



画中画:图像中有区别于原图的小图像,小图像的边界在原图中比较清晰类似(肖像图,艺术图,图中小的手机屏幕等),例如下面图像:

一、DPNet: Dynamic Pooling Network for Tiny Object Detection
核心问题:解决微小物体检测中,单纯放大图像带来的计算成本激增和负样本增多的问题。
解决方案:提出一种动态池化网络,用于在无人机系统等复杂环境中高效检测微小物体。
研究背景与动机
在无人机系统等场景中,图像包含大量微小物体(尺寸小、信噪比低),准确检测它们至关重要。常见的策略包括:
缩小图像:使物体尺寸接近预训练模型尺度,但会导致信息丢失。
放大图像:使微小物体在图像中变大,便于检测,但会显著增加计算量(GFLOPs)和背景负样本,降低检测效率,甚至导致性能下降。
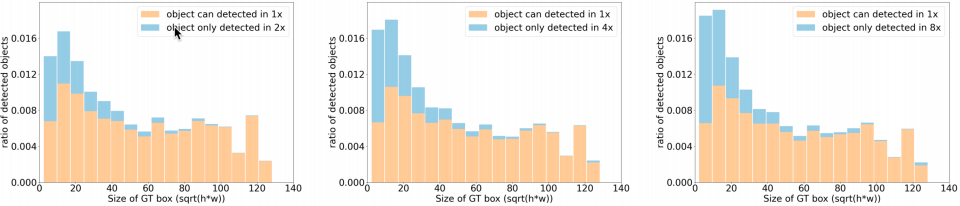
关键发现:
-
放大图像对微小物体检测性能提升显著,但对中大物体无效,甚至引入计算冗余。
-
需要一种能根据输入图像内容动态调整分辨率的策略,平衡精度与效率。
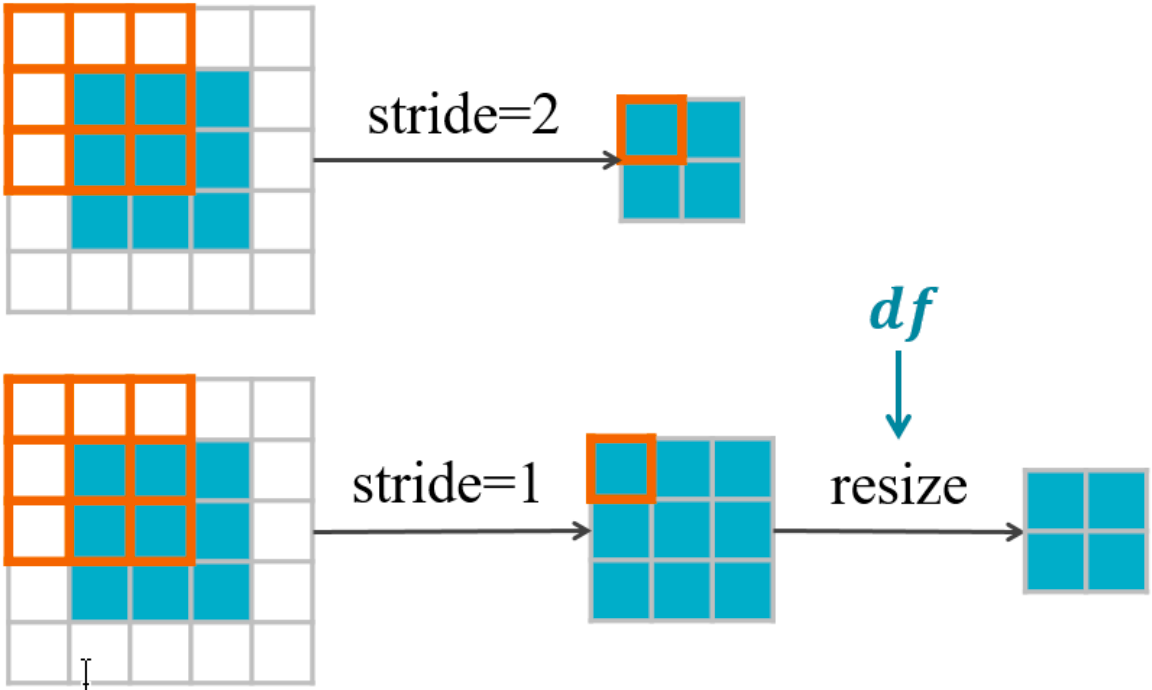
DPNet 核心方法
DPNet 通过动态调整特征图的下采样因子(down-sampling factor, df),实现计算资源的自适应分配。
1. 整体框架
输入图像放大:保留微小物体信息。
动态下采样:在骨干网络中,用双线性插值替代固定步长的卷积/池化,通过 df灵活调整特征图分辨率。
轻量级预测器(DFP):预测每张图的最佳 df,减少冗余计算。
自适应归一化模块(ANM):解决不同 df导致的特征分布差异,确保检测器兼容多尺度特征。
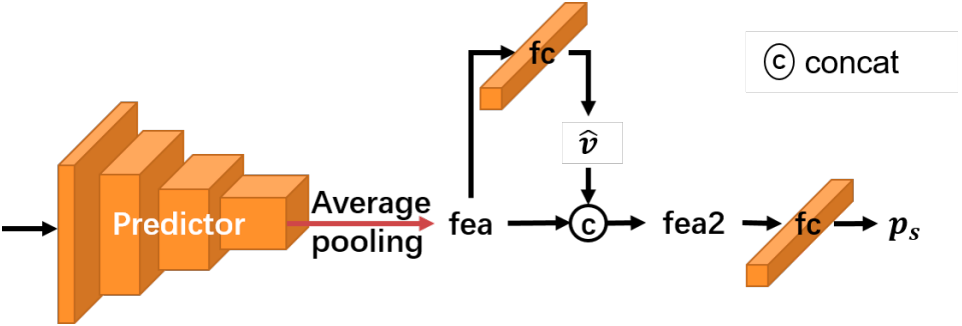
2. 关键技术组件
(1)混合下采样因子训练(MST)训练时对同一图像应用多个候选df(如0.5、0.33、0.25),求和多尺度损失,使检测器适应不同分辨率。
(2)自适应归一化模块(ANM)为每个df配置独立的归一化层,解决特征分布不一致问题:
,其中j对应不同df的私有参数。

(3)下采样因子预测器(DFP)
结构:轻量级卷积网络(如下图),包含统计分支预测物体数量、尺寸均值等,辅助 df决策。
引导损失(Guidance Loss):根据检测损失动态生成 df标签,监督 DFP 选择最优 df。
实验结果
1. 数据集与评估指标
TinyCOCO:COCO100(图像短边缩至100像素),关注微小物体。
TinyPerson:无人机航拍数据集,专用于微小人体检测。
指标:、
、
(IoU阈值0.5/0.75),兼顾精度与召回。
2. 消融实验
ANM 有效性:混合训练(MF)不加 ANM 时性能下降超5点;加入 ANM 后,各 df下性能接近单尺度训练(SF)。
