







鸣谢:如果您觉得本文对您有帮助,请点赞和收藏,Thanks。
以图解的模式。细说Spark算子。
前提条件:
//启动配置:设置2个worker运行Spark
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("Test")
//创建SparkSession,并启用hive
val ss: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
//获取SparkContext
val sc: SparkContext = ss.sparkContext
value类型算子
map(func)
作用: 一对一算子,每一个输入元素经过func函数处理后一对一输出
例子: RDD数据为[1,2,3,4,5],经过map(_*2)后,每个分区的数据会被逐条拿出来乘于2,然后输出为新的RDD
计算规则: 有n条数据,func就会被调用n次
val source: RDD[Int] = sc.makeRDD(1 to 5)
source.map(x => x * 2)
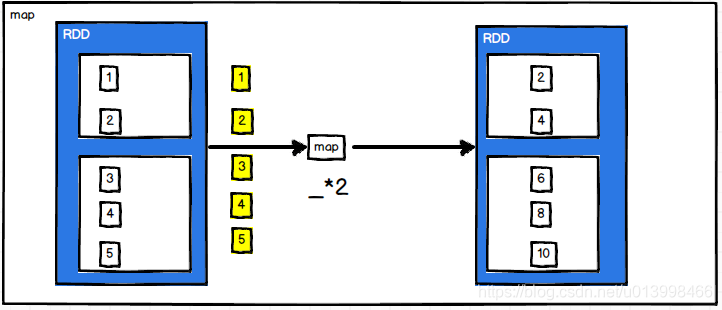
mapPartitions(func)
作用: 类似于Map函数,不同的是,此函数会一次性处理一个分区中的所有数据,效率比Map高。但是,如果一个分区的数据量过大,容易导致OOM,用这个函数是需要考虑数据量大小,如果太大,需要重分区。
例子: RDD数据为[1,2,3,4,5],经过mapPartitions(_.map(_*2))后,两个分区的数据会被一次性拿出来乘于2,然后输出为新的RDD
计算规则: 有n个分区,有m条数据,mapPartitions就会被调用n次,map会被调用m次
备注: 通常输出数据到数据库,如mysql/redis时,可以用mapPartitions,在里面创建数据库连接,如此可以一个分区使用一个数据库连接,既不会浪费资源也优化了写数据库的速度。详情可以参考Spark任务划分、代码执行位置、创建Connect连接的最佳实践
val source: RDD[Int] = sc.makeRDD(1 to 5)
source.mapPartitions(source.mapPartitions(_.map(_*2)))
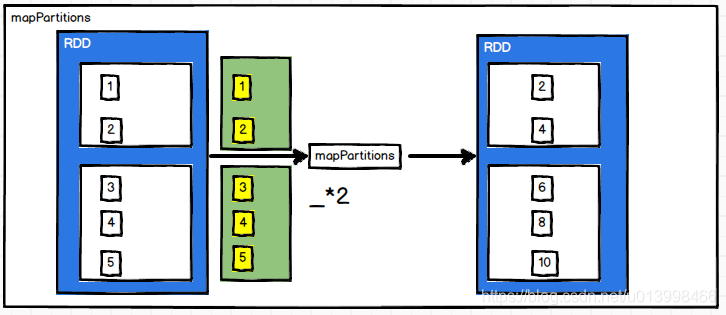
mapPartitionsWithIndex(func)
作用: 类似于mapPartitions,但func带有一个整数参数表示分区的索引值
例子: RDD数据为[1,2,3,4,5],经过`mapPartitionsWithIndex后,每个数据跟所在的分区行成一个元组,然后输出为新的RDD
