



目录
一、情景导入
当你做重要决定时,假设你想要辞职,问一个人可能不靠谱,但问10个不同背景的朋友,综合他们的建议就更可靠——这就是随机森林的原理:它由上百棵"决策树"组成,每棵树就像一位专家,从不同角度分析数据,最后投票得出结果。但模型说"会离职"时,到底哪些因素影响了判断?shap分析就像"AI翻译官",能清晰告诉你:年龄、工资、加班时长等特征各自起了多大作用,让黑箱决策变得透明可解释。
二、模型介绍
1、随机森林+shap可解性模型
随机森林就像由多位专家组成的智囊团,每棵决策树基于随机数据独立判断,最终投票决策。这种机制使其预测既准确又稳定。想象一下,当你面临重大决策比如是否辞职时,只问一个朋友的意见可能不够全面,但如果问10个不同行业的朋友,综合他们的建议会更可靠。随机森林就是这样工作的:它由一群“树精”组成,每棵决策树都像一个懂行的顾问,各自基于随机抽取的数据和特征提出意见,最后通过民主投票来拍板结果。这种模型属于集成学习中的Bagging思想,核心在于“随机性”——每棵树使用有放回的抽样训练数据,并在分叉时随机选择特征子集,确保多样性,避免了单棵树可能导致的偏见。
