 决策树与随机森林的关系解析
决策树与随机森林的关系解析




目录
一、引言
在集成学习领域,随机森林凭借优异的泛化性能与稳定性,成为解决复杂分类、回归问题的常用算法。而支撑随机森林实现高效决策的核心单元,正是决策树,它通过每一棵独立的决策树通过并行训练与结果融合,共同构成随机森林的强大能力。
文末有代码
二、模型原理
决策树模型的核心思想是模拟人类分层决策过程,将复杂问题分解为离散的判断节点,通过逐层筛选实现目标预测。
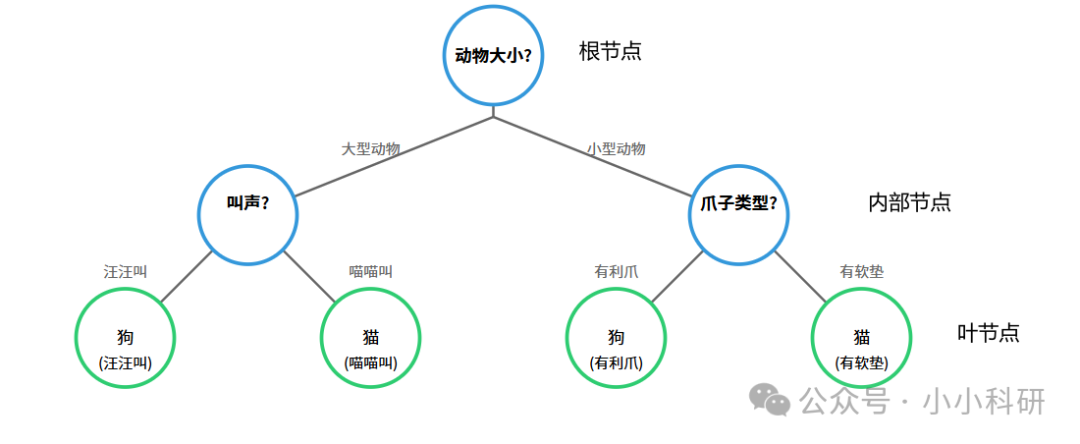
01、核心结构
1.根节点:决策流程的起始节点,代表分类问题的核心判断维度,也是随机森林子树筛选关键特征的首要环节。在随机森林中,多棵子树会通过特征随机选择,生成不同的根节点,最终通过投票融合提升模型稳定性。
2.内部节点:位于根节点与叶节点之间的中间判断单元,代表分类过程中的次级判断维度,是随机森林子树细化决策的核心环节。在随机森林中,多棵子树的内部节点判断逻辑差异,正是模型避免过拟合的关键。
3.叶节点:决策流程的终止节点,代表最终的分类结果。在随机森林中,所有子树的叶节点结果会通过多数投票机制,生成最终的全局预测结果。
02、最优划分特征的选择机制
决策树模型的关键在于确定各节点的判断维度,其本质是通过纯度指标量化分支后样本子集的同质性。主要是以下两种:
1.ID3 算法:以信息增益为核心指标,信息增益反映特征对样本不确定性的降低程度,信息增益越大,特征对分类结果的解释力越强。在随机森林中,子树会基于随机抽取的特征子集,通过信息增益选择最优特征,避免单棵树对全局特征的过度依赖。
2.CART 算法:以基尼系数为核心指标,基尼系数用于衡量样本子集的纯度,基尼系数越小,子集内样本的类别分布越集中。在随机森林中,多棵子树采用CART算法选择特征,可通过并行计算提升模型训练效率,同时降低单棵树的过拟合风险。
三、模型代码实现
基于 Python 的 scikit-learn 库,可以快速实现决策树模型的构建与训练。本文以鸢尾花数据集为例(包含 3 个类别、4 个特征,样本量为 150)进行演示
01、数据加载
# 1. 导入依赖库
from sklearn.datasets import load_iris # 加载鸢尾花数据集
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器(随机森林子树核心类)
from sklearn.model_selection import train_test_split # 导入数据集划分工具
# 2. 数据集加载与划分
iris = load_iris()
X = iris.data # 提取特征矩阵,包含花萼长度、花萼宽度、花瓣长度、花瓣宽度4个特征
y = iris.target # 提取标签向量,0代表山鸢尾,1代表变色鸢尾,2代表维吉尼亚鸢尾
# 按7:3比例划分训练集与测试集,random_state固定随机种子以保证实验可重复性(随机森林子树训练需统一数据划分)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 模型训练与性能评估(单棵决策树性能,随机森林子树的基础性能参考)
model = DecisionTreeClassifier() # 初始化决策树分类器(默认参数,对应随机森林单棵子树)
model.fit(X_train, y_train) # 基于训练集进行模型训练(随机森林子树的独立训练过程)
score = model.score(X_test, y_test) # 基于测试集计算模型准确率
print(f"单棵决策树模型准确率:{score:.2f}") # 输出准确率结果02、模型参数优化
默认参数构建的决策树易出现过拟合现象。通过调整决策树参数,可有效提升单棵树的泛化能力,进而优化随机森林的整体性能。决策树分类器的核心参数及优化策略如下表所示。
挑重点来说,就是max_depth控制最大深度,min_samples_split控制节点分裂的最小样本量,min_samples_leaf控制叶节点的最小样本量,criterion在分类问题中用gini。

