




项目结构:
fangtianxia.py
import scrapy
from fangtianxia_1.items import Fangtianxia1Item
import re
from datetime import datetime
from fangtianxia_1.items import CityTotalCountItem
class FangtianxiaSpider(scrapy.Spider):
name = 'fangtianxia'
# allowed_domains = ['fangtianxia.com', 'esf.fangtianxia.com']
allowed_domains = ['fangtianxia.com']
start_urls = ['https://www.fang.com/SoufunFamily.html']
def parse(self, response):
print(response, response.url, '************************************')
trs = response.xpath('//div[@class="outCont"]//tr[@id and position()>1]')
province_name = None
provinces = []
cities = []
for tr in trs:
province = tr.xpath('./td[not(@class)]/strong/text()').get("")
if province == "其它":
continue
if province and province != " ":
province_name = province
provinces.append(province_name)
city_tds = tr.xpath('./td[last()]/a')
for city in city_tds:
city_name = city.xpath('./text()').get()
city_url = city.xpath('./@href').get()
if "bj." in city_url:
esf_house_url = "https://esf.fang.com/"
else:
house_url = city_url.split("//")
url_tail = house_url[1].split(".") # esf.changji.fang.com -> changji.esf.fang.com
if len(url_tail) == 4: # 昌吉和香港的网址比较特殊,需要单独处理
if url_tail[1] == 'changji':
esf_house_url = 'https://' + url_tail[1] + '.' + url_tail[0] + '.' + url_tail[2] + '.' + url_tail[3]
elif url_tail[0] == 'hk':
esf_house_url = 'https://' + house_url[1]
else:
esf_house_url = "https://" + url_tail[-3] + ".esf." + url_tail[-2] + "." + url_tail[-1]
# print('province_name = ', province_name, ', city_name = ', city_name)
cities.append(city_name)
# if province_name == '':
yield scrapy.Request(url=esf_house_url, callback=self.parse_esf_house,
meta={"info": (province_name, city_name, esf_house_url)}, dont_filter=True)
def parse_esf_house(self, response):
province, city, esf_house_url = response.meta.get('info')
# dls = response.xpath("//div[@class='main1200 clearfix']/div[@class='main945 floatl']/"
# "div[@class='shop_list shop_list_4']/dl")
total_count = response.xpath("//div[@class='main1200 clearfix']/div[@class='main945 floatl']/"
"div[@class='advert clearfix']/div[@class='floatl']/div[@class='clearfix advert_list']/"
"ul[3]/li[@class='col14']/b/text()").get()
num = 0
for dl in dls:
name = dl.xpath('./dd[1]/h4[@class="clearfix"]/a/@title').get()
describe = dl.xpath('./dd[1]/p[@class="tel_shop"]/text()').getall()
try:
rooms = describe[0].strip()
except Exception:
rooms = "暂无数据"
try:
area = describe[1].strip()