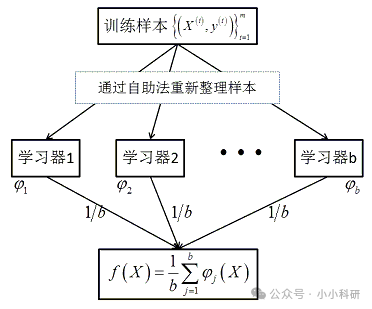
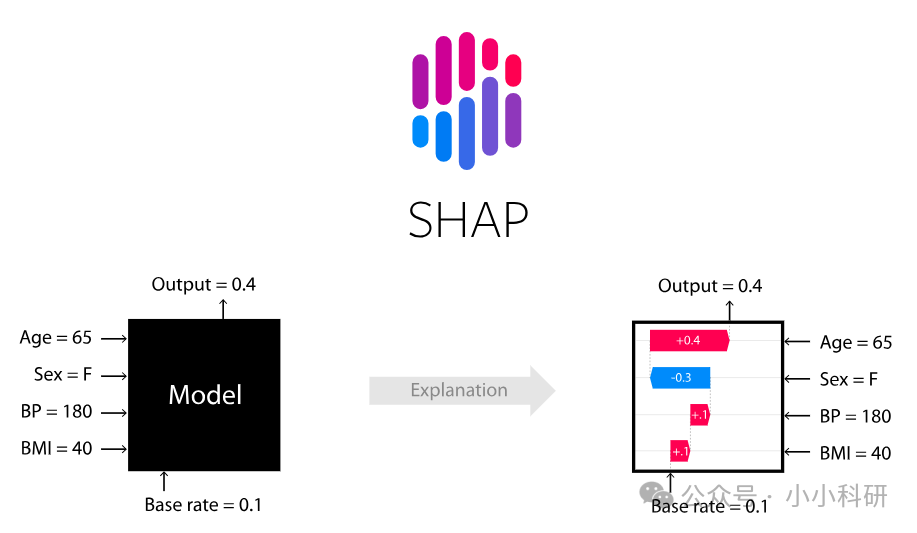
而SHAP分析则像一位决策解读专家,SHAP 值基于博弈论中的 Shapley 值,能量化每个特征对单个预测的贡献,是模型可解释性分析的重要工具。
-
量化每个特征对结果的具体影响
-
提供整体和个案两个层面的解释
-
确保决策过程透明可追溯
三、模型原理
1、随机森林模型
信息增益:让决策树变 “机灵” 的秘诀
决策树的“机灵”,在于优先选择能让分叉效果更好的特征。比如给水果分类,究竟先按“颜色”还是“形状”分?这就需要靠信息增益来判断——它能衡量分叉后数据混乱度的减少程度。要是按“形状”分能让同类水果更集中,混乱度下降更多,那“形状”的信息增益就大,会被优先用来分叉。这种逻辑让决策树像剥洋葱一样层层拆解问题,每一步都选当前最优方案,保证模型高效运行。
