







 本文介绍了STL中的键值对概念,重点阐述了set和map容器的使用,包括set的插入、去重机制以及map的插入、统计次数和有序特性。特别强调了set底层的红黑树实现和map的二叉搜索树排序原理。
本文介绍了STL中的键值对概念,重点阐述了set和map容器的使用,包括set的插入、去重机制以及map的插入、统计次数和有序特性。特别强调了set底层的红黑树实现和map的二叉搜索树排序原理。
前言: map/set是STL的关联式容器。关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
目录
- 键值对的介绍
- set的使用
- set的插入
- set的去重
- set的介绍
- map的使用
- map的插入
- map的统计次数
- map的中英互译
- map的介绍
键值对介绍
键值对是什么?
键值对是一个能存储两个数据的结构体,数据分为键和值,其中一个数据(键)代表着整体数据(进行运算时只考虑其中一个数据,这个数据就叫做键)
为什么有键值对的出现?
通常我们需要将两个数据存储到同一容器的某一个空间,这样就能方便通过键直接找到值。
例如:我们不用键值对存储,我们就要将两个数据存储到两个容器,遍历一遍找到了一个数据,而又要找这个数据的对应数据时,又必须遍历另一个容器,会大大降低效率
下面是SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
set的使用
set的插入
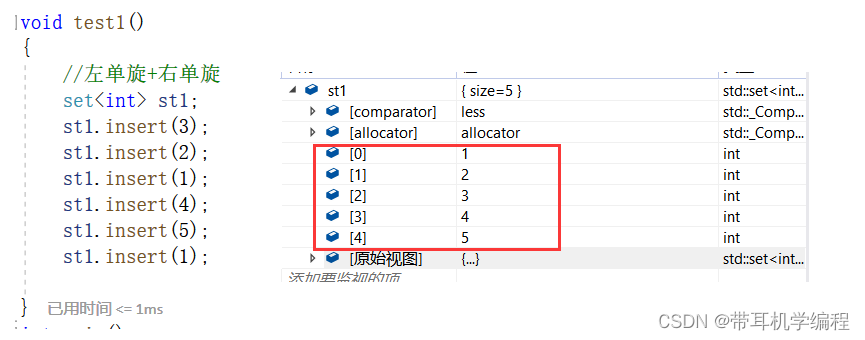
下面是set底层红黑树的旋转(左单旋,右单旋 ,变色)