计算规则: 有n个分区,有m条数据,mapPartitions就会被调用n次,map会被调用m次
val source: RDD[Int] = sc.makeRDD(1 to 5)
source.mapPartitionsWithIndex((index, datas) => {
(datas.map(((index, _))))
})
//如果有2个分区,那么输出结果为:
// (0,1)
// (0,2)
// (1,3)
// (1,4)
// (1,5)
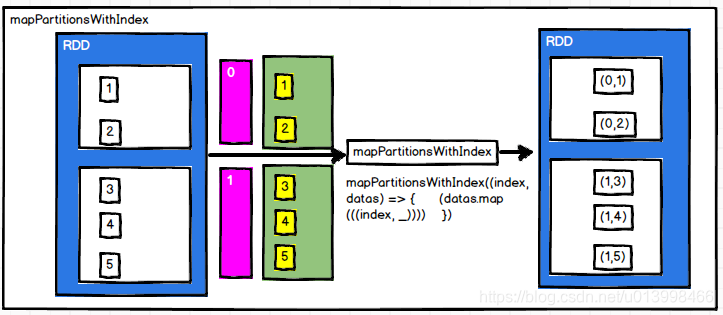
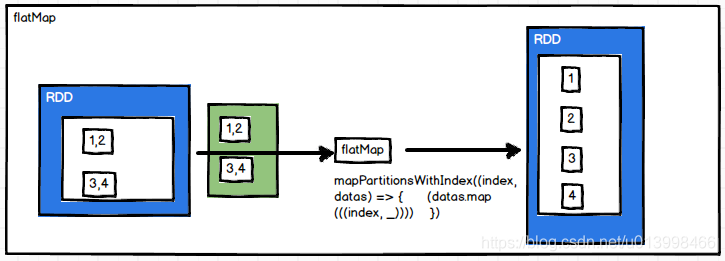
flatMap(func)
作用: 类似于map,但是每一个输入元素可以被映射为0个或多个输出元素
例子: RDD数据为Array(List(1, 2), List(2, 3)),经过flatMap后,转换成一个list,本来2个数据,,转换后有4个数据。
val source: RDD[List[Int]] = sc.makeRDD(Array(List(1, 2), List(2, 3)))
val ListRdd: RDD[Int] = source.flatMap(datas => datas)
ListRdd.collect().foreach(print(_))
//输出 1223
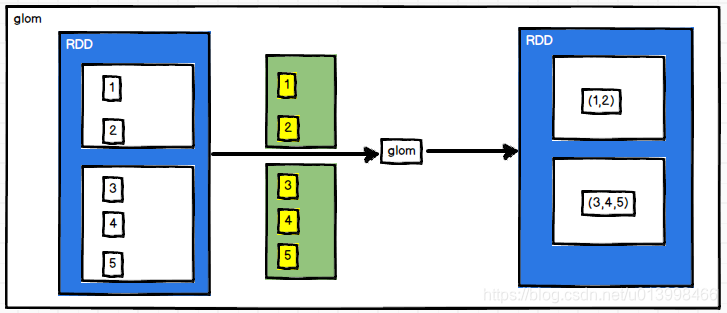
glom(func)
作用: 将每一个分区的数据形成一个数组,形成RDD[Array[T]]
例子: 生成包含两个分区的RDD[1,2,3,4,5],经过glom后,输出包含两个数组的RDD
val source: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
val array: RDD[Array[Int]] = source.glom()
array.collect().foreach(array => {
println(array.mkString(","))
})
//输出结果
//1,2
//3,4,5
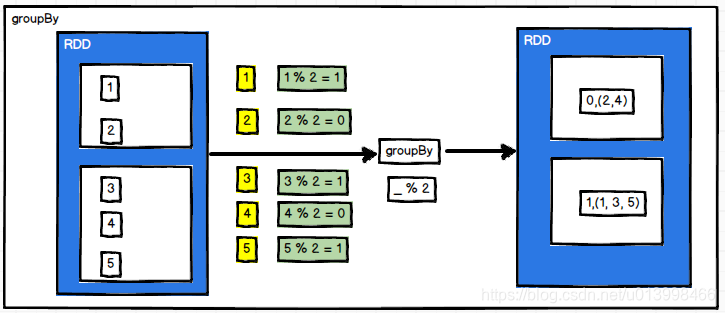
groupBy(func)
作用: 分组,按照传入函数的返回值进行分组。将相同key对应的值放入一个迭代器。
例子: RDD数据为[1,2,3,4,5],经过groupBy后,返回RDD[(Int, Iterable[Int])],RDD中的Int类型参数是func的计算结果(相当于数据的key),Iterable[Int]类型参数是根据func计算结果分组得到的迭代器。
val source: RDD[Int] = sc.makeRDD(1 to 5)
