使用conda创建环境
conda create -n ocr_rag python=3.11
conda activate ocr_rag
# 如果已经创建过,直接激活
conda activate ocr_rag
激活后,命令行提示符前会显示 (ocr_rag),表示已进入虚拟环境。
后端项目配置与启动
进入项目后端目录,安装Python依赖:
# 进入后端目录
cd /home/MuyuWorkSpace/02_OcrRag/projects/AgenticRAGOCR/backend
# 安装核心依赖包
pip install -r requirements.txt
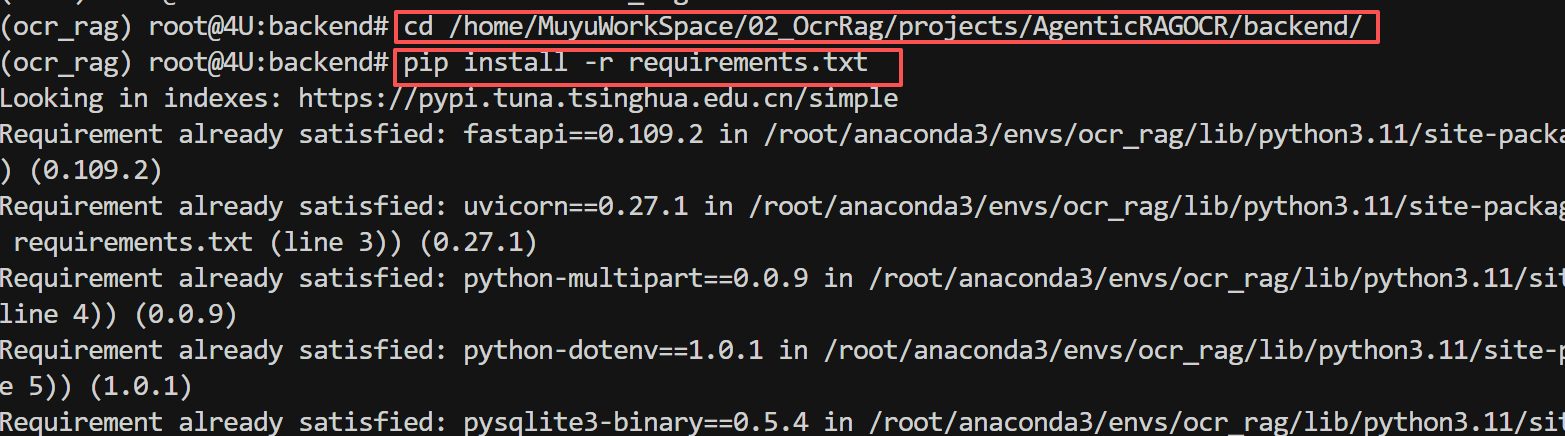
核心Python依赖
| 依赖包 | 版本 | 用途 |
|---|---|---|
| fastapi | 0.109.2 | Web框架 |
| uvicorn | 0.27.1 | ASGI服务器 |
| dashscope | 1.19.0 | 阿里云百炼SDK(Qwen模型) |
| chromadb | 0.4.22 | 向量数据库 |
| langchain | 0.1.7 | LLM应用框架 |
| paddleocr[all] | 最新版 | OCR工具(已在前面安装) |
| paddlepaddle-gpu | 3.2.0 | 深度学习框架(已在前面安装) |
项目的环境变量配置已经在 backend/.env 文件中定义,主要包含以下配置:
# 阿里云百炼平台配置
DASHSCOPE_API_KEY=sk-e2bad0af850e403e
QWEN_MODEL_NAME=qwen-max # 或 qwen-plus, qwen-turbo
# 向量数据库配置
CHROMA_PERSIST_DIR=./data/chroma_db
EMBEDDING_MODEL=text-embedding-v3 # Qwen embedding 模型(支持中英文)
# PaddleOCR 模型路径
PADDLEOCR_VL_MODEL_DIR=/home/MuyuWorkSpace/02_OcrRag/PaddleOCR-VL-0.9B
LAYOUT_DETECTION_MODEL_DIR=/home/MuyuWorkSpace/02_OcrRag/PP-DocLayoutV2
# 文件上传配置
UPLOAD_DIR=./uploads
MAX_UPLOAD_SIZE=50 # MB
# 服务器配置
HOST=0.0.0.0
PORT=8100
# 日志配置
LOG_LEVEL=INFO
重要提示:
DASHSCOPE_API_KEY:必须配置,用于调用通义千问模型和Embedding服务PADDLEOCR_VL_MODEL_DIR和LAYOUT_DETECTION_MODEL_DIR:指向已下载的模型路径
配置完成后,启动FastAPI后端服务:
# 确保在 ocr_rag 虚拟环境中
conda activate ocr_rag
# 进入后端目录
cd /home/MuyuWorkSpace/02_OcrRag/projects/AgenticRAGOCR/backend