except Exception:
area = "暂无数据"
try:
floor = describe[2].strip()
except Exception:
floor = "暂无数据"
try:
toward = describe[3].strip()
except Exception:
toward = "暂无数据"
try:
year = describe[4].strip()
except Exception:
year = "暂无数据"
address = dl.xpath('./dd[1]/p[@class="add_shop"]/span/text()').get()
community = dl.xpath('./dd[1]/p[@class="add_shop"]/a/@title').get()
# area = describe[1].strip() # 面积
price = dl.xpath('./dd[2]/span[1]/b/text()').get()
# price_text = dl.xpath('./dd[@class="price_right"]/span[1]/text()').get()
# price = price_text.xpath('string(.)').strip()
unit = dl.xpath('./dd[2]/span[2]/text()').get()
item = Fangtianxia1Item(province=province, city=city, name=name, rooms=rooms, floor=floor, toward=toward, \
year=year, address=address, community=community, area=area, price=price, unit=unit)
# print(item, '*****************************')
num += 1
print('province = ', province, ', city = ', city, ', total_count = ', total_count)
item = CityTotalCountItem(province=province, city=city, total_count=total_count)
yield item
# next_page = response.xpath('//a[@id="PageControl1_hlk_next"]/@href').get()
next_page = response.xpath("//div[@class='main1200 clearfix']/div[@class='main945 floatl']/"
"div[@class='page_box']/div[@class='page_al']/"
"p[last()-1]/a[text()='下一页']/@href").get()
print('------------------next_page = ', next_page)
# print('------------------num = ', num)
# url = response.urljoin(next_page_url)
# https://nc.esf.fang.com/house/i33/ 35
# response.urljoin(next_page[1:len(next_page)])
if next_page:
# next_page_url = response.url + next_page[1:len(next_page)]
# print('------------------response.url = ', response.url)
print('------------------esf_house_url = ', esf_house_url)
print('------------------next_page[1:len(next_page)] = ', next_page[1:len(next_page)])
print('------------------esf_house_url + next_page[1:len(next_page)] = ', esf_house_url + (next_page[1:len(next_page)]))
yield scrapy.Request(url=esf_house_url + next_page[1:len(next_page)], callback=self.parse_esf_house,
meta={"info": (province, city, esf_house_url), 'dont_redirect': True, 'handle_httpstatus_list': [302]},
dont_filter=True)
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Fangtianxia1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
"""二手房item"""
province = scrapy.Field() # 省份
city = scrapy.Field() # 城市
name = scrapy.Field() # 标题
rooms = scrapy.Field() # 房间数
floor = scrapy.Field() # 楼层
toward = scrapy.Field() # 朝向
