







 本文通过源码分析、对比测试,详细解释了Spark开发中map和mapPartitions两个算子的区别。map算子对每个元素操作,而mapPartitions对每个分区操作,适用于处理大数据时减少数据库连接创建。在数据量较小且无数据库连接的场景下,map效率更高;但在涉及数据库操作时,mapPartitions因减少连接创建而更优,但需注意可能的内存溢出问题。
本文通过源码分析、对比测试,详细解释了Spark开发中map和mapPartitions两个算子的区别。map算子对每个元素操作,而mapPartitions对每个分区操作,适用于处理大数据时减少数据库连接创建。在数据量较小且无数据库连接的场景下,map效率更高;但在涉及数据库操作时,mapPartitions因减少连接创建而更优,但需注意可能的内存溢出问题。
大数据开发工作中,在使用spark框架的时候经常会使用map算子,有时候又会使用mapPartition算子,怎么区分这俩个算子使用场景呢,通过这篇文章的的阅读,帮你区分他们的不同,以及推荐的使用场景。
一、源码分析
1. map算子源码
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF)) }
2. mapPartitions算子源码
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
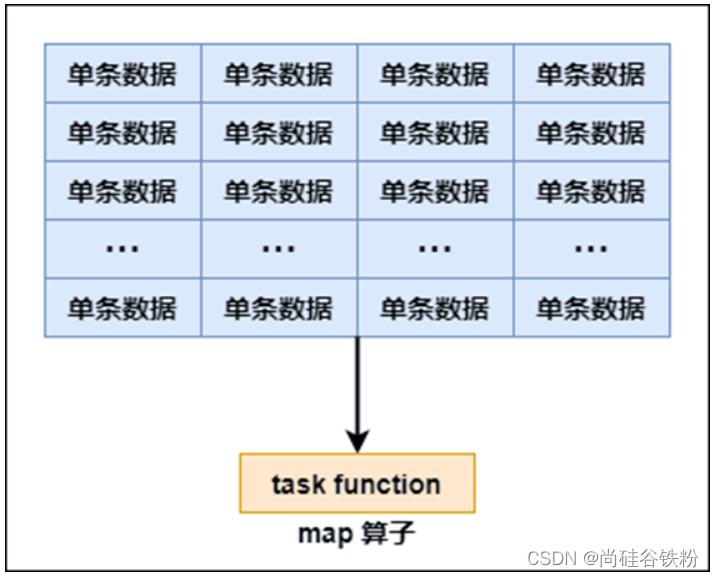
function要执行1万次,也就是对每个元素进行操作。
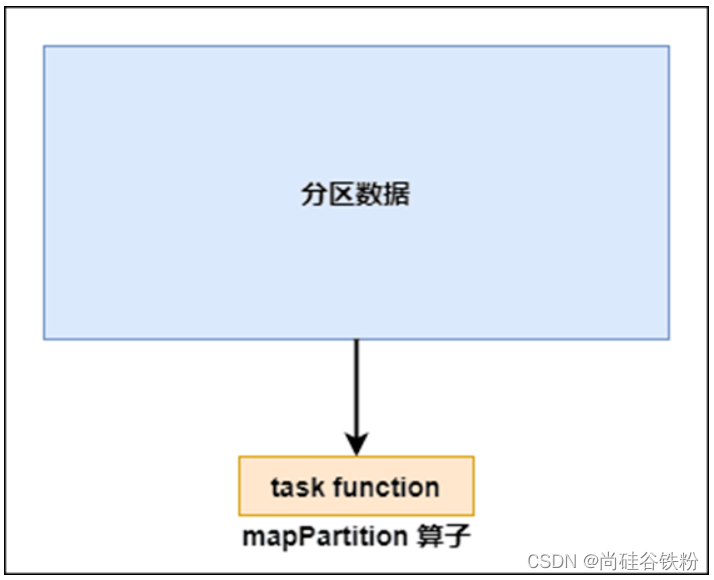
如果是mapPartition算子,由于一个task处理一个RDD的partition,那么一个task只会执行一次function,function一次接收所有的partition数据,效率比较高。
二、对比
1. 相似
map算子和mapPartitions算子底层都是构建MapPartitionsRDD。
2. 区别
函数功能方面:
map算子传入的函数的功能,是将一个元素处理后返回另一个元素;
mapPartitions算子传入的函数的功能,是将一个迭代器(一批元素)处理后返回另一个迭代器(一批元素);
函数执行方面:
map算子中,一个迭代器中包含算子需要处理的所有元素,有多少个元素,传入的函数就执行多少次;
mapPartitions算子中,一个迭代器包含一个分区中的所有元素,函数一次处理一个迭代器的数据,即一个分区调用一次函数;
三、代码测试
1.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