DFP 有效性:相比随机选择 df,DFP 提升 mAP 约1%。
引导损失:使用引导损失监督 DFP,进一步提升性能上限。
3. 性能对比
TinyCOCO:DPNet 在 ResNet-50 骨干上节省35% GFLOPs,性能与全尺寸输入相当。
TinyPerson:在上达到52.33,优于 RetinaNet-SM 等基线。
DOTA/VisDrone:在航拍目标检测任务中达到最优精度-效率平衡。
4. 可视化分析
DFP 决策合理性:物体大而明显的图像分配小 df(0.25),物体微小图像分配大 df(0.5)。
检测效果:DPNet 在密集场景(如VisDrone)中漏检更少,对微小目标(车辆、行人)检测更准确。
创新点与意义
首次将动态网络引入检测任务:通过df动态调整特征图分辨率,平衡精度与计算效率。
ANM 模块:解决多尺度训练中的特征分布偏移问题。
轻量级 DFP 预测器:根据图像内容自适应选择df,减少冗余计算。
实战价值:为无人机、自动驾驶等资源受限场景提供高效检测方案。
二、MLLMS KNOW WHERE TO LOOK
核心问题:多模态大语言模型在视觉问答任务中,对图像中微小视觉细节的感知能力不足
解决方案:提出了无需训练即可缓解该问题的创新性方法。
研究背景与动机
多模态大语言模型在多种视觉语言任务上取得了显著进展,并被应用于机器人、自动驾驶等关键领域。因此,深刻理解其视觉感知的局限性至关重要。当询问MLLMs关于图像中一个尺寸较小的物体(如路牌、鸟类)时,模型可能无法正确识别或给出低置信度的答案;然而,当图像被裁剪放大,聚焦于该小物体后,模型给出正确答案的概率显著提升。
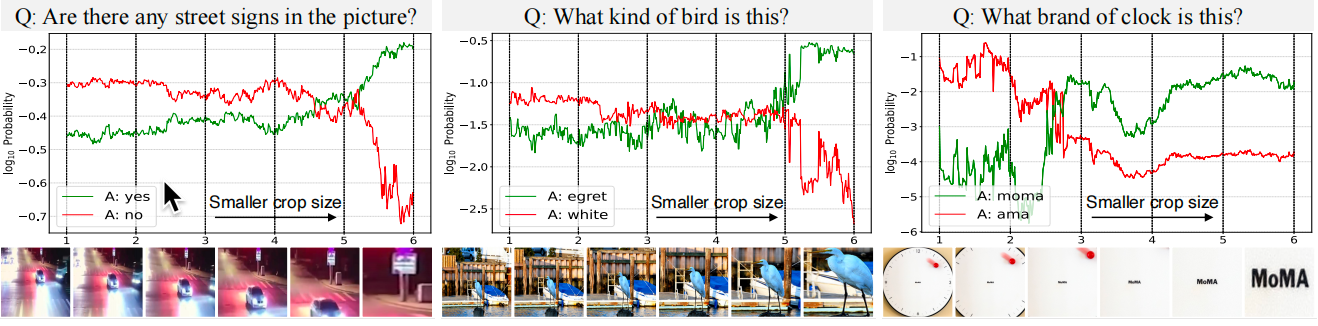
这个现象表明,MLLMs的感知能力对视觉概念的尺寸非常敏感。论文随之提出两个可能的原因:
定位困难:模型无法在复杂的图像中找到与问题相关的微小区域。
感知困难:模型找到了相关区域,但无法从有限的像素中提取出足够的细节信息。
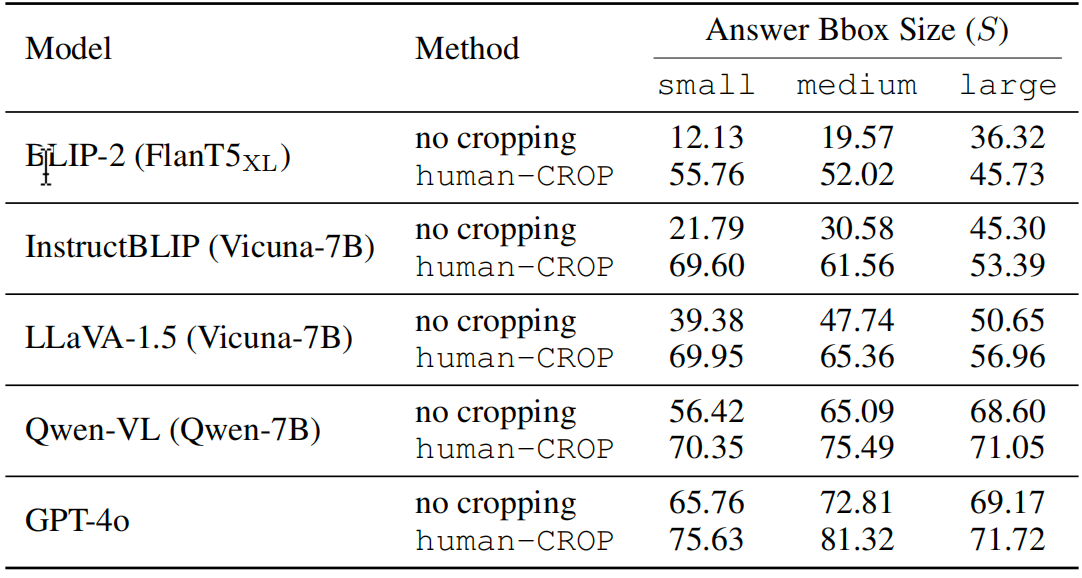
定量验证:MLLMs对视觉概念尺寸的敏感性
为了定量验证上述观察,作者在 TextVQA 数据集上进行了实验。该数据集的特点是其答案通常是图像中的文字,难以从上下文猜出,能更好地测试模型的真实视觉感知能力。
1. 方法
根据答案所在边界框相对于整张图像的相对面积,将数据分为三组:小(
)、中(
)、大(
)。
2. 结果
所有被测MLLMs(包括BLIP-2, InstructBLIP, LLaVA-1.5, Qwen-VL乃至商业模型GPT-4o)在“小”组上的准确率均显著低于“大”组,这证实了MLLMs普遍存在对微小视觉概念的感知偏差。
3. 因果干预实验
