







 本文详细介绍了Spark中的mapPartitions、groupByKey、reduceByKey以及coalesce操作,强调了Shuffle在数据处理中的重要性和广播变量在减少网络和内存开销方面的优势。通过优化数据处理粒度,可以显著提高大数据作业的执行性能。
本文详细介绍了Spark中的mapPartitions、groupByKey、reduceByKey以及coalesce操作,强调了Shuffle在数据处理中的重要性和广播变量在减少网络和内存开销方面的优势。通过优化数据处理粒度,可以显著提高大数据作业的执行性能。

💐💐扫码关注公众号,回复 spark 关键字下载geekbang 原价 90 元 零基础入门 Spark 学习资料💐💐
mapPartitions:以数据分区为粒度的数据转换
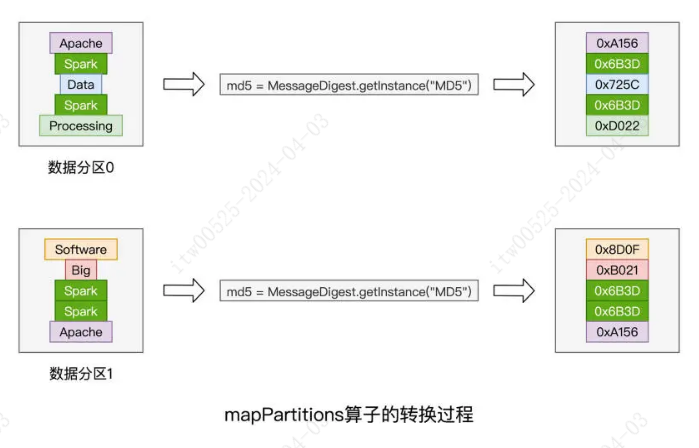
mapPartitions 以数据分区(匿名函数的形参 partition)为粒度,对 RDD 进行数据转换。具体的数据处理逻辑,则由代表数据分区的形参 partition 进一步调用 map(f) 来完成。以数据分区为单位,实例化对象的操作只需要执行一次,而同一个数据分区中所有的数据记录,都可以共享该对象。对于数据记录来说,凡是可以共享的操作,都可以用 mapPartitions 算子进行优化。这样的共享操作还有很多,比如创建用于连接远端数据库的 Connections 对象,或是用于连接 Amazon S3 的文件系统句柄,再比如用于在线推理的机器学习模型,等等,不一而足。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3961
3961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