# 启动后端服务
python start_backend_conda.sh
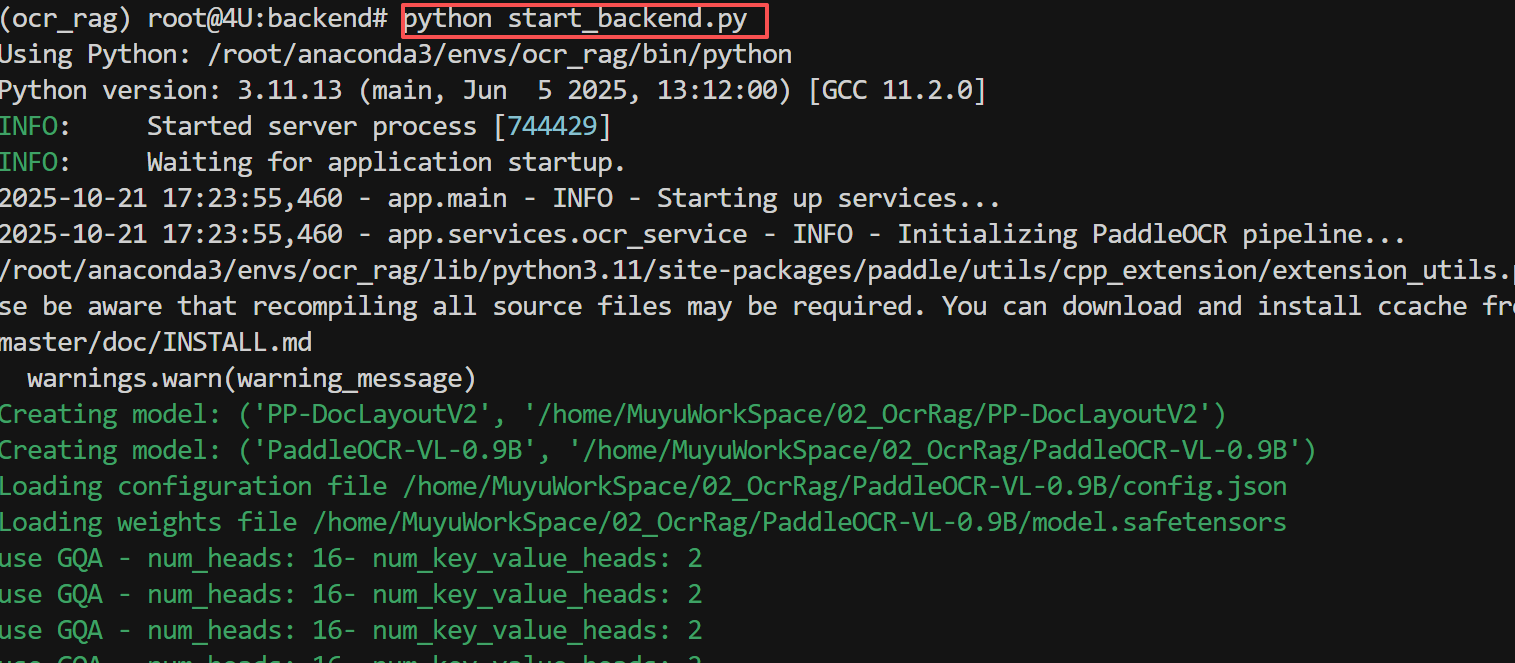
启动成功后,终端会显示如下信息:
INFO: Started server process [12345]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8100 (Press CTRL+C to quit)
此时可以访问 http://localhost:8100/docs 查看API文档。
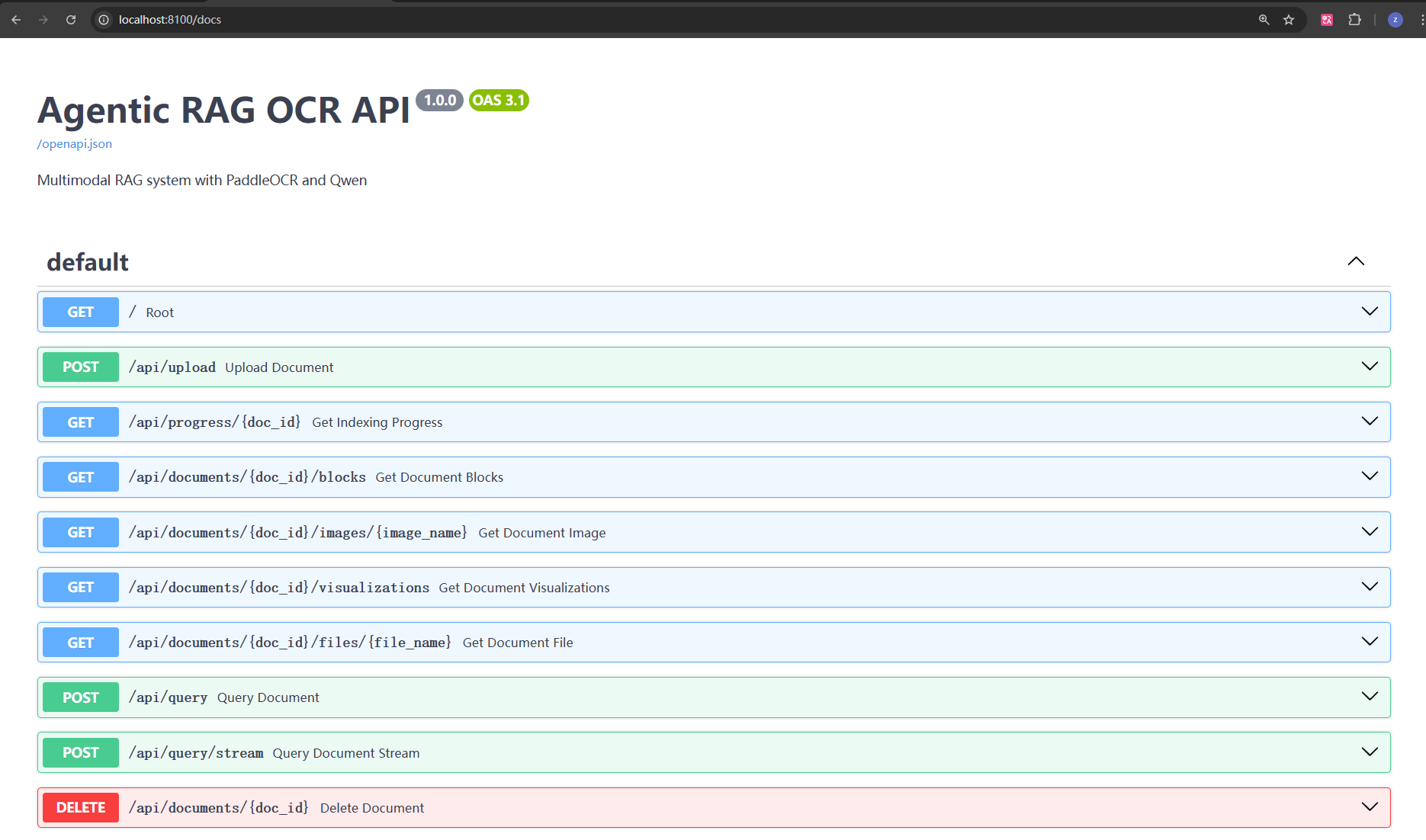
主要API接口
| 接口路径 | 方法 | 功能 | 说明 |
|---|---|---|---|
/api/documents/upload | POST | 文档上传 | 支持PDF、图片等格式,自动OCR解析 |
/api/documents/{doc_id}/index | POST | 文档索引 | 将OCR结果向量化并存入ChromaDB |
/api/documents/{doc_id}/query | POST | 语义检索 | 基于向量检索的语义搜索 |
/api/documents/{doc_id}/qa | POST | 智能问答 | 多模态问答,支持溯源引用 |
/api/documents | GET | 文档列表 | 获取已上传的文档列表 |