val value: RDD[(Int, Iterable[Int])] = source.groupBy(_ % 2)
value.collect().foreach(println(_))
//输出结果
//(0,CompactBuffer(2, 4))
//(1,CompactBuffer(1, 3, 5))
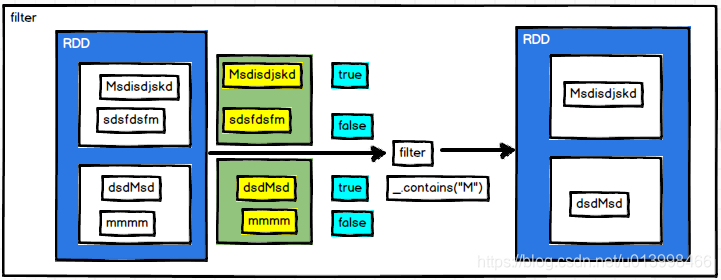
filter(func)
**作用:**过滤。帅选出符合条件的数据。
例子: RDD数据为(“Msdisdjskd”, “dsdMsd”, “sdsfdsfm”, “mmmm”),经过filter后,筛选出包含M的结果。
val source: RDD[String] = sc.makeRDD(List("Msdisdjskd", "dsdMsd", "sdsfdsfm", "mmmm"))
val result: RDD[String] = source.filter(_.contains("M"))
result.collect().foreach(println(_))
//输出结果
//Msdisdjskd,dsdMsd
sample(withReplacement, fraction, seed)
作用: 采样,从数据集中按照泊松分布或者伯努利分布算法抽样数据。
参数:
withReplacement : Boolean , True表示进行放回采样,False表示进行不放回采样
fraction : Double, 在0~1之间的一个浮点值,表示要采样的记录在全体记录中的比例(或者打分值)。如果withReplacement 为true,fraction 要大于等于0,当withReplacement 为false时,fraction 要在0-1之间。
seed :随机种子,可用默认值,如果指定某个数字,那么每次抽样的结果都是一样的
例子: RDD数据为[1,2,3,4,5,6,7,8,9,10],经过sample后,抽出1,4,5,8
val source: RDD[Int] = sc.makeRDD(1 to 10)
val value: RDD[Int] = source.sample(withReplacement = false, 0.3)
value.collect().foreach(println(_))
//输出结果
//1,4,5,8
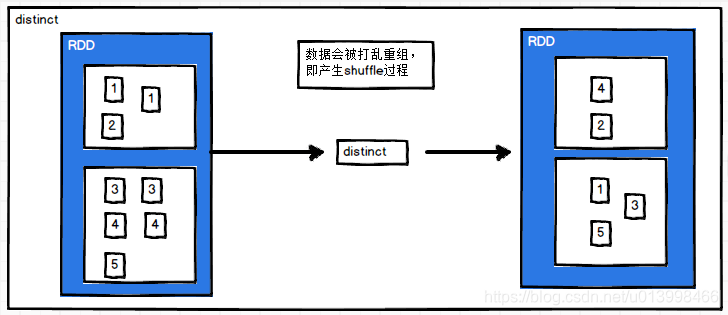
distinct(numPartitions)
作用: 去重。把数据去重后返回,会产生shuffle过程,数据会被打乱输出到不同的分区中。
备注:通常,去重后数据量会减少,可以传入分区数,指定结果分区,避免分区数据为空的情况。
例子: RDD数据为[1, 2, 1, 3, 4, 3, 5],经过distinct(_*2)后,返回4, 2, 1, 3, 5
