




目录
银行放贷时,如何快速判断一家企业是“优质客户”还是“潜在风险户”?基金筛选项目时,怎样凭借财务数据给企业风险等级“贴标签”?这些金融场景里的核心问题,其实都能靠“判别分析”来解决。
一、三种方法,各有“拿手好戏
01、距离判别法
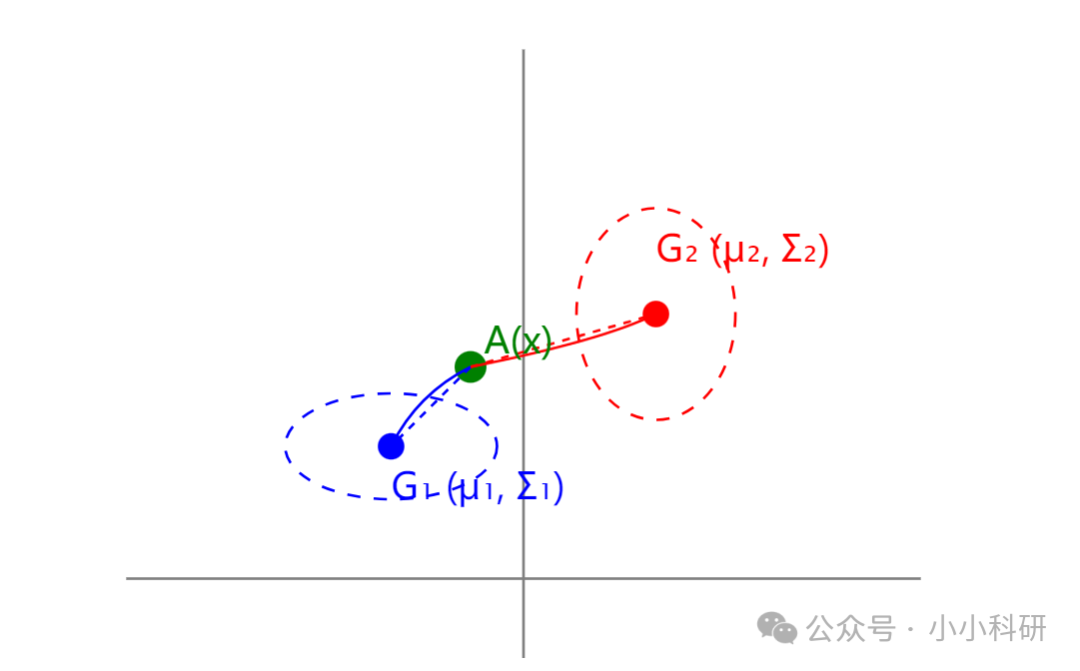
距离判别法的思路特别直白:把每个样本当成一个“数据点”,计算它到不同类别“中心”的距离,离哪个中心近就归到哪类。就像给低风险企业和高风险企业各画一个“特征中心”(比如低风险企业的资产负债率均值、流动比率均值等),新样本的数据点离低风险中心近,就暂判为低风险。
常用的是“马氏距离”(比欧式距离更合理,能消除特征单位和相关性影响)。比如计算新样本到低风险类的马氏距离D1,到高风险类的马氏距离D2,若D1相比D2更小,则判为低风险。
适用场景:样本分布相对规整,对“先验概率”(比如已知市场上低风险企业占比)不敏感时,比如初步的企业风险筛查。
下图中,分别计算A(x)到G1和G2的距离,判断A(x)该归为G1类。
02、Fisher判别法
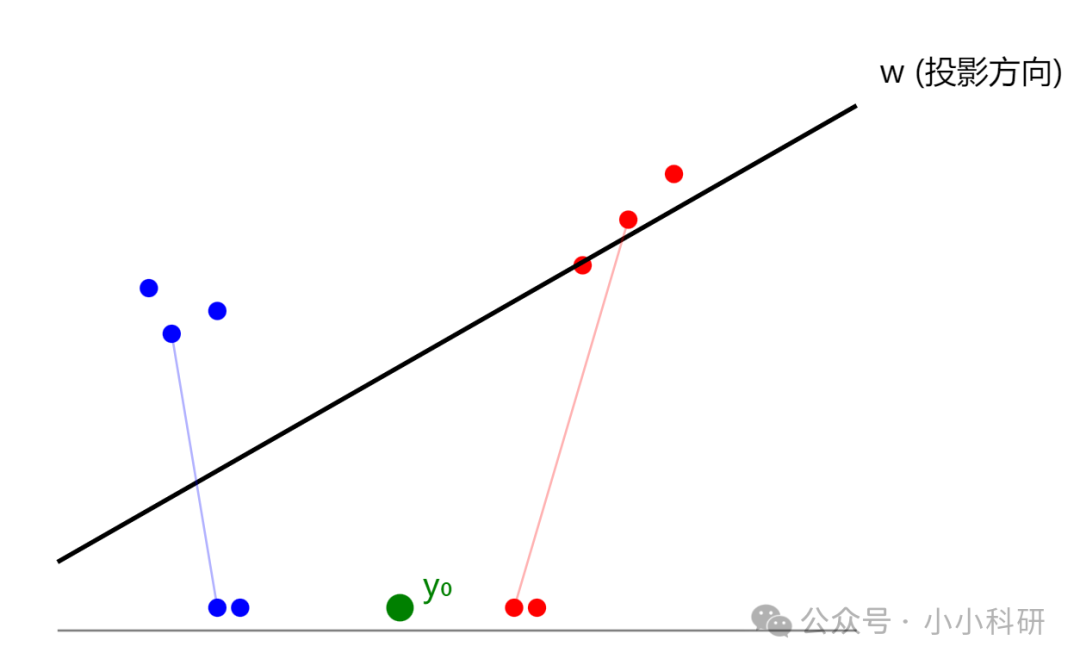
Fisher判别法不执着于“算距离”,而是找一个“投影方向”——把高维的财务特征(比如资产负债率、流动比率等)投影到一条直线上后,让低风险和高风险企业的投影点“尽可能分开”(同类聚在一起,异类离得远)。
就像看一堆混杂的企业数据,从某个角度看两类数据糊成一团,但Fisher判别能帮我们转个“视角”,让投影后的低风险点全挤在左边,高风险点全堆在右边,界限明明白白。