# 初始化参数优化后的决策树分类器(可作为随机森林的base_estimator)
optimized_model = DecisionTreeClassifier(
max_depth=4, # 设定决策树最大深度为4(控制子树复杂度)
min_samples_split=5, # 设定节点分裂的最小样本量为5(提升子树稳定性)
min_samples_leaf=2, # 设定叶节点的最小样本量为2(保证决策可靠性)
criterion="gini" # 采用基尼系数作为纯度评估指标(适合随机森林并行计算)
)
optimized_model.fit(X_train, y_train) # 基于训练集训练优化后的模型(子树独立训练)
optimized_score = optimized_model.score(X_test, y_test) # 计算优化后的模型准确率
print(f"优化后单棵决策树模型准确率:{optimized_score:.2f}") # 输出优化后准确率四、模型可视化
模型训练完成后,仅通过准确率无法直观反映决策树的判断逻辑,而可视化可以帮助我们理解单棵决策树结构、进而掌握随机森林多树协同机制的关键。
如下图,每个节点包含三个核心信息:特征判断条件、节点包含的样本数量、样本类别分布,叶节点的颜色差异对应不同的分类结果。
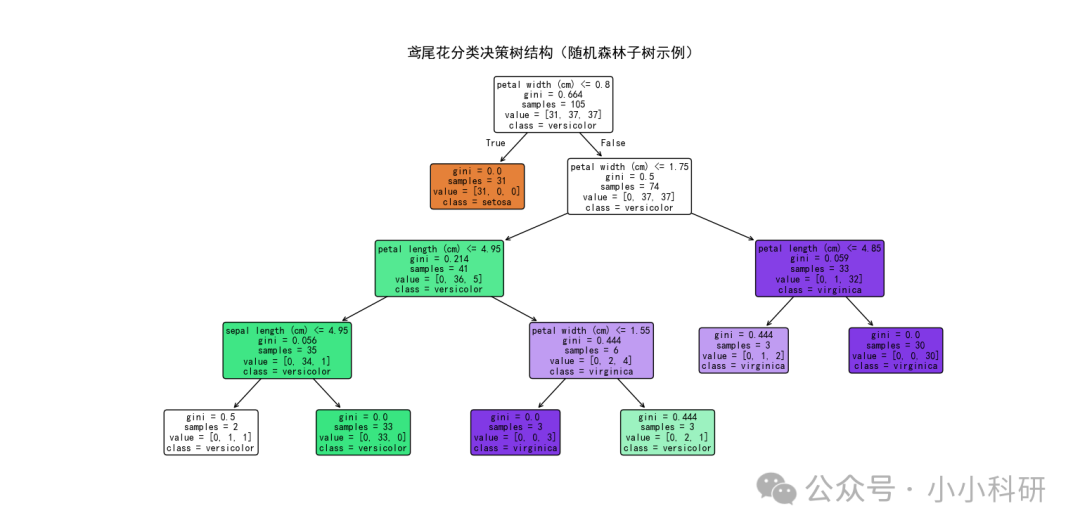
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 设置画布尺寸
plt.figure(figsize=(12, 8))
# 绘制决策树图形
plot_tree(
optimized_model,
filled=True, # 采用颜色填充叶节点,区分不同类别
feature_names=iris.feature_names, # 显示特征名称,如"sepal length (cm)"(对应随机森林子树的特征选择)
class_names=iris.target_names, # 显示类别名称,如"setosa""versicolor"(子树的分类目标)
rounded=True, # 采用圆角矩形绘制节点
fontsize=10 # 设定字体大小
)
plt.title("鸢尾花分类决策树结构", fontsize=15) # 设置图形标题
plt.show() # 显示图形,可通过plt.savefig("tree.png")命令保存图形决策树的核心局限性在于易过拟合。当模型深度较大、分支较多时,单棵树会过度学习训练集中的噪声数据,导致在测试集上的泛化性能下降。而随机森林能完美解决这一问题。
https://mp.weixin.qq.com/s/OuvNkn6XNdOHnF1ZbccyYA![]() https://mp.weixin.qq.com/s/OuvNkn6XNdOHnF1ZbccyYA
https://mp.weixin.qq.com/s/OuvNkn6XNdOHnF1ZbccyYA
请点击上方链接,关注【小小科研】公众号,了解更多模型哦,感谢支持!


















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