val source: RDD[Int] = sc.makeRDD(List(1, 2, 1, 3, 4, 3, 5))
val value: RDD[Int] = source.distinct()
value.collect().foreach(println(_))
//输出结果
//4, 2, 1, 3, 5
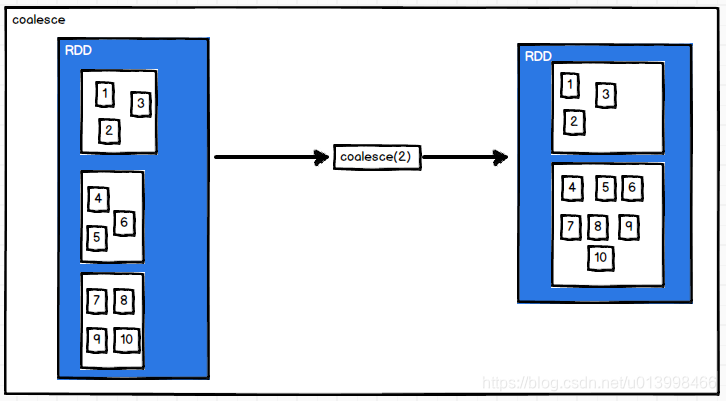
coalesce(numPartitions)
作用: 合并分区。
例子: RDD数据为[1,2,3,4,5,6,7,8,9,10],共3个分区,经过coalesce后,合并为2个分区的RDD
val source: RDD[Int] = sc.makeRDD(1 to 10, 3)
source.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果
//1,2,3
//4,5,6
//7,8,9,10
println("----------------------------------------------")
val value: RDD[Int] = source.coalesce(2)
value.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果
//1,2,3
//4,5,6,7,8,9,10
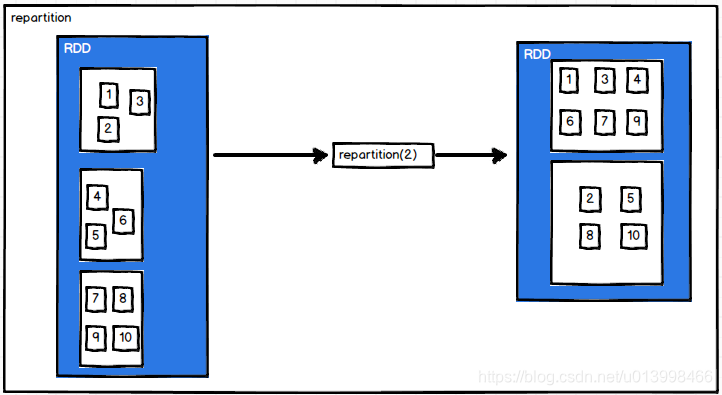
repartition(numPartitions)
作用: 重新分区。会产生shuffle过程,打乱分区数据。
例子: RDD数据为[1,2,3,4,5,6,7,8,9,10],共3个分区,经过repartition后,合并为2个分区的RDD,并且分区数据被打乱
例子: 其本质是调用coalesce,不过shuffle参数为 true
//repartition源码
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
//repartition使用案例
val source: RDD[Int] = sc.makeRDD(1 to 10, 3)
source.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果
//1,2,3
//4,5,6
//7,8,9,10
println("----------------------------------------------")
val value: RDD[Int] = source.repartition(2)
value.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果