year = scrapy.Field() # 年份
address = scrapy.Field() # 地点
community = scrapy.Field() # 小区
area = scrapy.Field() # 面积
price = scrapy.Field() # 总价
unit = scrapy.Field() # 单价
class CityTotalCountItem(scrapy.Item):
province = scrapy.Field()
city = scrapy.Field()
total_count = scrapy.Field()
pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import csv
import os
class Fangtianxia1Pipeline:
def __init__(self):
self.parent_path = 'D:/A_graduate/2020-2021-1/spider/info/网站每个城市的在售房数量_3'
# self.f = open('D:/A_graduate/2020-2021-1/spider/网站每个城市的在售房数量.csv', 'a', encoding='utf-8', newline="")
def process_item(self, item, spider):
print("Fangtianxia1Pipeline--process_item----------------------")
# 创建文件夹:每个省份一个文件夹,省名作为文件夹名字
province_name = item['province']
# province_dir = os.path.join(self.parent_path, province_name)
# if not os.path.isdir(province_dir):
# os.mkdir(province_dir)
# 创建CSV文件:每个城市创建一个CSV,房天下_省份_城市.csv
file_csv = self.parent_path + '/' + province_name + '.csv'
file = open(file_csv, 'a', encoding='utf-8', newline="")
# 将数据写入文件中
writer = csv.writer(file)
writer.writerow((item['province'], item['city'], item['total_count']))
# writer.writerow((item['province'], item['city'], item['name'],item['rooms'],
# item['floor'], item['toward'], item['year'],item['address'],
# item['community'], item['area'], item['price']+'万', item['unit']))
return item
# writer = csv.writer(self.f)
# writer.writerow((item['province'], item['city'], item['total_count']))
# return item
def close_spider(self, spider):
pass
# self.f.close()
settings.py:
# Scrapy settings for fangtianxia_1 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'fangtianxia_1'
SPIDER_MODULES = ['fangtianxia_1.spiders']
NEWSPIDER_MODULE = 'fangtianxia_1.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'fangtianxia_1 (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': '填你自己的',
'cookie': '填你自己的'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'fangtianxia_1.middlewares.Fangtianxia1SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'fangtianxia_1.middlewares.Fangtianxia1DownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'fangtianxia_1.pipelines.Fangtianxia1Pipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
middlewares.py一般不需要动。
爬取的数据:
全国省份:

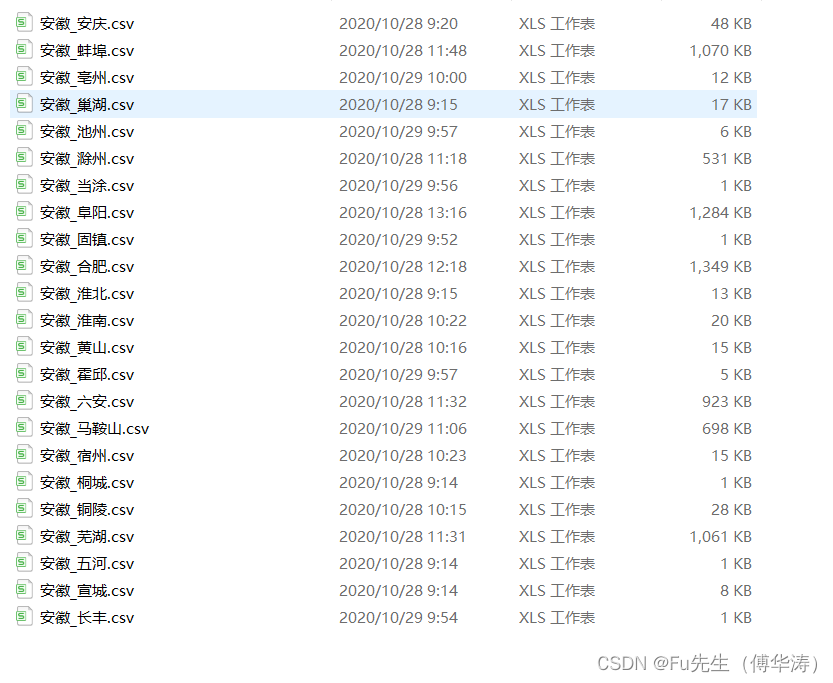
一个省的所有城市(以安徽省为例):
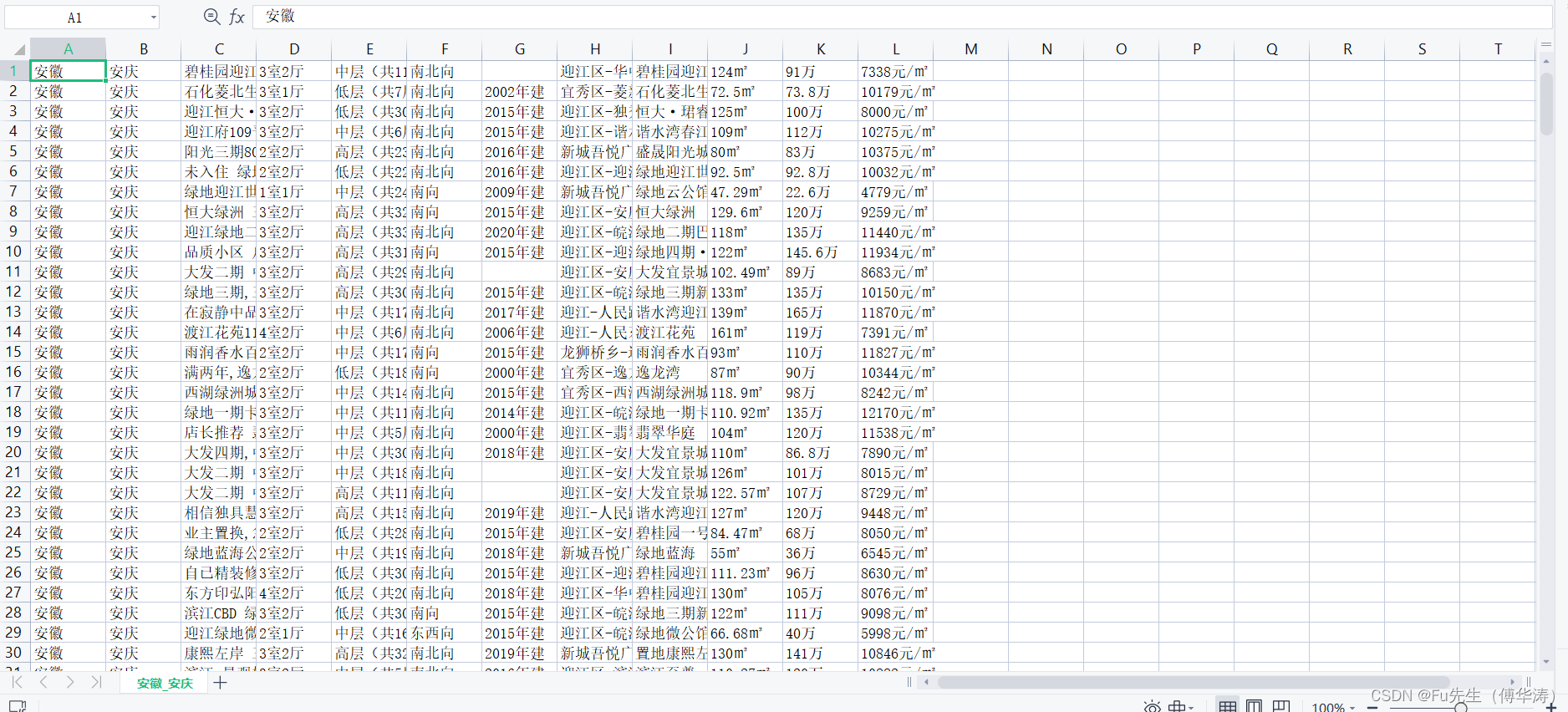
一个城市的数据(以安徽省安庆市为例):

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









