




Paper : Deep Residual Learning for Image Recognition
Code : torchvision
摘要
ResNet也是从“深就是好”的思想出发,为了解决梯度下降和梯度消失的问题,开创性的提出了shortcut connection的结构,之后大部分论文都引入了shortcut connection的结构。
网络结构
ResNet 中最重要的结构就是identity shortcut connection,结构如下
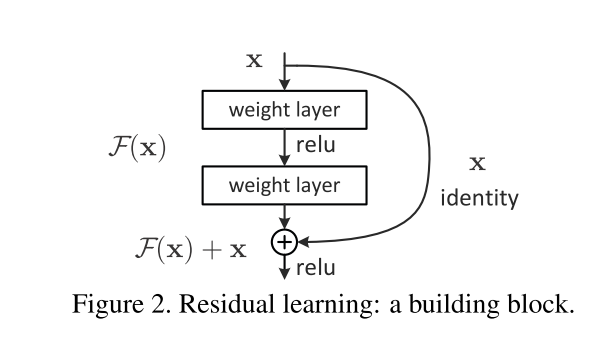
令 H ( x ) = F ( x ) + x \mathcal H(x) = \mathcal F(x)+x H(x)=F(x)+x,则有 F ( x ) = H ( x ) − x \mathcal F(x) = \mathcal H(x)-x F(x)=H(x)−x,也被称为是残差(Residual),这也就是ResNet要学习的部分。一个ResNet块的最后一步是将残差和恒等映射相加,之后过一个激活函数层,如果 F ( x ) \mathcal F(\text x) F(x)与 x \text x x在channel一维的大小相同,那么只需要直接相加即可,否则,可以采用以下两种方式来对齐
- 对channel一维进行零扩展。
- 使用1*1的卷积进行channel维度的控制。
我们来简单分析一下为什么恒等映射的shortcut的引入会改善梯度爆炸和梯度消失的问题。设激活函数使用 σ \sigma σ来表示,那么对于第 l l l个残差模块来说可以得到如下的式子
x l + 1 = σ ( y l ) = σ ( x l + F ( x l , W l ) ) \\ x_{l+1} = \sigma( y_l )= \sigma(x_l + \mathcal F(x_l,W_l)) xl+1=σ(yl)=σ(xl+F(xl,Wl))