//1,3,4,6,7,9
//2,5,8,10
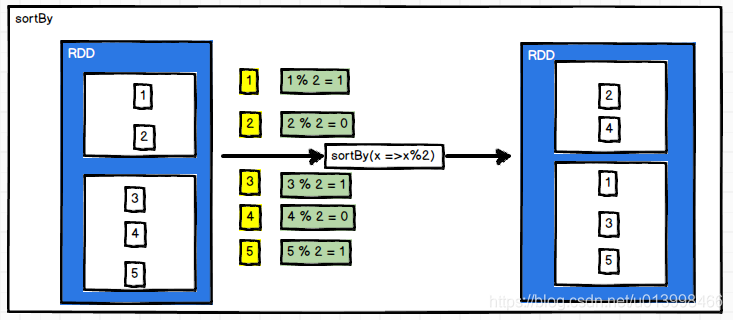
sortBy(func,[ascending], [numTasks])
作用: 排序。按照func处理的结果进行排序,默认是升序;可选参数:ascending为false则为降序,numTasks为排序的并行度
例子1: RDD数据为[3, 5, 7, 4, 9, 0, 1],经过sortBy后,按照升序输出
例子2: RDD数据为[1,2,3,4,5],经过sortBy后,按照与2余的结果进行排序输出
//案例一:直接对原始数据进行排序
val source: RDD[Int] = sc.makeRDD(List(3, 5, 7, 4, 9, 0, 1))
val value: RDD[Int] = source.sortBy(source => source)
value.collect().foreach(print(_))
//输出结果
//0134579
println("----------------------------------------------")
//案例二:对func处理后的结果进行排序,这里是按照与2余的结果进行排序
val source2: RDD[Int] = sc.makeRDD(1 to 5)
val value2: RDD[Int] = source2.sortBy(source => source % 2)
value2.collect().foreach(print(_))
//输出结果
//24135
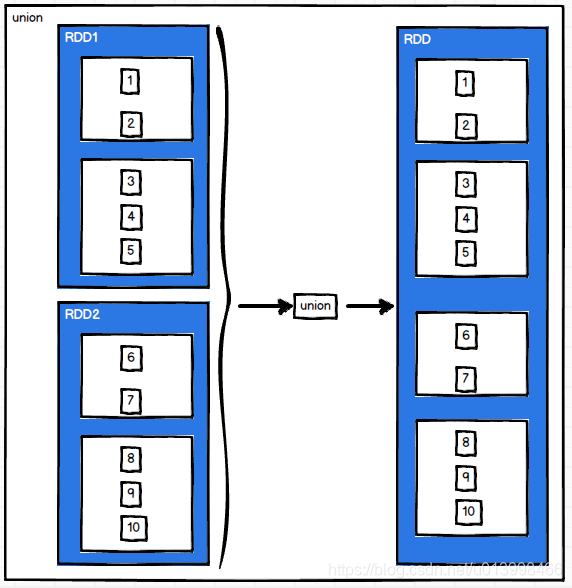
双value类型交互
union(otherDataset)
作用: 取并集。把两个RDD合并为一个RDD。
subtract (otherDataset)
作用: 取差集。RDD1.subtract (RDD2),在RDD1中去掉RDD2中包含的元素。
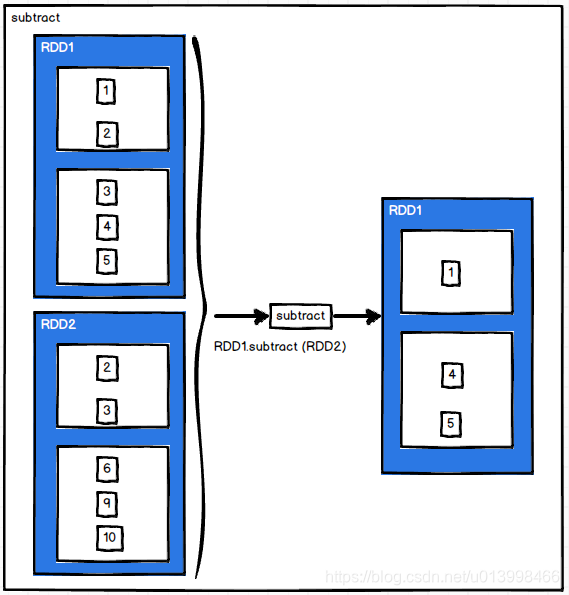
intersection(otherDataset)
作用: 取交集。RDD1.intersection(RDD2),取出RDD1和RDD2中相同的元素。
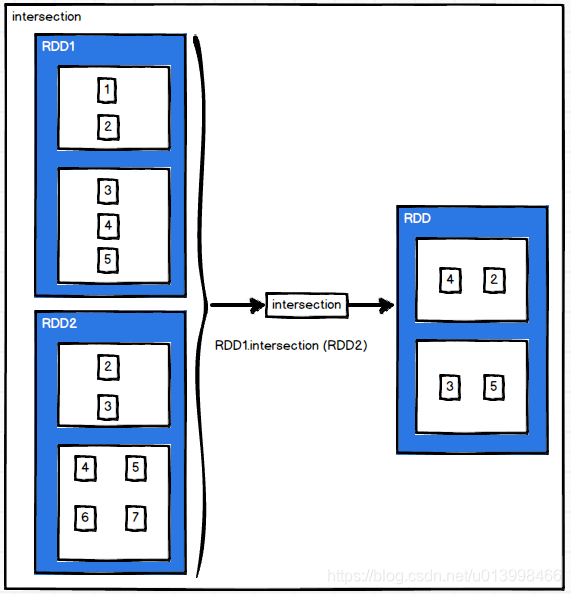
zip(otherDataset)
作用: 将两个RDD组合成(Key,Value)形式的RDD,要求两个RDD的分区数和元素个数都相同,否则会抛出异常。
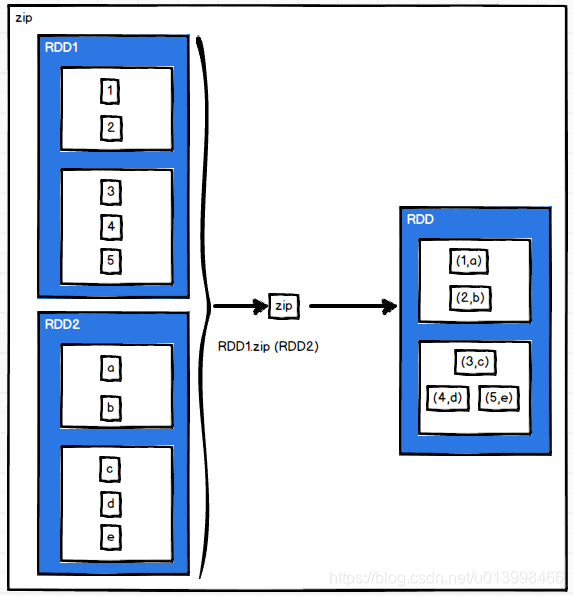
Key-Value类型
partitionBy(partitioner: Partitioner)