/api/documents/{doc_id}/blocks | GET | 获取文档块 | 获取解析后的文档块(可按类型过滤) |
/api/documents/{doc_id}/pages/{page_index} | GET | 获取页面信息 | 获取特定页的OCR结果 |
/api/documents/{doc_id}/visualizations/{img_name} | GET | 获取可视化图 | 获取布局检测和阅读顺序可视化图 |
前端服务配置与启动
进入前端目录,安装Node.js依赖:
# 进入前端目录
cd /home/MuyuWorkSpace/02_OcrRag/projects/AgenticRAGOCR/frontend
# 安装依赖(首次运行需要,耗时约2-5分钟)
npm install
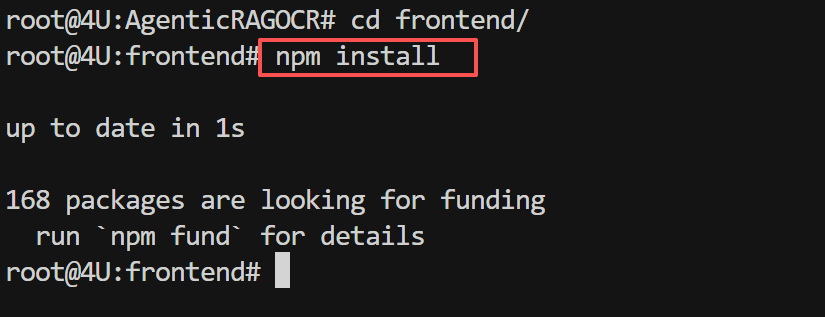
核心前端技术栈:
前端技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| React | 18.3.1 | UI框架 |
| TypeScript | 5.6.3 | 类型系统 |
| Vite | 5.4.11 | 构建工具 |
| TailwindCSS | 3.4.15 | CSS框架 |
| Radix UI | 最新版 | 组件库 |
| React Markdown | 10.1.0 | Markdown渲染 |
| KaTeX | 0.16.25 | 公式渲染 |
依赖安装完成后,启动Vite开发服务器:
# 在前端目录下执行
npm run dev