为了证明这种性能下降是尺寸“导致”的,而非仅仅是相关,作者进行了干预实验:直接根据真实答案框裁剪图像(称为 human-CROP),并将裁剪后的图像连同原图一起输入模型。结果发现,这种人工裁剪显著提升了所有模型在“小”和“中”组上的性能。这表明,视觉概念的尺寸是导致感知困难的因果因素,而视觉裁剪是可行的解决方案。
关键发现:MLLMs “知道该看哪里”
接下来,论文探究了问题的根源究竟是“定位困难”还是“感知困难”。作者创新性地分析了模型内部的注意力机制。
方法:通过计算模型的相对注意力,即针对特定问题的注意力与针对一个通用指令(如“描述这张图片”)的注意力之比,来凸显与问题语义相关的区域。
核心发现:如下图所示,即使模型回答错误,其注意力也显著地集中在正确答案所在的真实边界框区域内。这意味着,MLLMs能够有效地定位到与问题相关的图像区域,即使它们无法根据该区域的细节给出正确答案。
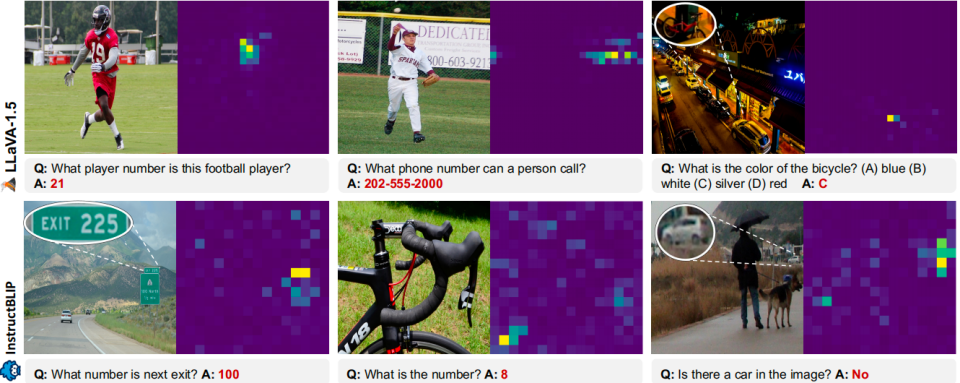
因此得出结论:MLLMs的局限性主要在于感知细节的能力不足,而非定位能力不足。
解决方案:无需训练的自动视觉裁剪方法
基于“模型知道该看哪里”这一关键发现,作者提出了三种无需训练的自动视觉裁剪方法,统称为 ViCrop。其核心思想是利用模型自身的内部状态(注意力、梯度)来定位感兴趣区域,然后对该区域进行裁剪放大,并将放大后的图像令牌与原图令牌一同输入模型,从而在不丢失全局上下文的前提下增强对细节的感知。
论文中提出的三种无需训练的自动视觉裁剪方法:Relative Attention ViCrop (rel-att)、Gradient-Weighted Attention ViCrop (grad-att) 和 Input Gradient ViCrop (pure-grad)。这三种方法的共同目标都是利用模型自身的内部信息,自动定位图像中与问题最相关的区域并进行裁剪放大。
1. 核心思想与流程概览
三种方法都遵循一个核心流程,如下图所示:
定位:基于不同的内部信号(注意力或梯度)为图像的每个区域生成一个“重要性地图”。
选择:使用滑动窗口算法,找到重要性地图中响应最强的区域作为裁剪候选框。
增强:将候选区域裁剪出来,缩放至模型的标准输入尺寸,并将这张“特写”图像的令牌与原始全景图像的令牌拼接在一起,输入给MLLM。这样,模型既能获得全局上下文,又能看清关键细节。

2. 三种方法详解
方法一:Relative Attention ViCrop (rel-att)
理论基础:直接使用论文第4节中定义的相对注意力。相对注意力通过将针对特定问题
的注意力与针对一个通用指令
(如“描述这张图片”)的注意力相除,来抑制那些虽然被高度关注但与当前问题语义无关的区域(例如,Transformer可能用作信息寄存器的令牌),从而凸显出与问题真正相关的区域。
操作步骤:
-