作用: 对pairRDD进行分区操作。根据分区器partitioner的逻辑对数据进行分。
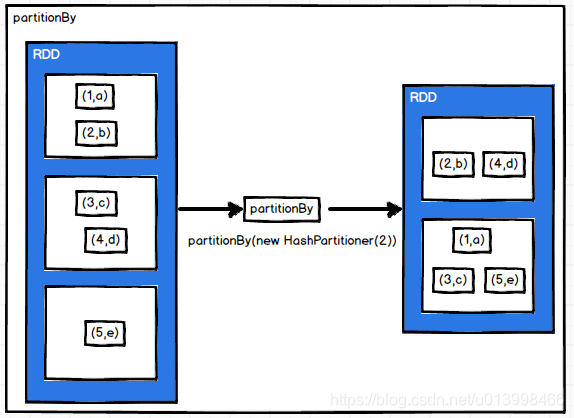
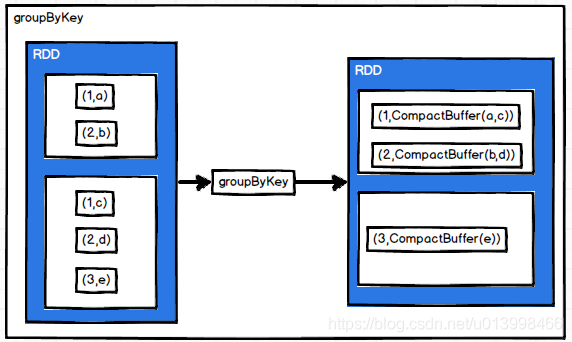
groupByKey
作用: 根据key分组,把key相同的value放到一个迭代器中。
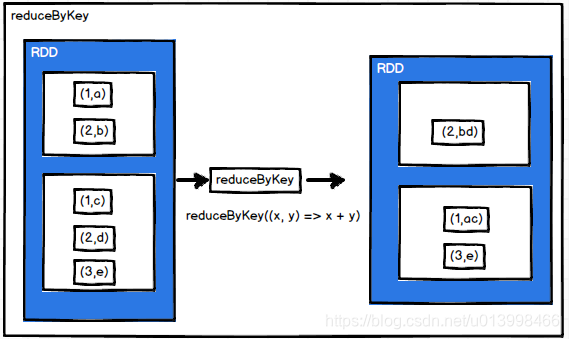
reduceByKey
作用: 根据key对value做聚合操作。在shuffle之前有combine(预聚合)操作,相对groupByKey来说性能更高。
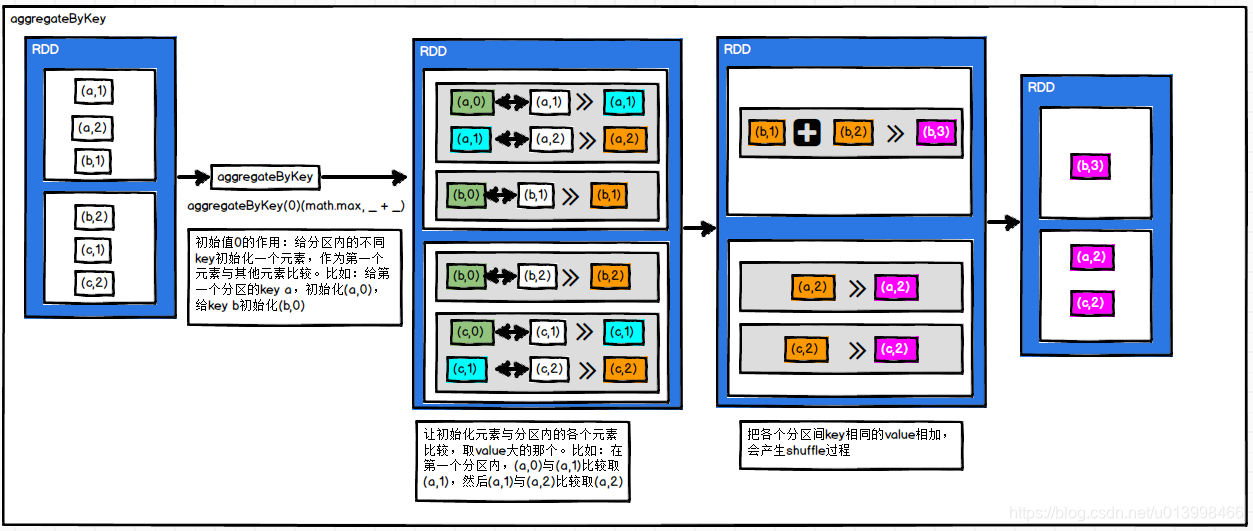
aggregateByKey(zeroValue)(seqOp,combOp)
作用: 根据key对value做聚合操作。
先在分区内聚合,再根据分区内聚合结果在分区间聚合。
第一个参数zeroValue表示在分区内计算时的初始值(零值);
第二个参数的seqOp表示分区内计算规则;
第二个参数的combOp表示分区间计算规则。
源码:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)
}
举例: 取出每个分区相同key对应value的最大值,然后相加。
val source: RDD[(String, Int)] = sc.makeRDD(Array(("a", 1), ("a", 2), ("b", 1), ("b", 2), ("c", 1), ("c", 2)), 2)
source.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(a,1),(a,2),(b,1)
//(b,2),(c,1),(c,2)
println("------------------------")
val value: RDD[(String, Int)] = source.aggregateByKey(0)(math.max(_, _), _ + _)
value.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(b,3)
//(a,2),(c,2)
foldByKey(zeroValue)(func)
作用: 根据key对value做聚合操作。
可以把foldByKey理解为特别的aggregateByKey,同样,先在分区内聚合,再根据分区内聚合结果在分区间聚合。与aggregateByKey不同的是,foldByKey用在分区内计算的方法跟用来分区间计算的方法是一样的,故此只需一个计算参数。
第一个参数zeroValue表示在分区内计算时的初始值(零值);
第二个参数func表示分区内和分区间的计算规则。