适用场景:多类别分类(比如除了低/高风险,还可分“中风险”),样本量不算特别大时,适合做精细化的风险分级。
下图中y0为决策边界,分为左边蓝色和右边红色两类。
03、贝叶斯判别法
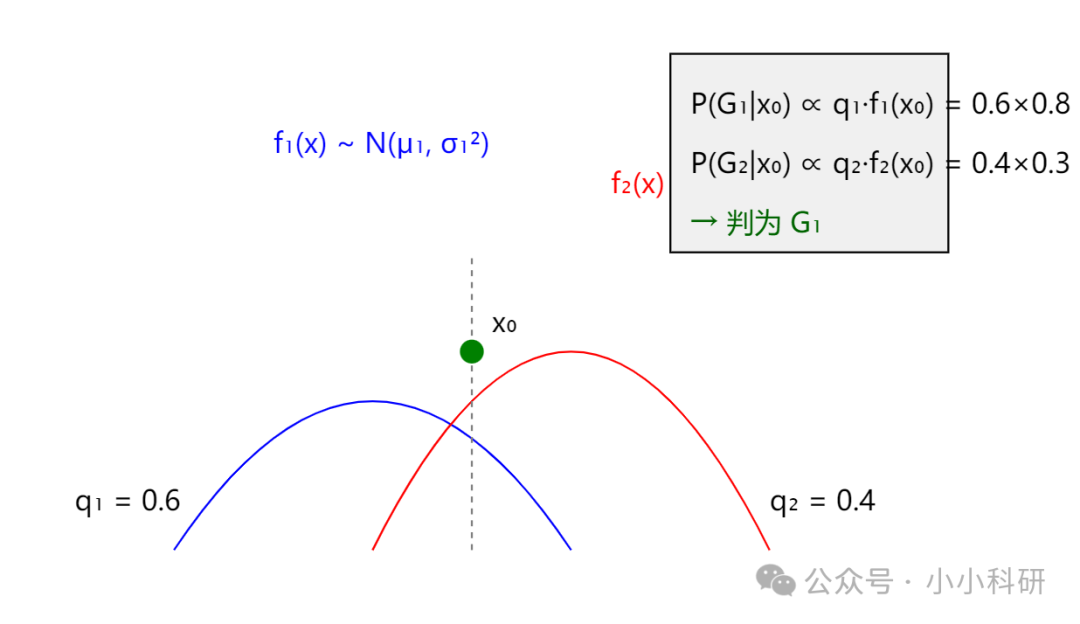
贝叶斯判别法更“聪明”——它会先考虑“先验概率”(比如根据经验,市场上70%的企业是低风险),再结合样本到类别的“似然度”(比如该企业特征符合低风险企业的概率),算出自“后验概率”(该企业是低风险的最终概率),按概率高低分类。
比如先知道低风险企业占比70%,再算得某企业特征“像低风险”的概率是80%,“像高风险”的概率是20%,最终算得它是低风险的后验概率远高于高风险,就判为低风险。
适用场景:已知各类别先验概率(有历史数据支撑)时,比如银行有多年的企业放贷风险记录,用它分类更贴合实际业务。
下图中,根据贝叶斯概率公式,计算得出该分为G1类。
二、四种方法一次跑通
我们用随机生成的企业金融数据做案例:包含“资产负债率(%)、流动比率、净利润增长率(%)”3个特征,标签0=低风险、1=高风险,共1000个样本。下面是整合了数据生成、3种判别方法+逻辑回归(作对比)训练的完整代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # Fisher判别
from sklearn.naive_bayes import GaussianNB # 贝叶斯判别(高斯假设)
from&nb 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