计算相对注意力:对于给定的图像-问题对
,进行两次前向传播:
-
一次用于计算回答问题时,起始答案令牌对图像各区域的注意力
。
-
另一次用于计算回答通用指令q′时的注意力
。
-
两者进行逐元素相除,得到相对注意力图:
。
-
-
选择目标层:MLLM有多个注意力层。作者在一个小的留出数据集上进行了消融实验,为每个模型选择了一个最具信息量的特定层(的相对注意力图作为最终的重要性地图。
-
生成裁剪框:将选定的相对注意力图作为重要性地图,输入到后续的滑动窗口算法中。
优缺点:
-
优点:概念清晰,直接基于模型的注意力机制,实验证明其对层的选择不敏感,表现鲁棒。
-
缺点:需要额外的第二次前向传播来计算通用指令的注意力,增加了计算成本。
方法二:Gradient-Weighted Attention ViCrop (grad-att)
该方法旨在避免rel-att的二次前向传播,转而使用梯度作为注意力的权重,以衡量每个注意力对模型决策的语义相关性。
理论基础:一个注意力权重所对应的区域,如果其微小的变化能显著影响模型的决策置信度,那么这个区域对回答问题就是高度相关的。梯度正好衡量了这种敏感性。
操作步骤:
-
获取可微分的决策置信度:定义$
$,其中$z$是LLM在起始答案位置的输出逻辑值,
是概率最高的令牌索引。
代表了模型对最可能答案的置信度的对数,是一个可微分的标量。
-
计算梯度加权注意力:
-
计算答案到令牌注意力 Ast和令牌到图像注意力
相对于
-
使用ReLU函数
过滤掉负梯度,因为负梯度对应的区域会降低模型置信度,通常是干扰项。
-
生成梯度加权的注意力图:
和
,其中
是逐元素相乘。
-
最终,梯度加权的答案到图像注意力为:
。
-
-
生成裁剪框:使用与rel-att相同的目标层,从
中提取重要性地图,并输入滑动窗口算法。
优缺点:
-
优点:无需第二次前向传播,效率高于rel-att。
-
缺点:需要计算梯度,实现稍复杂;消融实验显示其性能对层的选择更敏感。
方法三:Input Gradient ViCrop (pure-grad)
这是最通用的一种方法,它完全不依赖于Transformer的注意力机制,直接通过输入图像的梯度来定位关键区域。
理论基础:类似于Grad-CAM的思想,通过计算模型决策相对于输入图像像素的梯度,梯度值大的地方意味着该像素的微小变化会对决策产生巨大影响,因此这些像素是关键的。
操作步骤:
-
计算输入梯度:计算决策置信度 v(定义同grad-att)相对于输入图像 x的梯度,并取$L2$范数(跨通道)得到初始的重要性地图:
。
-
边缘增强:原始梯度图的一个问题是,可能在颜色均匀的无细节区域(如蓝天)也有高响应。为解决此问题,作者进行了后处理:
-
对原图应用一个
的高斯高通滤波器,突出边缘和纹理。
-
对滤波后的图像进行中值滤波去噪。
-