源码:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] = self.withScope {
foldByKey(zeroValue, defaultPartitioner(self))(func)
}
举例: 把key相同的value进行相加。
val source: RDD[(String, Int)] = sc.makeRDD(Array(("a", 1), ("a", 2), ("b", 1), ("b", 2), ("c", 1), ("c", 2)), 2)
source.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(a,1),(a,2),(b,1)
//(b,2),(c,1),(c,2)
println("------------------------")
//用foldByKey实现
val value1: RDD[(String, Int)] = source.foldByKey(0)(_ + _)
value1.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(b,3)
//(a,2),(c,2)
println("------------------------")
//用aggregateByKey实现
val value2: RDD[(String, Int)] = source.aggregateByKey(0)(_ + _, _ + _)
value2.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(b,3)
//(a,2),(c,2)
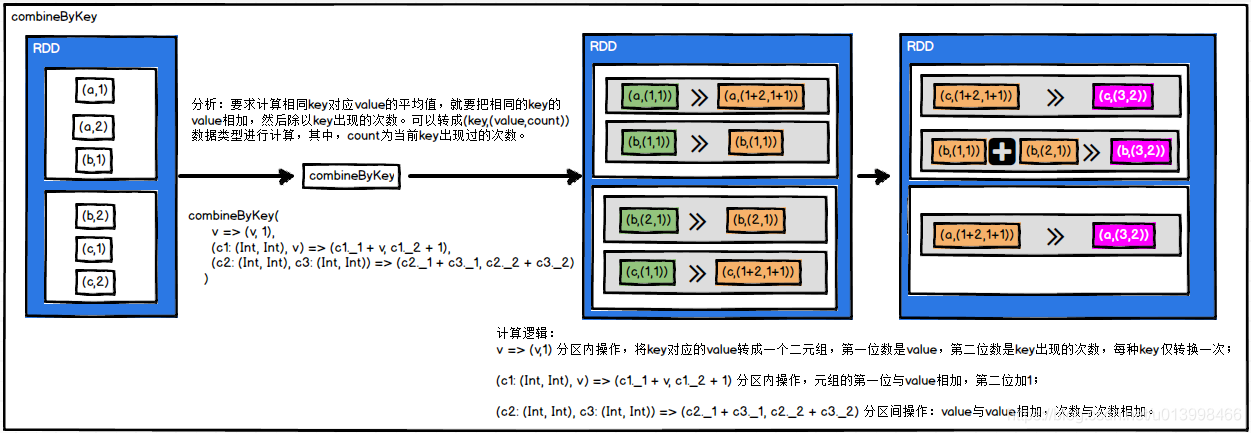
combineByKey(createCombiner,mergeValue,mergeCombiners)
作用: 根据key对value做聚合操作。
第一个参数createCombiner表示在分区内把当前的value做类型转换( V => C);
第二个参数mergeValue表示在分区内的计算规则,同样具有类型转换操作((C, V) => C);
第二个参数mergeValue表示在分区间的计算规则,同样具有类型转换操作((C, C) => C)。
源码:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)
}
举例: 计算相同key对应value的平均值。
val source: RDD[(String, Int)] = sc.makeRDD(Array(("a", 1), ("a", 2), ("b", 1), ("b", 2), ("c", 1), ("c", 2)), 2)