其中, x l x_l xl表示残差模块的输入, F ( x l , W l ) \mathcal F(x_l,W_l) F(xl,Wl)表示的是两层weight layer对 x l x_l xl所做的运算。如果令 σ = ReLU \sigma = \text{ReLU} σ=ReLU,则在有效的反向传播的过程中, ReLU \text {ReLU} ReLU可以看作是一个恒等映射,有 x l + 1 = y l x_{l+1} = y_{l} xl+1=yl,通过递推式得到如下的表达式
x L = x l + ∑ i = l L − 1 F ( x i , W i ) x_L = x_l + \sum_{i=l}^{L-1} F(x_i,W_i) xL=xl+i=l∑L−1F(xi,Wi)
因此,在反向传播的过程中,有
∂ Loss ∂ x l = ∂ Loss ∂ x L ( 1 + ∂ ∂ x l ∑ i = l L − 1 F ( x i , W i ) ) \frac{\partial \text{Loss}}{\partial x_l} = \frac{\partial \text{Loss}}{\partial x_L} (1+ \frac{\partial }{\partial x_l}\sum_{i=l}^{L-1} F(x_i,W_i)) ∂xl∂Loss=∂xL∂Loss(1+∂xl∂i=l∑L−1F(xi,Wi))
可以看到,对于任何一层的x的梯度由两部分组成,其中一部分直接就由L层不加任何衰减和改变的直接传导l层,这保证了梯度传播的有效性,另一部分也由链式法则的累乘变为了累加,这样有更好的稳定性。
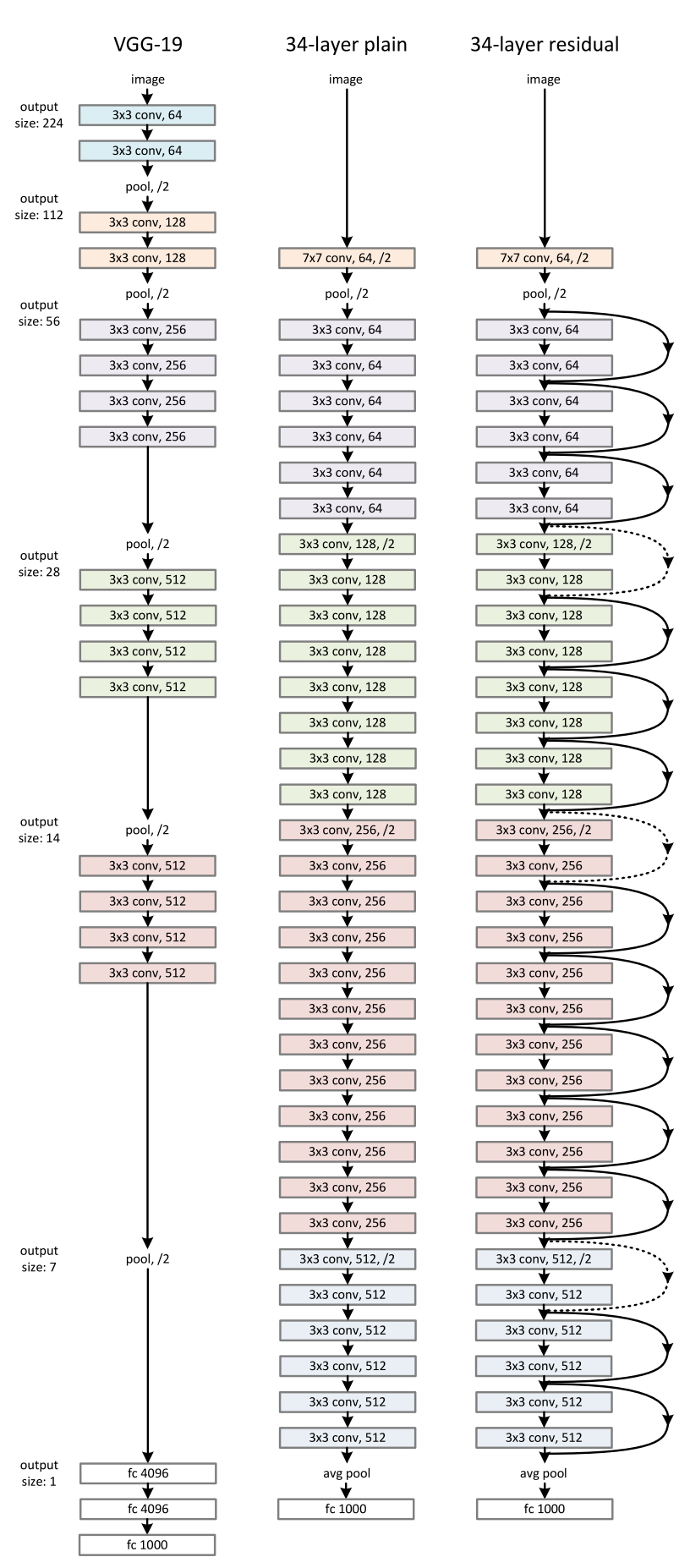
完整的ResNet 34的结构如下,其中所有的虚线表示该shortcut需要使用以上的方法进行channel的对齐
参数如下所示
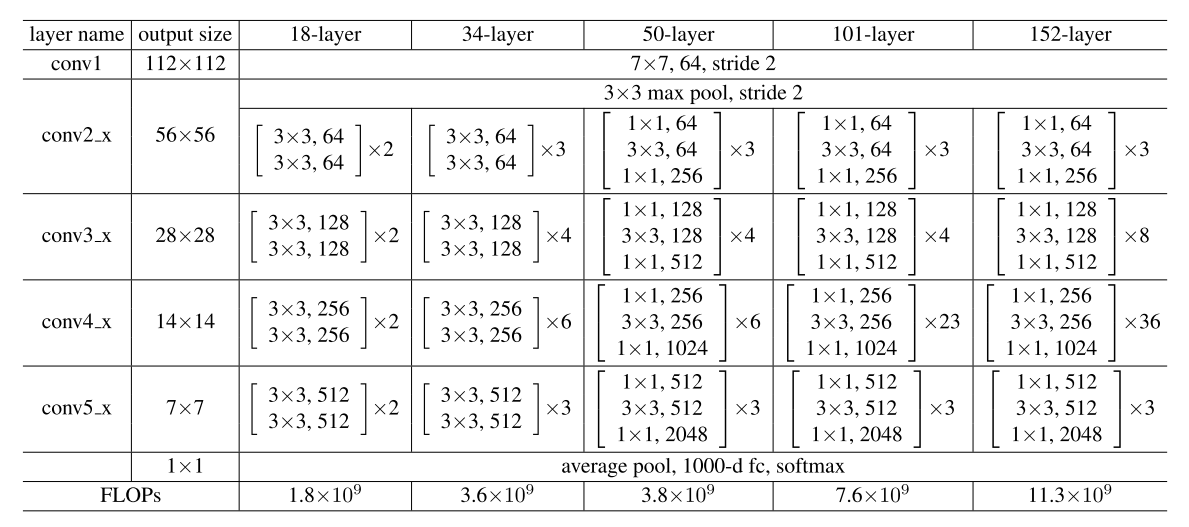
其中训练细节如下