将结果二值化(以中值为阈值),得到一个强调边缘的掩码。
-
将该掩码与初始梯度图
逐元素相乘,得到边缘增强的梯度图。这一步确保只关注包含视觉细节的边缘区域。
-
-
下采样至Patch级别:将处理后的梯度图进行空间平均池化,下采样至与MLLM的图像编码器相同的
网格大小,作为最终的重要性地图。
优缺点:
-
优点:不依赖于特定的模型架构(如注意力机制),适用于任何可微分的模型,通用性极强。
-
缺点:计算梯度相对于输入的计算量较大;后处理步骤需要精心设计参数。
实验评估与结果
作者在7个VQA基准数据集上评估了ViCrop方法,其中4个对细节敏感(如TextVQA, V*, POPE),3个为通用数据集(如GQA, AOKVQA)。
-
主要结果:所有ViCrop方法均能显著提升LLaVA-1.5和InstructBLIP在细节敏感数据集上的准确率,同时不影响在通用数据集上的性能。这表明性能提升并非以牺牲其他能力为代价。
-
有效性示例:如下图所示,ViCrop通过聚焦关键区域,成功帮助模型纠正了错误答案。

-
与外部工具对比:ViCrop方法优于基于CLIP、YOLO、SAM等外部模型的裁剪方法,证明了利用模型内部知识的优越性。
-
计算开销:ViCrop方法带来的推理时间开销很小(GPU上约1-2秒),且不随生成答案的长度而增加,具有实用性。
三、Embedding-based Retrieval in Multimodal Content Moderation
这篇由 TikTok 团队撰写的论文,旨在解决传统分类模型在短视频内容审核中面临的挑战,特别是在应对新兴、快速变化的违规内容趋势时的不足。论文创新性地提出并实践了一套基于嵌入的检索系统,作为分类方法的有效补充,并在真实工业场景中验证了其卓越的性能和效率。
研究背景与核心问题
背景
TikTok、YouTube Shorts 等短视频平台内容量巨大,内容审核对维护平台健康至关重要。目前,分类模型是内容审核的主流技术。
传统分类模型的局限性:
-
响应迟缓: 训练一个有效的分类模型需要大量标注数据,对于突发或新兴的违规趋势,数据收集和模型训练周期长,无法满足“快速响应”的需求。
-
零样本/少样本学习能力差: 对于从未见过的新违规类型,分类模型表现不佳。
-
输出不灵活: 分类模型仅输出类别概率,缺乏细粒度的风险度量,难以应对需要细微差别处理的高风险内容。
-
成本高昂: 每次应对新趋势都需要重新收集数据、训练和部署模型,运营成本高。
核心解决方案:基于嵌入的检索
论文提出的核心思想是:不直接对视频进行“分类”,而是通过计算其与已知违规视频(种子视频)在语义空间中的相似度,来评估其风险等级。相似度越高,风险越大。这套方案的核心优势在于:
-
无需训练: 一旦预训练好一个强大的嵌入模型,对于新提供的趋势,只需提供少量种子视频即可立即启动检索,实现“热修复”。