从专业角度看,信息增益的计算公式是IG(Y,X) = H(Y) - H(Y|X),其中H(Y)是数据集的熵(用来表示混乱程度),H(Y|X)是特征A条件下的条件熵。
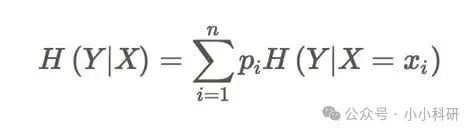
简单来说,信息增益越大,该特征对决策的贡献就越强。在随机森林里,每棵树都会依靠这种机制,用贪心算法选择信息增益最大的特征进行分裂,不断重复这一过程,直到节点纯度达标或样本量足够小。这一过程确保了模型处理数据时既“聪明”又高效,避免了无效分叉。
树分叉:像剥洋葱一样层层拆解问题
决策树分叉如同剥洋葱,由外及内层层深入。比如判断 “是否是好瓜”,先依据信息增益最大的 “甜度”(甜的大概率是好瓜),再在甜瓜中看 “纹路”(清晰的更靠谱),逐层分析直到得出结论。这种方式让 AI 决策直观易懂,每步都追求当前最优解,像日常解决问题那样先抓重点再处理细节,确保路径高效精准。
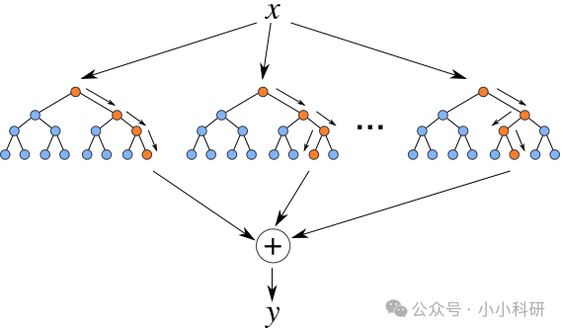