source.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(a,1),(a,2),(b,1)
//(b,2),(c,1),(c,2)
println("------------------------")
//聚合数据
val value: RDD[(String, (Int, Int))] = source.combineByKey(
v => (v, 1),
(c1: (Int, Int), v) => (c1._1 + v, c1._2 + 1),
(c2: (Int, Int), c3: (Int, Int)) => (c2._1 + c3._1, c2._2 + c3._2)
)
value.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(b,(3,2))
//(a,(3,2)),(c,(3,2))
println("------------------------")
//计算平均值
val result: RDD[(String, Double)] = value.map(x => (x._1, x._2._1 / x._2._2.toDouble))
result.glom().collect().foreach(array => {
println(array.mkString(","))
})
//输出结果:
//(b,1.5)
//(a,1.5),(c,1.5)
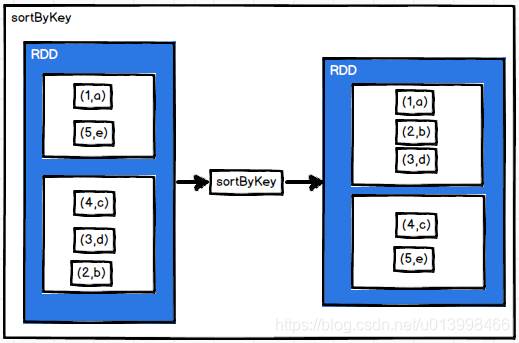
sortByKey(ascending)
作用: 根据key排序。默认升序,ascending设置为false为降序。
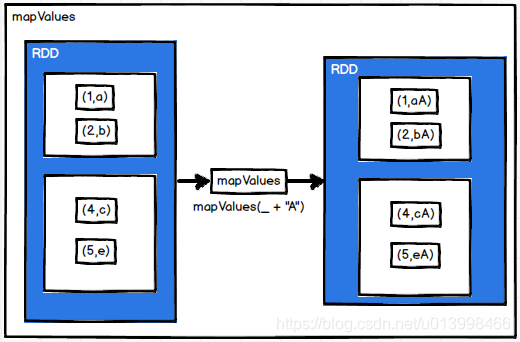
mapValues
作用: 只对(key,value)的value做操作。
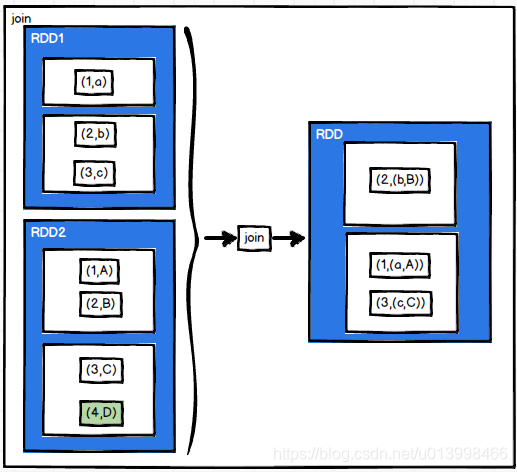
join(otherDataset, [numTasks])
作用: 根据两个RDD的key进行inner join 操作,(K,V)和(K,W) join出来的结果是(K,(V,W))。
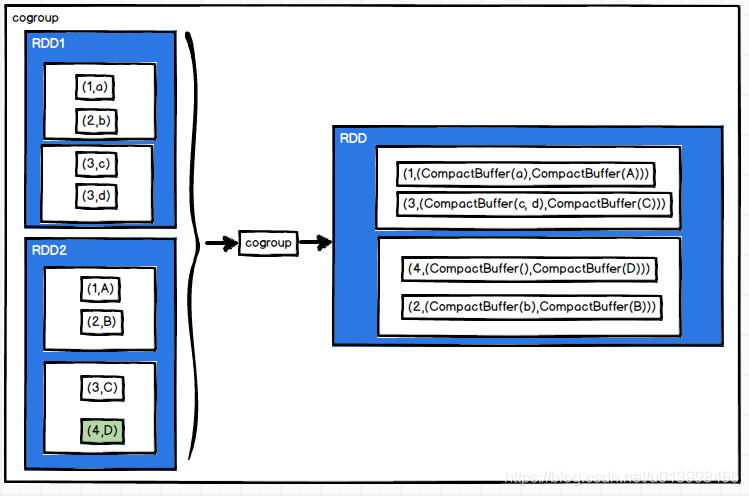
cogroup(otherDataset, [numTasks])
作用: 根据两个RDD的key进行inner join 操作,(K,V)和(K,W)调用cogroup结果是(K,(Iterable,Iterable))。

















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