-
灵活可解释: 审核决策基于与种子视频的相似度,结果更直观,易于理解和调整。
-
强适应性: 可以快速动态更新种子集合,实时适应趋势的变化。
方法详解
1. 嵌入模型训练:监督对比学习
与 CLIP 等自监督对比学习模型不同,采用监督对比学习来训练嵌入模型。其核心区别在于定义“正样本”的方式:
自监督对比学习: 正样本 = 同一视频的不同增强视图。模型学习的是视觉上的不变性。
监督对比学习: 正样本 = 所有具有相同违规标签的视频。模型学习的是语义/风险层面的相似性。
这种方法能更好地区分“视觉相似但违规类别不同”的视频,更贴合内容审核的需求。其具体流程如下:
论文训练了一系列基础模型:
单模态模型: 仅使用视觉信号,基于 Vision Transformer。
多模态模型: 同时处理视觉和文本信号,使用 ViT 作为视觉编码器,BERT 风格模型作为文本编码器,并通过交叉注意力模块进行融合。
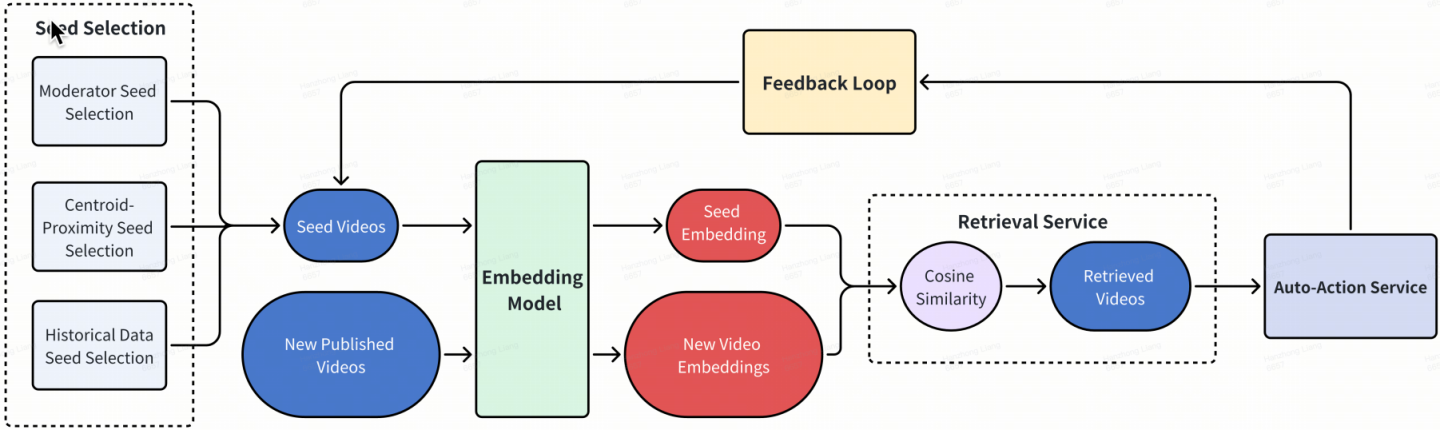
2.EBR 系统设计
如上图所示,整个系统包含五个关键组件,形成一个高效的闭环:
种子选择: 这是系统效力的关键。论文提出了三种策略:
-
质心邻近选择: 使用 DBSCAN 等聚类算法在嵌入空间中找到违规视频的密集区域,从中选取种子。
-
历史数据选择: 根据种子在过去一段时间内的检索精确率,筛选出高精度的可靠种子。
-
审核员选择: 依赖领域专家人工识别和提交高质量的“黄金种子”。
嵌入模型: 为种子视频和待审核视频生成嵌入向量。
检索服务: 计算待审核视频与所有种子视频的余弦相似度,取其最高相似度作为该视频的风险分数。
自动处置服务: 根据预设的相似度阈值,自动触发不同级别的处置动作(如:标记、限制、上报等)。
反馈循环: 实时监控系统表现(如 Top-K 精确率),动态调整种子集合和阈值,实现持续优化。
实验与结果分析
论文通过离线和在线实验全面评估了 EBR 系统。
1. 离线实验
在 25 个多样化的、分类模型未见过的违规趋势上进行测试。比较了多模态分类模型基线、单模态 EBR 和多模态 EBR。
结果:
-
EBR 系统在所有指标上均显著优于分类基线。例如,多模态 EBR 将 ROC-AUC 从 0.85 提升至 0.99,PR-AUC 从 0.35 提升至 0.95,提升巨大。
-
多模态 EBR 优于单模态 EBR,证明了融合文本和视觉信息的重要性。

2. 消融实验
-
监督对比学习的有效性: 在多个任务上,SCL 均显著优于 ResNet50、CLIP 和 MoCo V3 等模型,证明了其学习风险语义表示的优势。
-
种子数量影响: 实验表明,使用 5%-10% 的视频作为种子即可达到很强性能,继续增加种子数量收益递减。这证明了 EBR 在少样本场景下的高效性。

3. 在线实验
-
