



MinerU概述
MinerU是上海AILab开发的PDF处理工具,可以将PDF(部分PDF加密,模糊,使得PDF处理起来很麻烦)转换为markdown,进而方便进一步处理(比如复制粘贴,喂给AI 大模型或者编程进一步处理等等)。
官网:https://mineru.net/https://mineru.net/
github:https://github.com/opendatalab/MinerU
特点与技术原理
支持多语言(中文、英文、日文等)PDF文档的解析,可以同时将PDF中的文字,表格,数学公式,图片等信息都提取出来,并转换为markdown相对应的格式。也可以上传图片类型的pdf文档进行识别。
其技术原理本质是将PDF解析拆分为以下几步,并使用不同的模型识别对应内容:
布局检测:使用 LayoutLM v3 模型进行区域检测,如图像,表格,标题,文本等;
公式检测:使用 YOLO v8 进行公式检测,包含行内公式和行间公式;
公式识别:使用 UniMERNet 进行公式识别;
表格识别:使用 StructEqTable 进行表格识别;
光学字符识别:使用 PaddleOCR 进行文本识别;
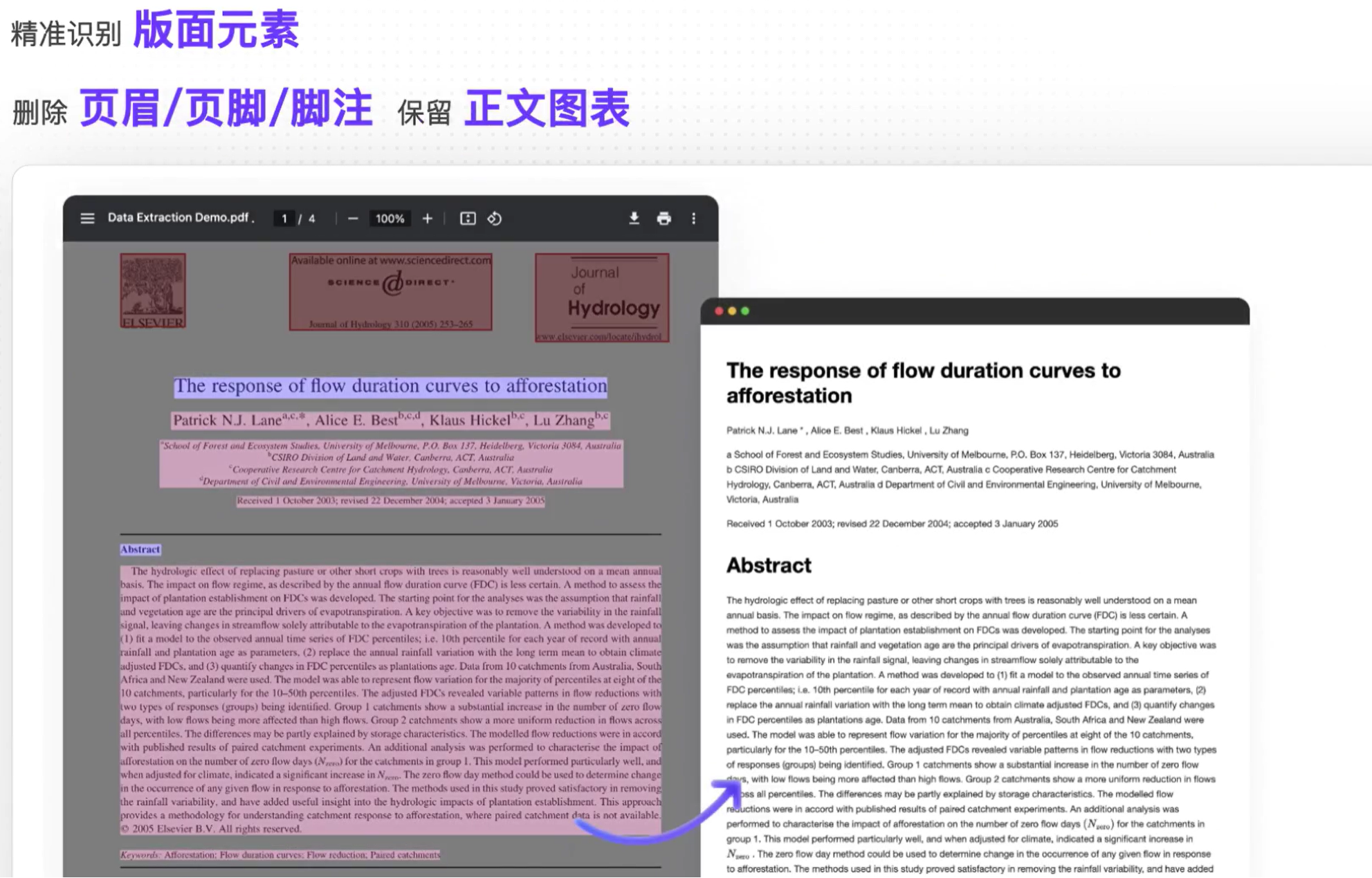
图片也可以原文原位置转换,公式也可以较精确的转换pdf公式为Latex格式公式:
API
MinerU的API提供了丰富的接口以及相应的调用示例,如下图:
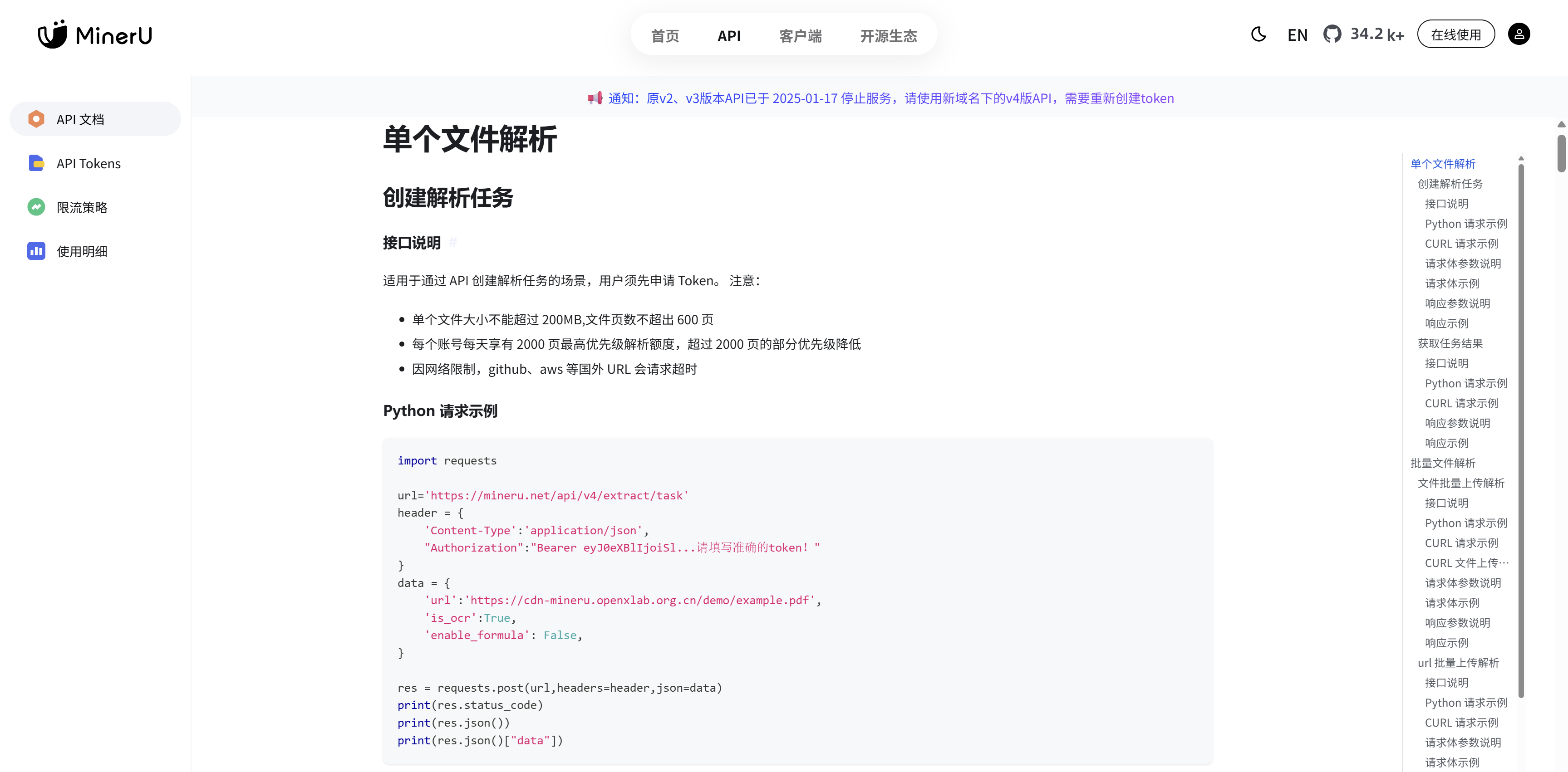
具体详细的调用方式以及参数详见官网:
MinerUMineru 智能数据提取![]() https://mineru.net/apiManage/docs
https://mineru.net/apiManage/docs
当前 MinerU API 处于内测运行阶段,为确保稳定服务体验,对用户执行以下限流策略:
- 上传限制:单个文件大小不超过 200 MB,单个上传文件页数不超过 600 页
- 解析页数限制:每个账号每天不限解析页数,但需要遵守我们的优先级策略。每个用户享有2000页最高优先级解析额度,超过2000页的部分优先级降低(自然日内统计)

由于MinerU官方给出的批量调用API示例不能匹配大规模调用(1000+)的使用场景,而且每次有限制最多一批上传200个pdf文件,这对于测试OCR benchmark带来不便,因此我在这里开源了我写的批量检测代码,每次调用只需要改动批次号i,因为目前API不支持连续多批次调用(当然也可以写脚本加时间间隔)。
import requests
import os
from glob import glob
# 配置参数
pdf_dir="/pdf" #输入你的pdf路径
max_files_per_batch = 200 # 每批最多200个文件 这是官网限制
# 获取所有PDF文件
pdf_files = glob(os.path.join(pdf_dir, "*.pdf"))
if not pdf_files:
print(f"No PDF files found in {pdf_dir}")
exit()
# API配置
url = 'https://mineru.net/api/v4/file-urls/batch'
header = {
'Content-Type': 'application/json',
"Authorization": "Bearer xxx" #输入你的API-key
}
#
i=0
print(i)
batch_idx = max_files_per_batch * i # 第二批次的起始索引(200)
batch_files = pdf_files[batch_idx : batch_idx + max_files_per_batch]
if not batch_files:
print("第二批没有文件可处理")
exit()
# 构建文件数据
files_data = [{
"name": os.path.basename(pdf),
"is_ocr": True,
"data_id": f"{os.path.splitext(os.path.basename(pdf))[0]}_b2",
"language": "ch", # 批次号固定为2
} for pdf in batch_files]
# print(f"\n正在处理第"+i+"批次(共 {len(batch_files)} 个文件)")
try:
# 获取上传URL
response = requests.post(url, headers=header, json={
"enable_formula": True,
"language": "en",
"layout_model": "doclayout_yolo",
"enable_table": True,
"files": files_data
})
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
exit()
result = response.json()
if result["code"] != 0:
print(f'申请失败,原因:{result.get("msg", "未知错误")}')
exit()
# 上传文件
batch_id = result["data"]["batch_id"]
urls = result["data"]["file_urls"]
success_count = 0
for idx, (url, pdf_path) in enumerate(zip(urls, batch_files)):
with open(pdf_path, 'rb') as f:
res = requests.put(url, data=f)
if res.status_code in [200, 201]:
success_count += 1
else:
print(f"失败文件:{os.path.basename(pdf_path)},状态码:{res.status_code}")
print(f"第二批次完成 | 成功:{success_count}/{len(batch_files)} | 批次ID:{batch_id}")
#这个批次id一会会用到
except Exception as e:
print(f"发生异常:{str(e)}")由于MinerU在上传解析后仍然需要下载解析后pdf的压缩包,而手动下载非常麻烦,故我写了一个python代码自动获取某一批次id(如上面代码注释)的pdf解析结果md文件
import requests
import zipfile
import os
import shutil
from urllib.parse import urlparse
output_dir = "/result" # 指定输出目录
os.makedirs(output_dir, exist_ok=True) # 自动创建目录
idx='xxx-xxx-xxx' #之前代码的批次id
# 原始API请求
url = 'https://mineru.net/api/v4/extract-results/batch/'+idx
headers = {
'Content-Type': 'application/json',
"Authorization": "Bearer xxx" #你的api-key
}
response = requests.get(url, headers=headers)
batch_data = response.json()["data"]