- 使用Conv - BN - ReLU的结构,每个卷积层均采用该种连接方式
- 进行尺度放缩的增广,将短边放缩到[256,480]的范围内后随机剪裁224*224的图片进行训练
- 在测试时,使用10-crop测试,也就是从图片中随机剪裁出10个224*224的位置进行测试
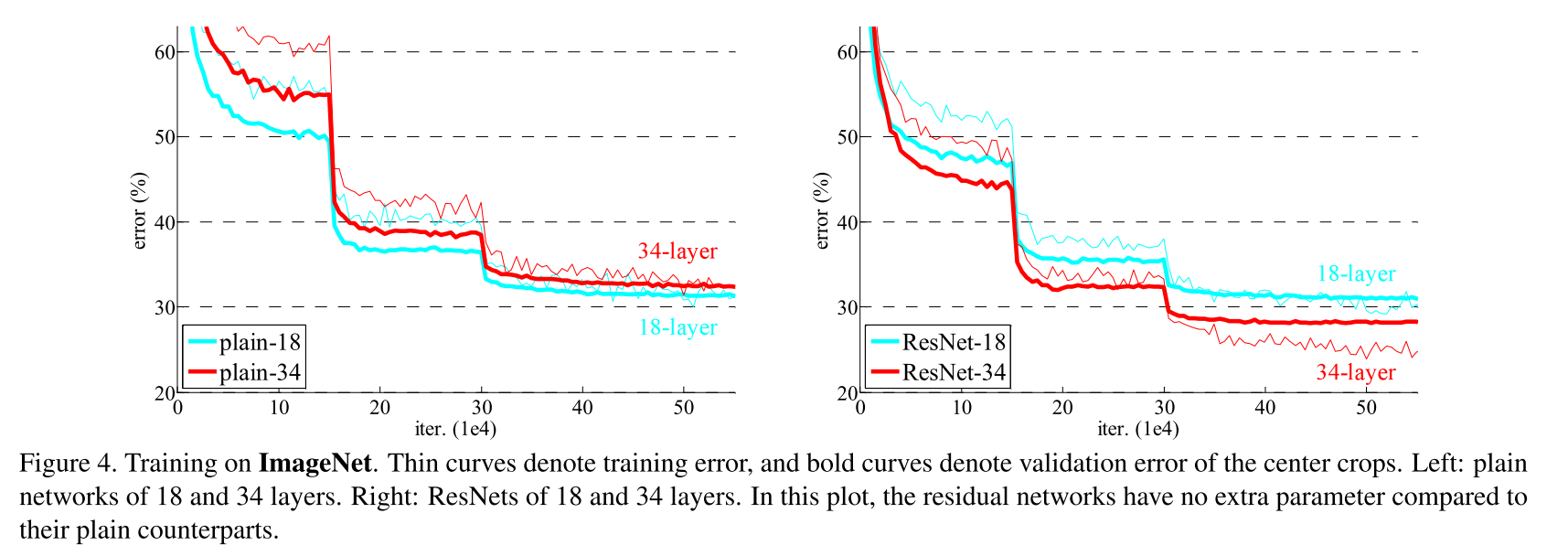
错误率随着迭代轮数的进行表现如下,其中左图为相同的连接结构,不使用shortcut的神经网络训练出来的结果,右侧为使用shortcut的结果
接下来,我们比较一下零填充和1*1的卷积核的优劣性,表现排名如下
- 全部使用1*1 卷积核,无论是否需要对齐channel
- 只在对齐channel时使用1*1的卷积核
- 使用零填充
尽管如此,这三种方式的表现差异不大,引入1*1的卷积核的表现更优可能是因为引入了新的需要学习的参数,真正需要引入1*1卷积核的地方是ResNet中著名的bottleneck的结构,如下图所示,其中左侧为朴素的ResNet Block,而右侧为使用了bottleneck结构的ResNet Block
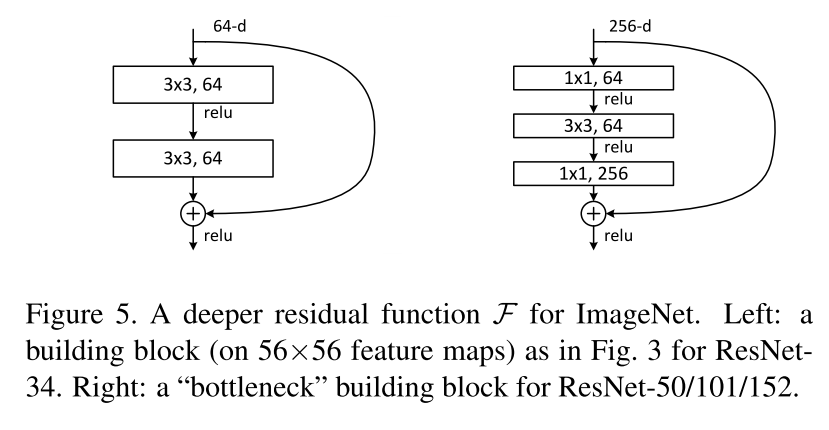
bottleneck结构的引入可以在网络深度较高的情况下有效的减小参数规模,便于训练,防止过拟合,因此在ResNet 50,ResNet 101 ResNet 152上均使用该结构代替朴素的ResNet Block。有关bottleneck和1*1卷积核对于参数规模的影响可以阅读我之前有关GoogLeNet的文章了解更多。
核心观点
- 恒等快捷连接的引入可以有效的缓解梯度消失/梯度爆炸的问题,大大增加了可训练网络模型的深度和表现能力。
- 再一次强调了1*1卷积核的作用,包括减小参数规模和对齐channel。

















 6331
6331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