set的去重
可以看到上面插入了两个1,但只有一个1被插入

set的介绍
问:为什么set存的是value(值), 而不存key-value(键值)我们却叫他关联式容器呢?
与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
所以set中插入元素时,只需要插入value即可,不需要构造键值对。
set是基于搜索二叉树的规则实现的,介绍搜索二叉树的时候说了,因为搜索二叉树在某些极端情况下会退化为链表,所以为了控制它的高度,就有了自动控制高度的搜索二叉树->set
set随之而来的特性:
- set中的元素不可以重复(因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列
自动化搜索的二叉树一般用的是红黑树来实现
set中的元素默认按照小于来比较
set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2n
问:set中的元素不允许修改(为什么?)
答:这里也是基于二叉搜索树的规则来的,如果修改了,则会破坏二叉搜索树的规则,所以使用者是不允许修改的
map的使用
map的插入
map的插入流程和set的插入流程基本一样
map统计次数
map统计次数有三种写法:
第一种:
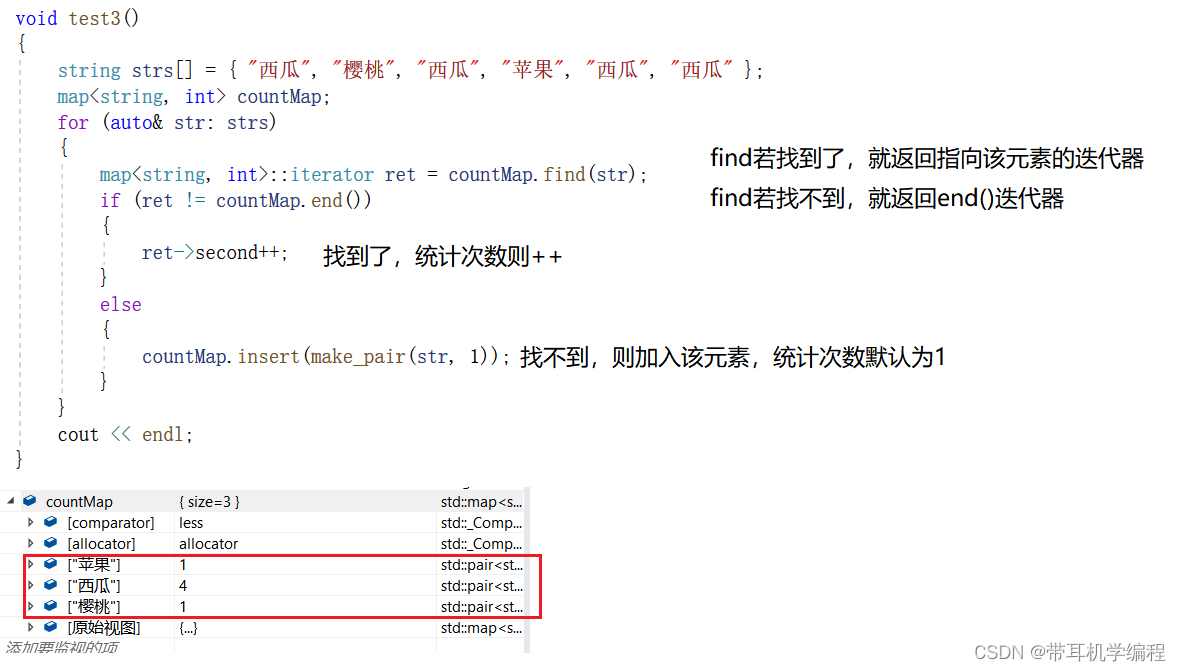
第二种:
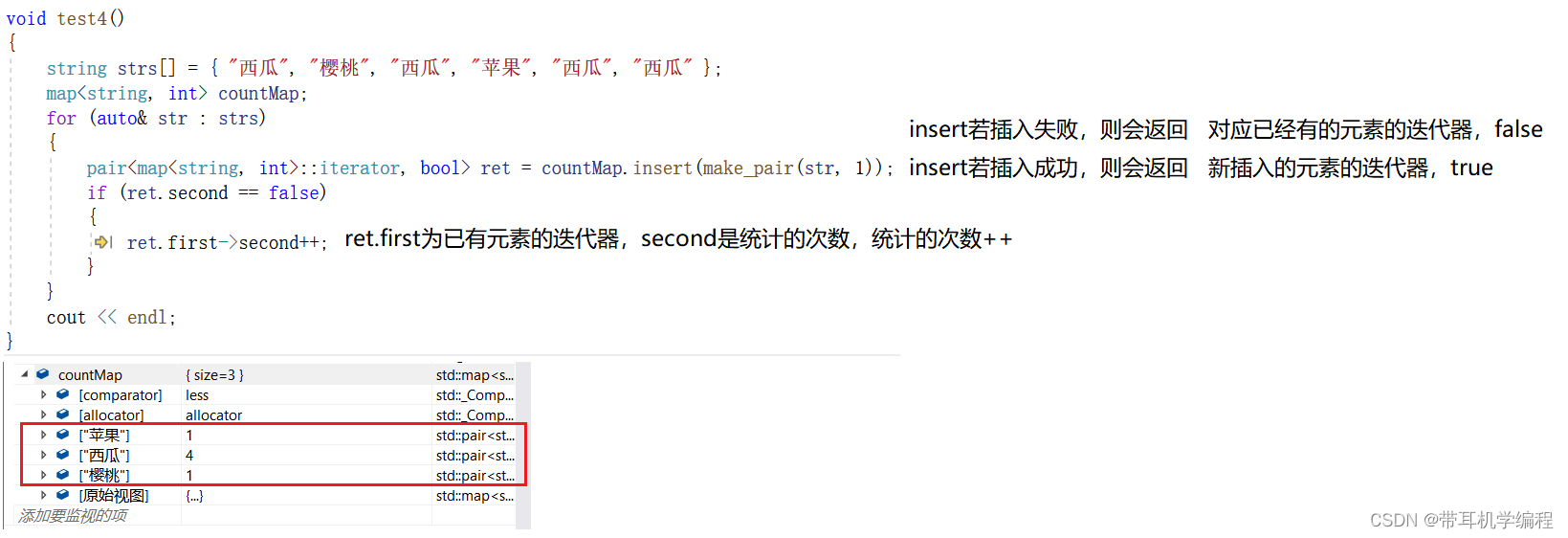
第三种:
operator[]操作符重载的介绍:
通俗的来讲就是若map中没有这个元素则插入这个元素,有这个元素则返回它value值的引用

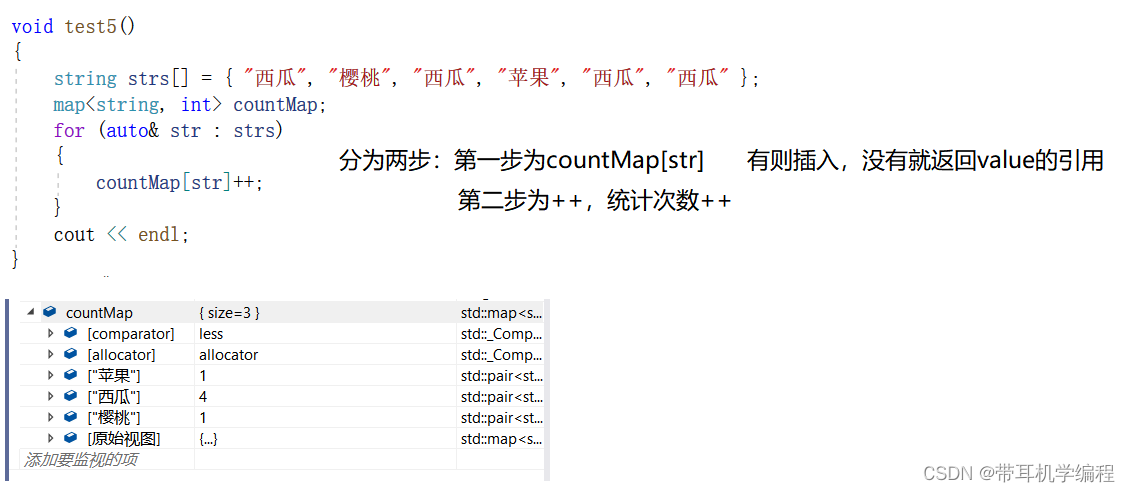
map中英互译

map的介绍
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
- 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T> value_type;- 在内部,map中的元素总是按照键值key进行比较排序的。
- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