# 正确访问数据路径
data_list = batch_data['extract_result'] # 从extract_result获取数据
for item in data_list:
if item.get('state') == 'done' and 'full_zip_url' in item:
zip_url = item['full_zip_url']
original_name = item['file_name']
# 生成最终路径
base_name = os.path.splitext(original_name)[0]
final_filename = f"{base_name}.md"
output_path = os.path.join(output_dir, final_filename)
try:
# 创建临时目录
temp_dir = os.path.join(output_dir, f"temp_{item['data_id']}")
os.makedirs(temp_dir, exist_ok=True)
# 下载ZIP文件
zip_response = requests.get(zip_url, stream=True)
zip_response.raise_for_status()
# 保存临时ZIP
zip_name = os.path.basename(urlparse(zip_url).path)
zip_path = os.path.join(temp_dir, zip_name)
with open(zip_path, 'wb') as f:
for chunk in zip_response.iter_content(1024 * 1024): # 1MB chunks
f.write(chunk)
# 解压并处理文件
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
# 搜索full.md文件
target_file = None
for file_info in zip_ref.infolist():
if os.path.basename(file_info.filename) == 'full.md':
target_file = file_info
break
if target_file:
# 解压到临时目录
zip_ref.extract(target_file, temp_dir)
# 构建完整路径
extracted_path = os.path.join(temp_dir, target_file.filename)
# 移动并重命名
shutil.move(extracted_path, output_path)
print(f"成功处理:{original_name} -> {output_path}")
else:
print(f"警告:{zip_name} 中未找到full.md文件")
except requests.exceptions.RequestException as e:
print(f"下载失败:{original_name} | 错误:{str(e)}")
except zipfile.BadZipFile:
print(f"损坏的ZIP文件:{original_name}")
except Exception as e:
print(f"处理异常:{original_name} | 错误类型:{type(e).__name__} | 详情:{str(e)}")
finally:
# 清理临时文件
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
这样我们就可以愉快的转化pdf了(:

















 1865
1865






 到【灌水乐园】发言
到【灌水乐园】发言