性能: 在线部署后,EBR 帮助整体处置量提升了 10.32%。在对三个典型趋势的单独评估中,EBR 的召回率超过 95%,而分类模型的召回率不足 3%。
-
成本: EBR 将处理新趋势的周期从平均 5 天缩短到 1 天以内,降低了超过 80% 的运营成本。
四、《Filter-And-Refine: A MLLM Based Cascade System for Industrial-Scale Video Content Moderation》
论文核心研究内容是如何将计算成本高昂的多模态大语言模型(MLLM)有效地应用于工业级的视频内容审核系统中。论文指出,尽管MLLM在复杂场景(如隐含有害内容、上下文模糊性)的理解上优于传统分类模型,但其巨大的计算开销和生成式模型不适于判别式分类任务这两大挑战阻碍了其工业部署。为此,论文提出了一种路由器-排序器(Router-Ranker)级联系统,成功实现了MLLM的大规模生产环境应用。
核心挑战与解决方案
1. MLLM的高计算成本
解决方案: 借鉴推荐系统中的“召回-排序”架构,设计了一个两阶段级联系统。首先用一个轻量级的路由器(Router)快速过滤掉绝大部分低风险内容,只将少量潜在高风险视频传递给后续昂贵的排序器(Ranker)MLLM进行精细判别。
2. 生成式模型用于判别式任务
解决方案: 提出了一种简单有效的方法,将生成式MLLM转换为多模态分类器。该方法通过有监督微调(SFT),并精心设计提示词(Prompt),让模型输出单一令牌(如Yes/No)及其概率,从而适配分类任务。
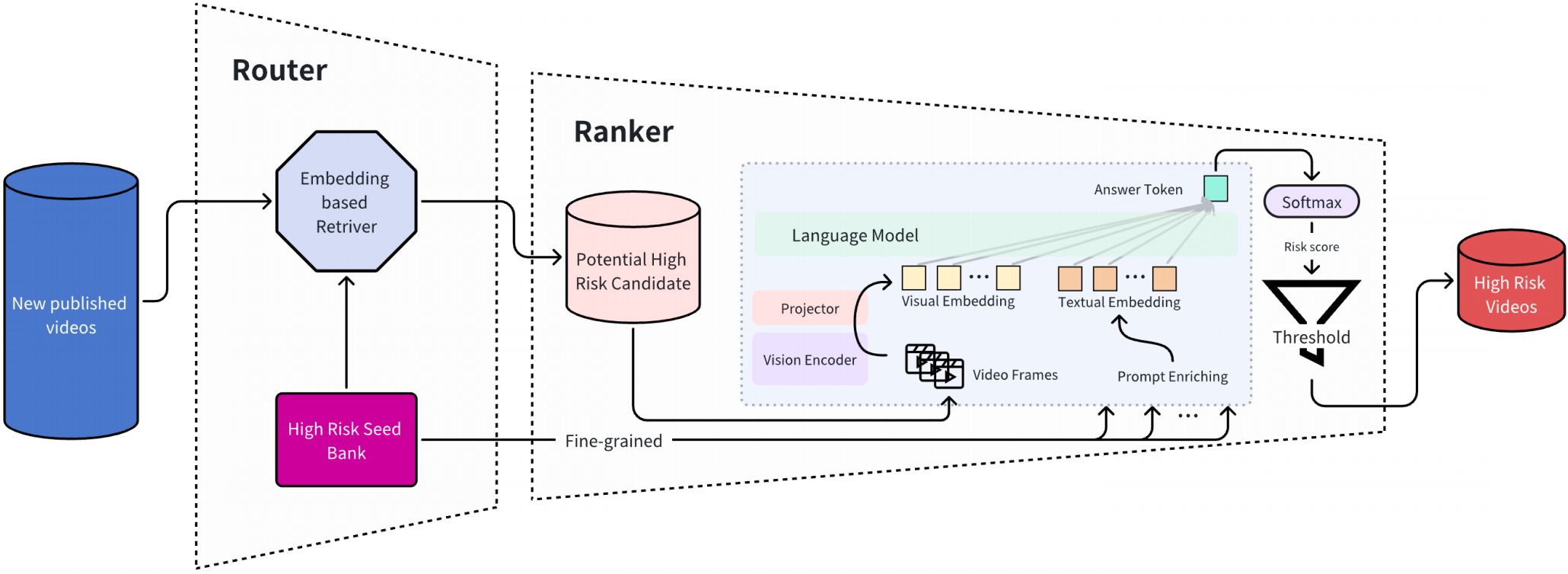
系统设计
1. 路由器(Router)- 召回阶段
目标: 高效、低成本地召回潜在违规视频,追求高召回率。
实现: 论文采用了一种基于嵌入的检索系统,而非需要大量标注数据的分类模型。该系统维护一个由高风险代表性视频构成的种子库(Seed Bank)。新上传的视频会与种子库中的视频进行语义相似度匹配,相似度高的被视为高风险候选。
优势:
-
无监督/弱监督: 无需大量标注数据,种子可通过聚类或人工挑选。
-
灵活高效: 通过更新种子库即可快速适应新的违规内容类型。
-
资源节省: 在线实验表明,路由器过滤掉了97.5%的流量,极大减轻了后端MLLM的压力。
2. 排序器(Ranker)- 排序阶段
目标: 对路由器召回的少量视频进行精准分类,追求高精度。
实现: 使用MLLM(本文采用LLaVA架构,视觉编码器为ViT-Large,语言模型为Mistral-7B)作为排序器。通过输入视频的视觉特征和特定任务的提示词,模型输出一个代表分类标签的令牌(如Y/N)及其置信度。
将MLLM改造为分类器的关键技术
1. 模型微调(Fine-Tuning)
训练数据: 包含三部分,按1:1:1混合:
-