其核心是贪心算法:从根节点(原始问题)出发,每次选信息增益最大的特征分裂,重复至满足停止条件(如节点样本同类或数量太少),避免不必要的复杂分叉。而随机森林中,多棵树通过这种 “剥洋葱” 方式共同作用,综合结果能大幅提升稳定性。专业来看,这种设计因每棵树仅关注部分数据和特征,可有效降低过拟合风险,让整体模型在投票中更鲁棒,尤其适合处理含噪声多的现实数据。
2、SHAP库解释模型
SHAP 可解释性原理,简单说就是为模型决策生成 “特征贡献明细单”,清晰呈现每个特征的作用。
# 初始化SHAP解释器(针对树模型优化)
explainer = shap.TreeExplainer(rf_model)#
计算测试集的SHAP值
shap_values = explainer.shap_values(X_test)
if isinstance(shap_values, list):
shap_values = shap_values[1] # 二分类问题取正类的SHAP值
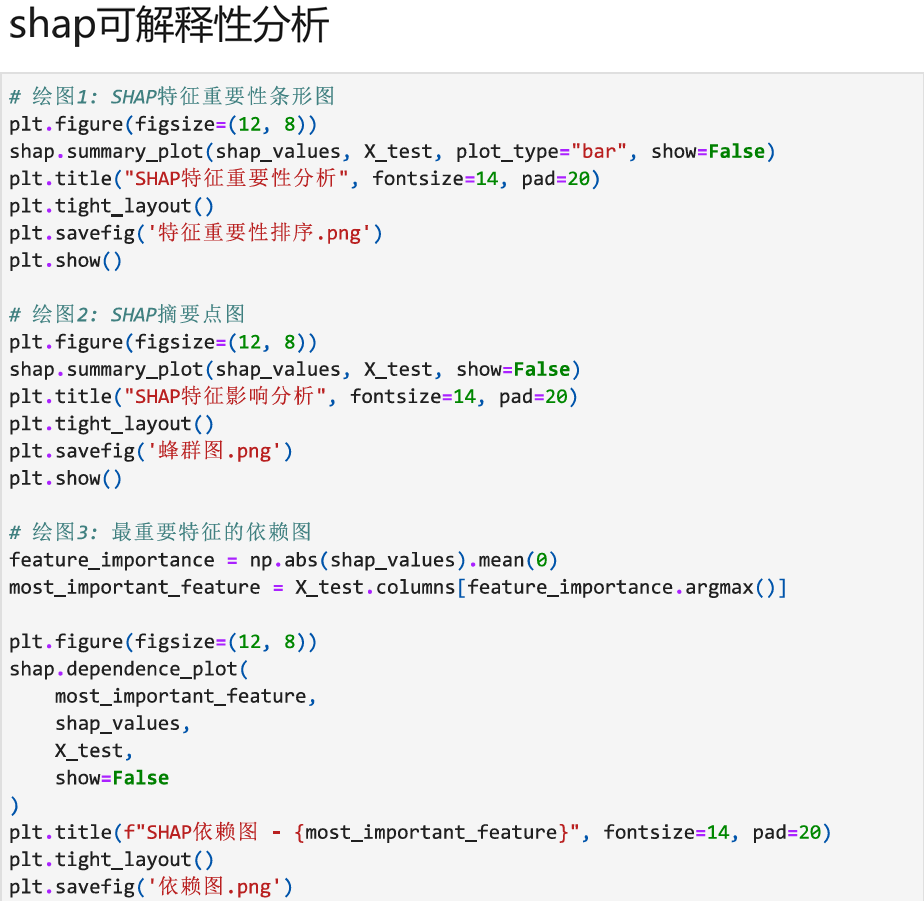
