




Transformer 是 ChatGPT 等大语言模型的核心技术之一,而注意力机制是其的关键部分。但是,标准的注意力实现具有二次时间和内存复杂度,使其在长序列任务上变慢并消耗大量显存。这限制了 Transformer 能够建模的上下文长度,同时使得大尺度模型的训练和推理时间延长。
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness [1] 提出了一种称为 Flash Attention 的新注意力算法,该算法减少了注意力机制所需的内存访问次数。这使得注意力运算更快速且内存高效,同时仍保持数值精确性。
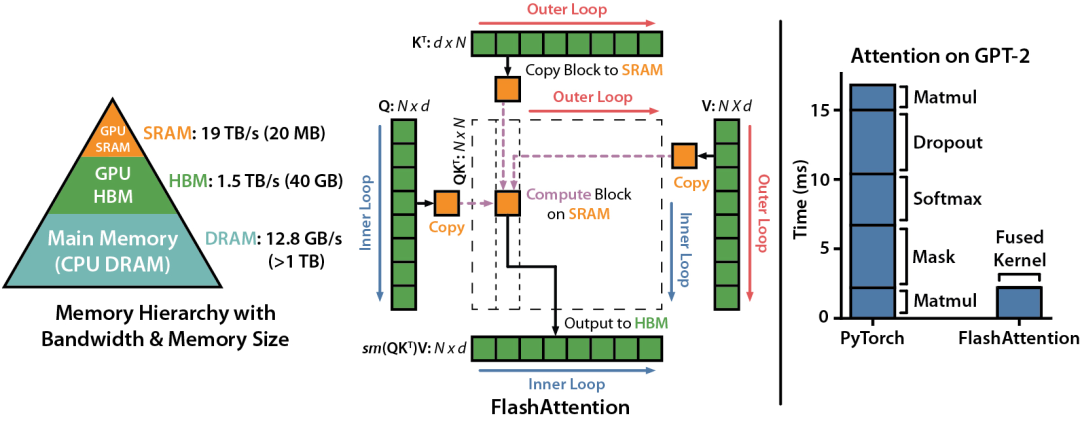
图|FlashAttention 的运行机制 [1]
Flash Attention 运用了两种主要技术:
- 分块 - 它将输入划分成块,并单独处理每个块的注意力。
- 重计算 - 它只存储足够的信息,以便在反向传播期间重新计算注意力矩阵,而不是存储整个矩阵。这减少了内存使用。
与标准注意力相比,Flash Attention 通过减少内存访问次数从而提高训练速度并降低显存占用量。相比于基准,Flash Attention在GPT-2和BERT等 Transformer 模型上的训练速度提升可达 3 倍以上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