VQA数据集: 来自LLaVA-Mix665k,用于保持模型的通用视觉问答能力。
-
视频描述数据集: 高质量的视频摘要,对于违规视频会突出其违规点。
-
分类数据集: 与线上分布一致的内容审核标注数据,是模型获得审核能力的关键。
训练策略: 对比了两种策略:
-
多任务学习: 将三类数据直接混合训练。效果最好,但耗时较长。
-
混合序贯学习: 先在第一阶段用VQA和描述数据训练,第二阶段再用分类数据微调。效果接近多任务学习,但更高效灵活。
2. 输出转换(Output Transformation)
为了将MLLM的生成式输出转换为可用于线上服务的概率分数,论文采用了Softmax函数对目标令牌(如“Y”和“N”)的logits值进行归一化,得到两个类别的概率。这使得MLLM可以像传统分类器一样设置阈值进行操作。
3. 提示词工程(Prompt Engineering)
论文设计了四种不同的提示模板,主要区别在于如何询问视频的细粒度违规标签和整体处置标签(是否需要采取行动)。
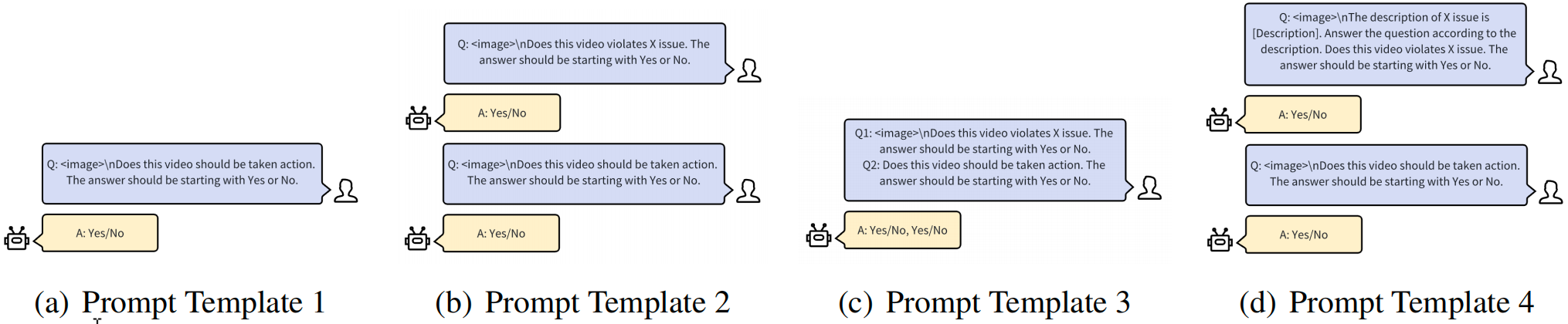
实验发现: 将两个问题分开询问的模板(P2)效果最佳。单独问一个问题(P1, P3)或在一个提示中组合过多信息(P4)会引入噪声,降低性能。
实验结果与分析
1. 离线实验(Offline Evaluation)
主要结论:
-
MLLM优势: 经过微调的MLLM在F1分数上比传统多模态分类模型提升了66.50%,证明了其在复杂内容审核任务上的卓越能力。
-
微调有效性: 微调后的MLLM在PR-AUC上比零样本(Zero-Shot)MLLM提升了45.55%,证明微调流程的必要性。
-
数据效率: 仅使用了传统模型所需2%的标注数据就取得了显著更好的效果。
2. 消融实验(Ablation Study)
-
标签融合(Label Assembling): 当使用多个提示词时,需要将细粒度标签和整体标签的预测结果融合。实验发现,“加权求和”法在PR-AUC上表现最好。
-
温度调节(Temperature Tuning): 实验表明,温度参数对最终性能影响不大。
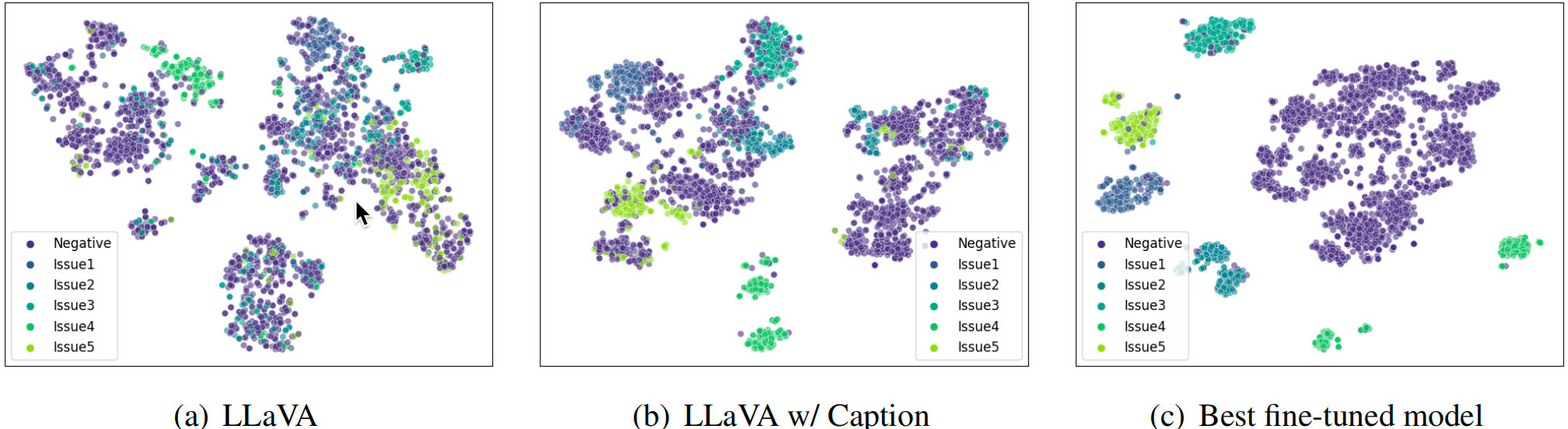
3. 可视化分析
-
通过可视化模型最后隐藏层的嵌入,可以直观地看到最佳模型能够学习到更清晰的决策边界
4. 线上实验
-
审核效能提升: A/B测试显示,该系统使自动内容审核的处置量平均提升了41.27%,同时系统整体精确度提升了19.16%。
-
资源节省: 级联设计使得MLLM只需处理总流量的2.5%,计算成本仅为直接全量部署的1.5%,实现了高效率、低成本的工业级部署。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