#绘制SHAP特征重要性条形图
plt.figure(figsize=(12,8))
shap.summary_plot(shap_values,X_test,plot_type="bar",show=false)
plt.title("SHAP Feature Important Analysis",fontsize=14,pad=20)
plt.tight_layout()plt.show()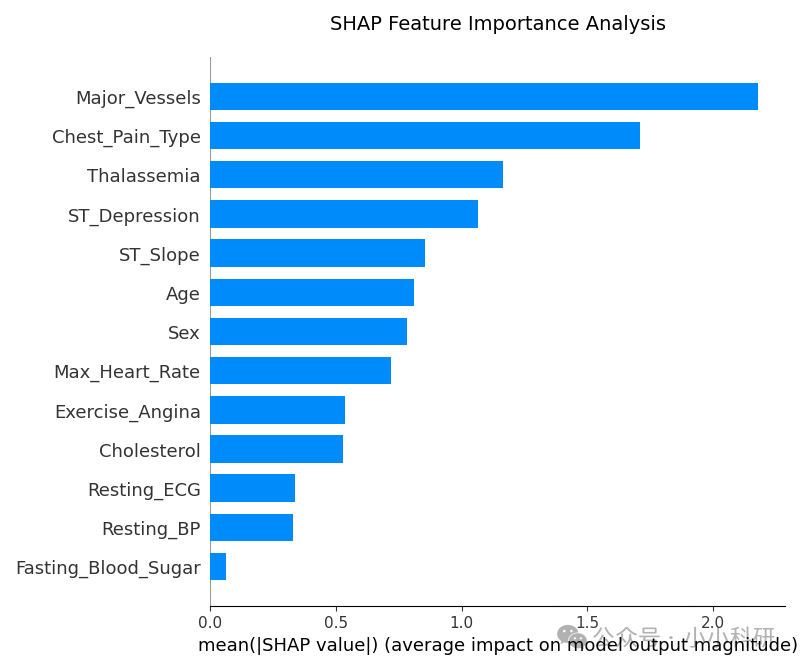
使用shap库后,我们可以清楚地看到每个特征对模型的贡献度分别为多少,并且可以得出结论:
主要血管数量(Major Vessels)是最具影响力的特征,重要性得分高达2.1795,表明它是预测心脏病的最关键指标。
胸痛类型(Chest Pain Type)紧随其后,重要性为1.7118,是第二关键的预测因素。
地中海贫血(Thalassemia)和ST段压低(ST Depression)分别以1.1645和1.0640的重要性得分位列第三和第四。