启动成功后,终端会显示如下信息:
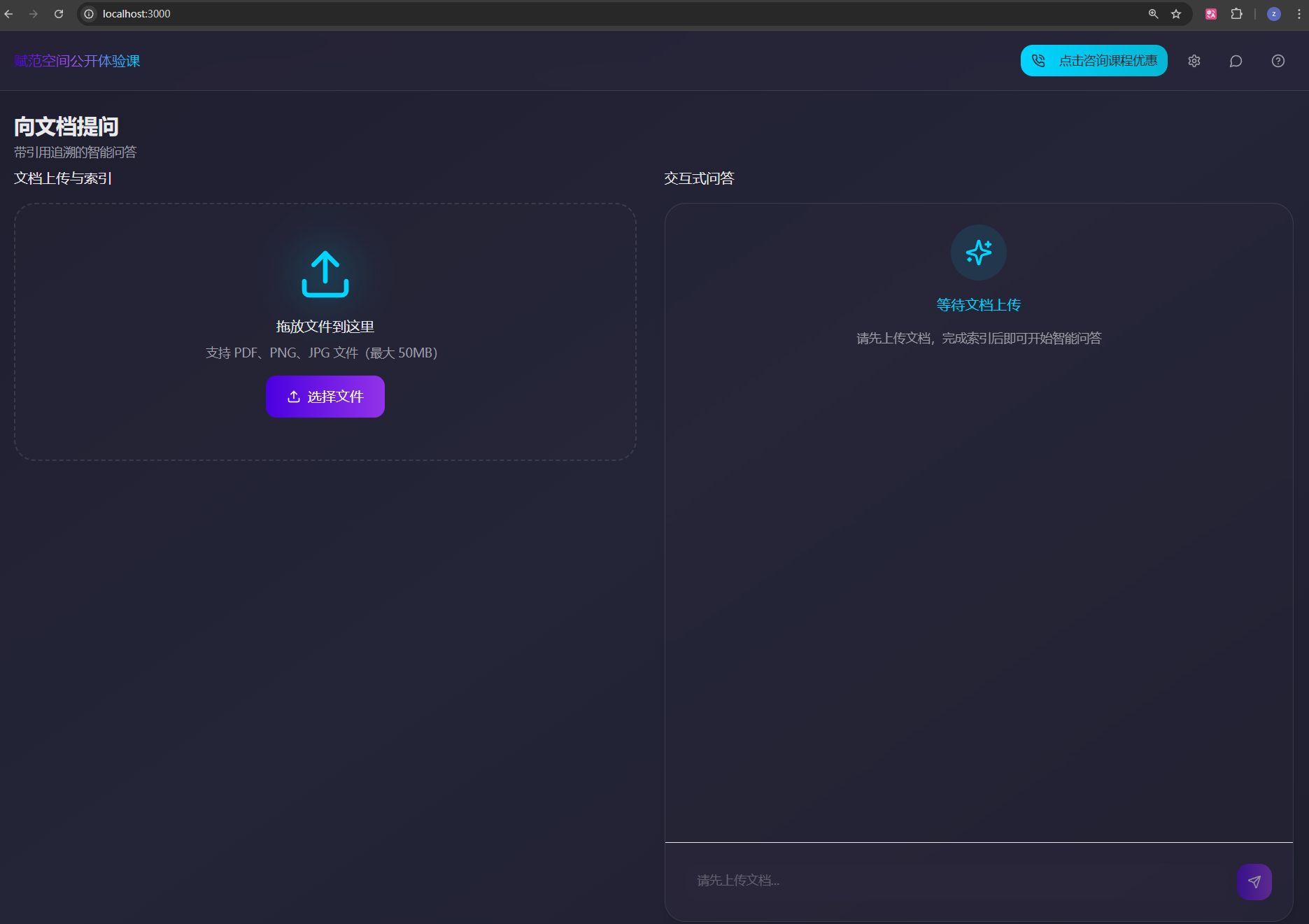
打开浏览器访问 http://localhost:5173,即可看到AgenticRAGOCR系统的前端界面。
总结
本文详细介绍了基于PaddleOCR-VL构建企业级多模态RAG系统的完整实现方案。该系统通过深度集成OCR技术、向量检索和大语言模型,实现了对复杂文档的智能解析、语义检索和精准问答。
核心技术特点
1. 多模态文档解析能力
- PaddleOCR-VL模型:支持文本、表格、图片、公式等多种元素的精准识别
- 布局检测:自动识别文档结构,保持原始排版信息
- 坐标定位:精确记录每个元素的位置信息,支持可视化溯源
2. 智能分块策略
- 差异化处理:根据内容类型(文本/表格/公式/图片)采用不同的分块策略
- 元数据增强:为每个chunk添加丰富的元数据信息,包括位置、类型、页码等
- 语义完整性:确保表格、公式等结构化内容的完整性
3. 精准溯源机制
- 引用标注:自动生成【1】【2】等数字标记,明确标识信息来源
- 可视化定位:通过坐标信息在原文档中精确标注相关内容
- 多维度溯源:支持页码、块ID、坐标等多种溯源方式
通过本项目的实践,我们展示了如何将OCR技术与RAG系统相结合,构建一个功能完整、性能优异的企业级多模态文档智能问答系统,为企业的数字化转型和知识管理提供了有力的技术支撑。

















 260
260





 到【灌水乐园】发言
到【灌水乐园】发言