空腹血糖(Fasting Blood Sugar)的重要性最低(0.0618),对预测结果影响较小。
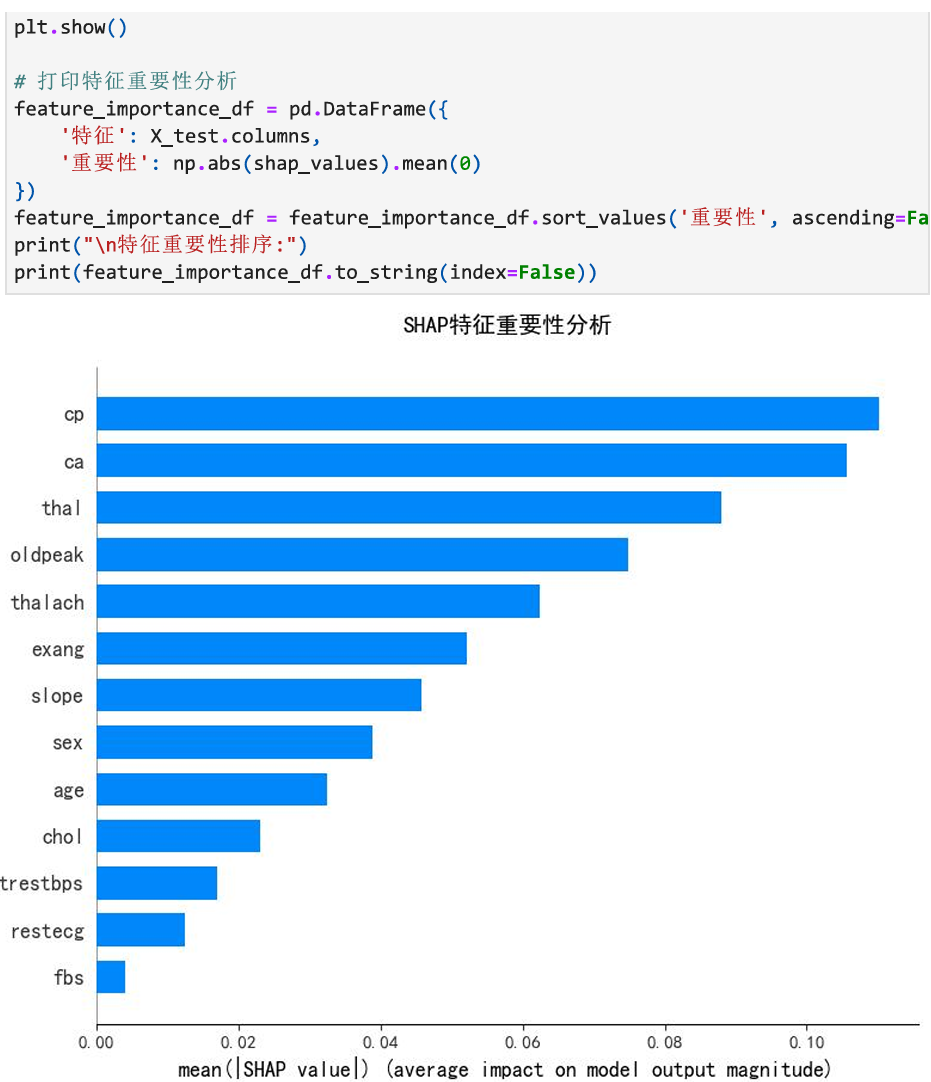
从下图我们可以看出:
正向影响最强的特征:
ST段压低(ST Depression):+0.1160
胆固醇(Cholesterol):+0.0648
运动诱发心绞痛(Exercise Angina):+0.0646
负向影响最强的特征:
最大心率(Max Heart Rate):-0.1250
ST段斜率(ST Slope):-0.0489
主要血管数量(Major Vessels):-0.0467
# 绘制SHAP摘要点图
plt.figure(figsize=(12, 8))
shap.summary_plot(shap_values, X_test, show=False)
plt.title("SHAP Feature Impact Analysis", fontsize=14, pad=20)
plt.tight_layout()plt.show()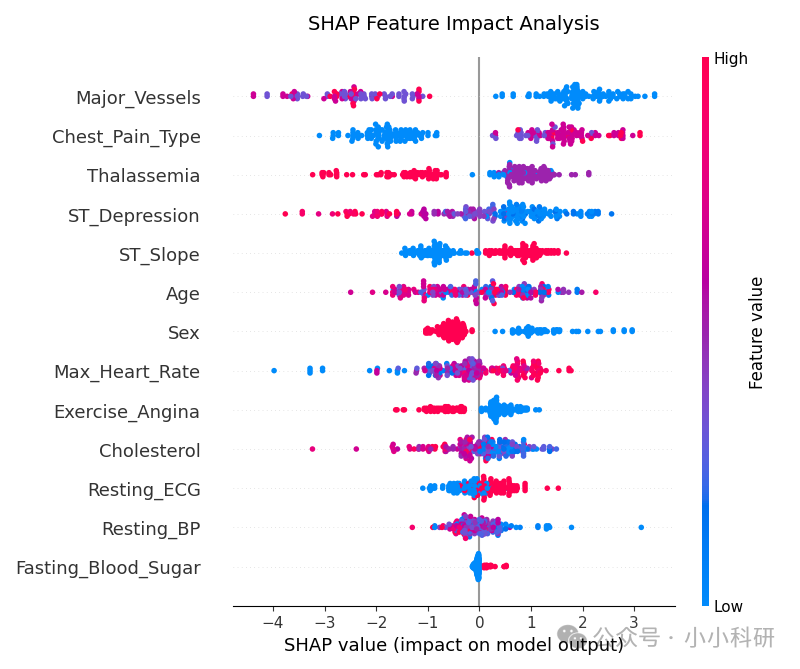
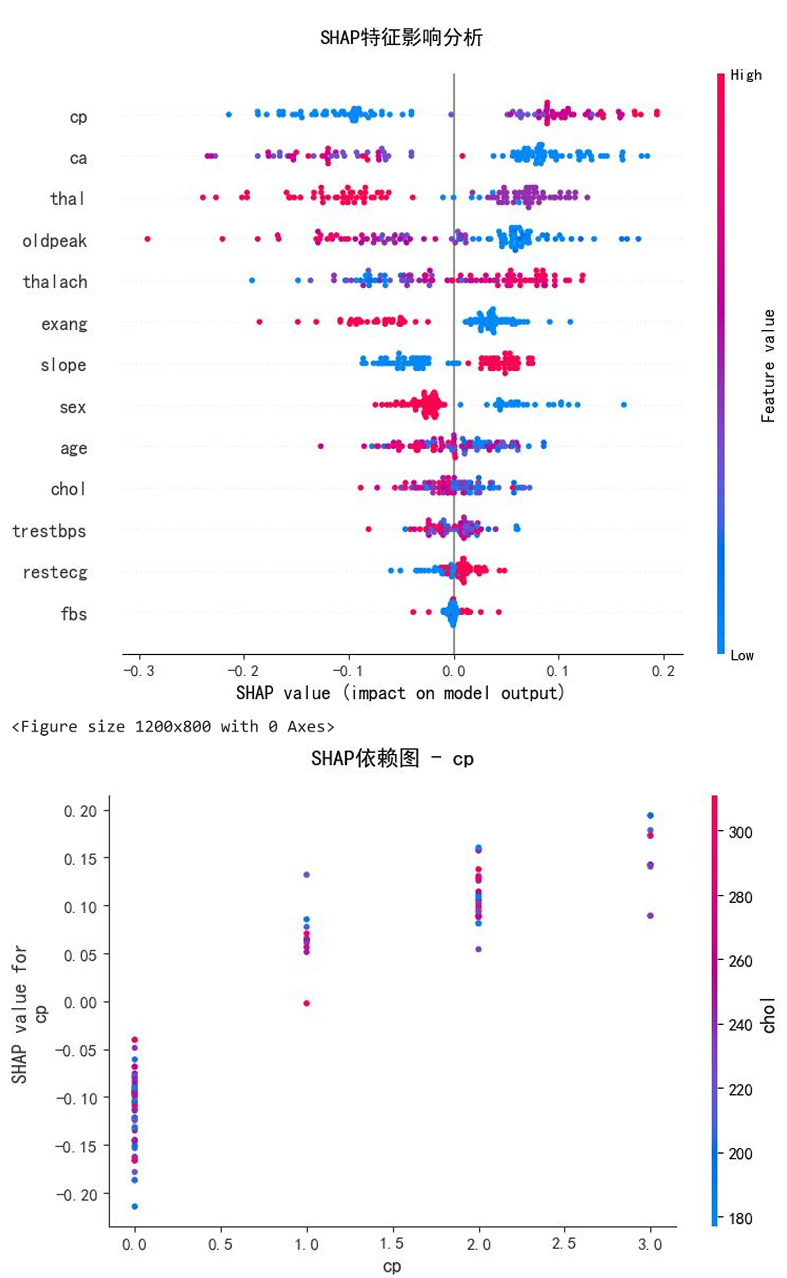
在实际运用时,应更加关注主要血管数量,胸疼类型,地中海贫血等临床特征,空腹血糖可以减少关注,ST段压低,胆固醇,运动诱发心绞痛会增加确诊的可能性,应重点关注这些特征。(仅作为讲解需要,不能作为医学参考)
四、实战操作


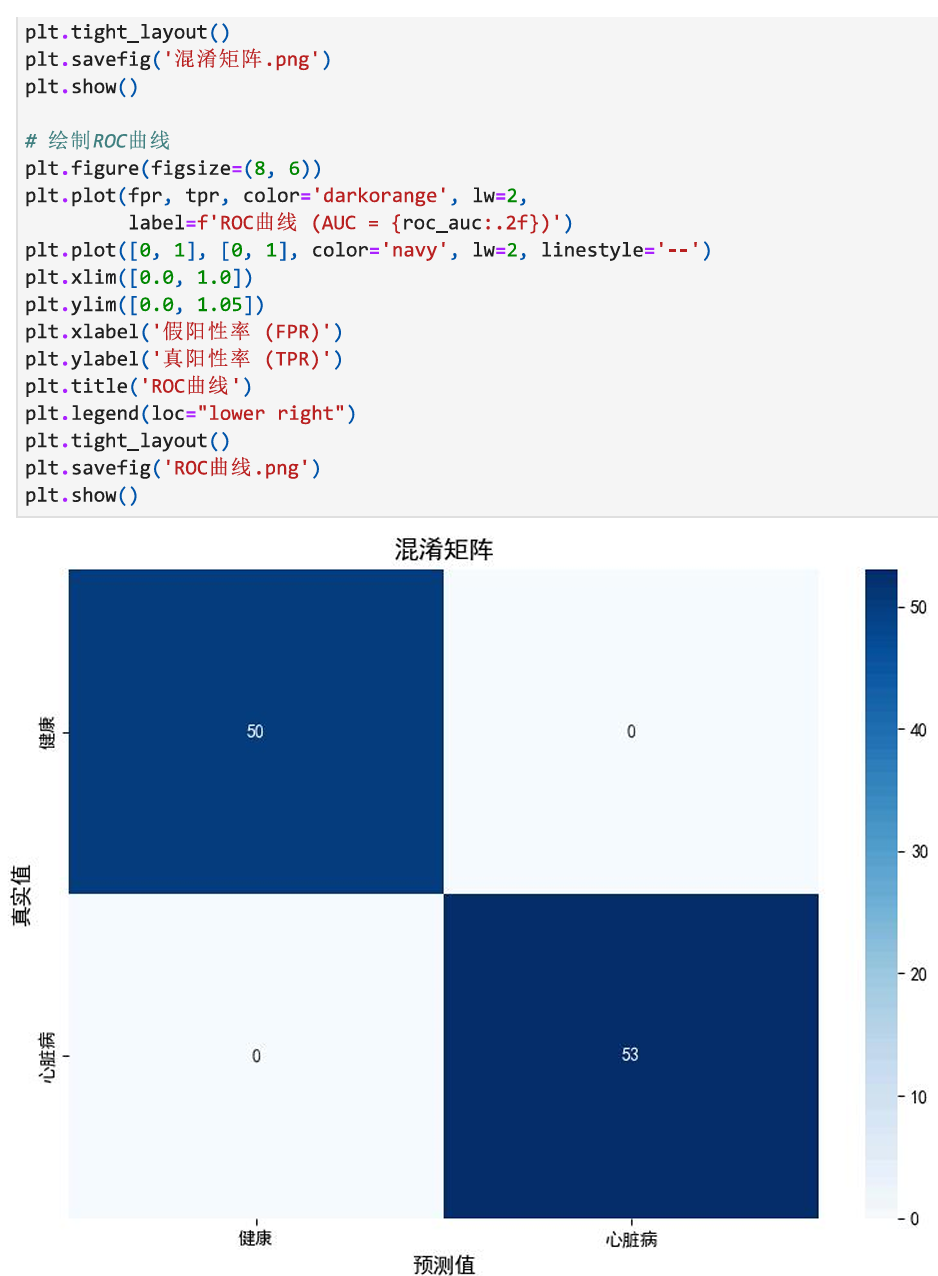
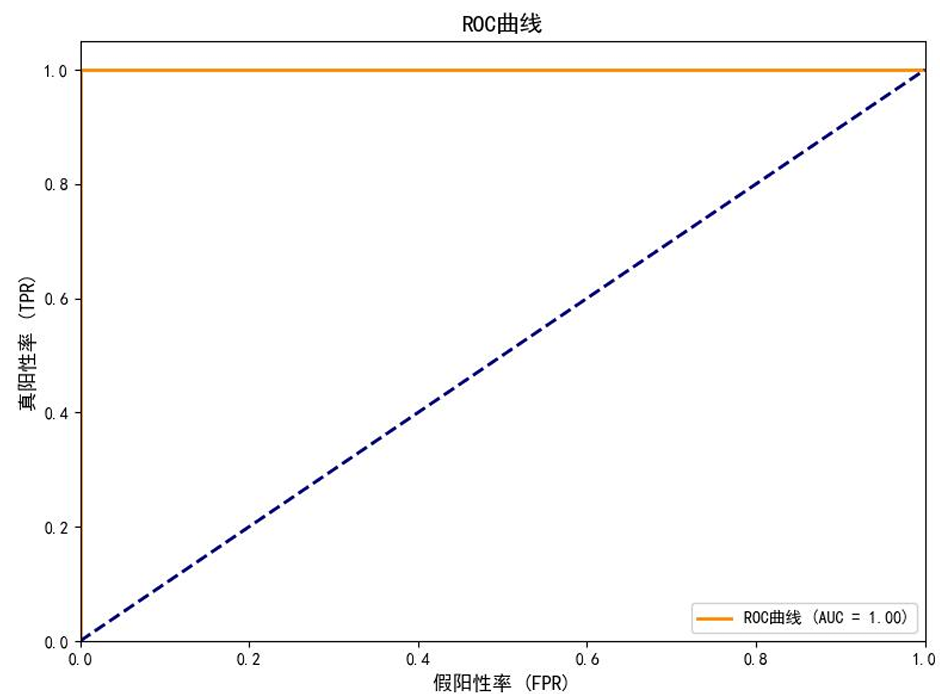


想了解更多细节或获取代码的朋友,欢迎关注【小小科研】公众号私信留言即可~ 感谢支持!


















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











