







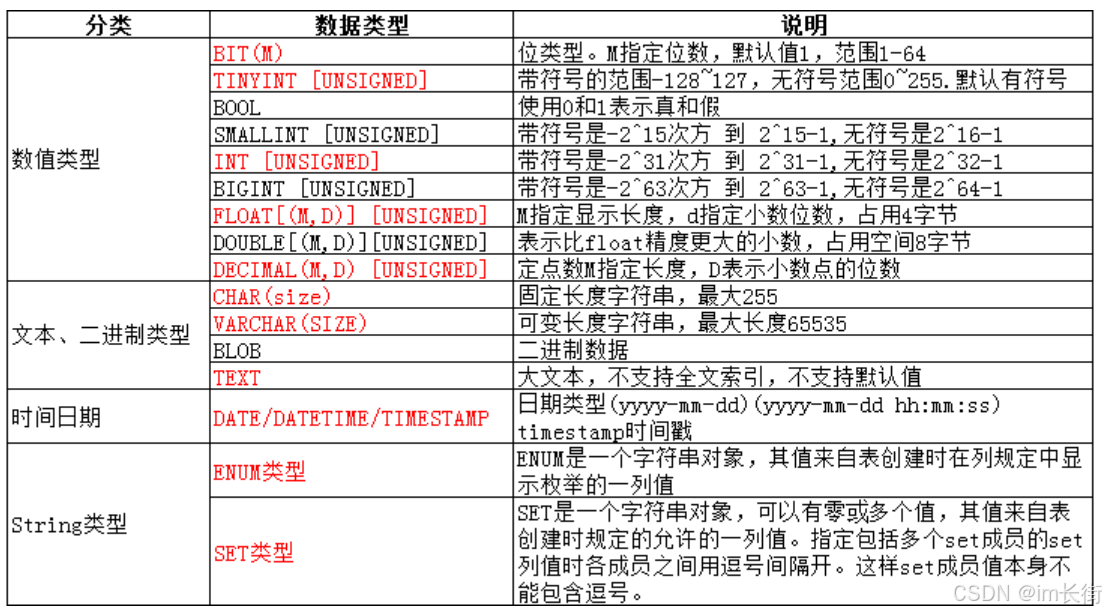
数值类型
tinyint类型
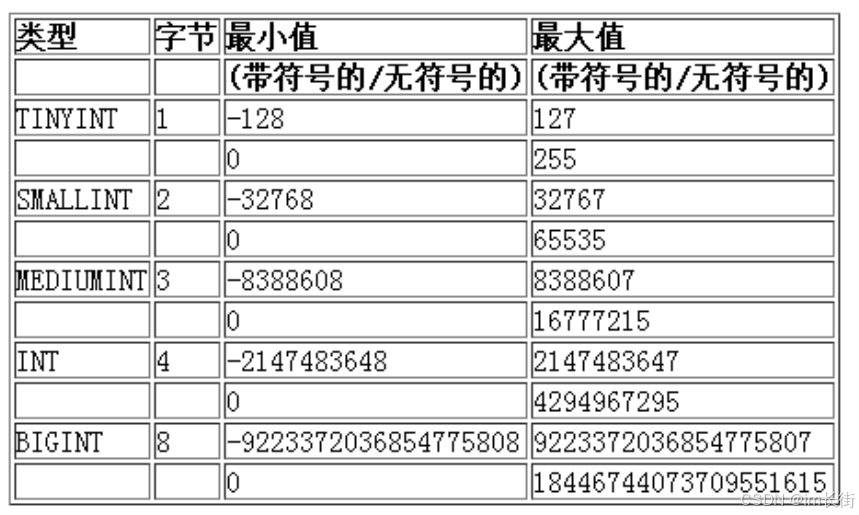
他们的区别就是能表示的范围不同
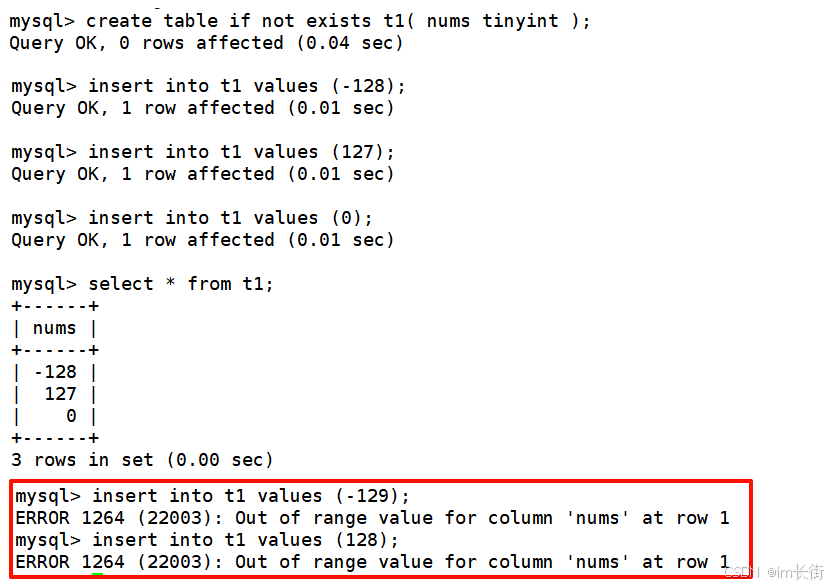
示例:以tinyint类型为例,其他都是类似的
发现:如果我们插入的数据超过了数据类型指定的范围,mysql的做法是直接拒绝你的插入,不让你插入。我们对比C语言,如char a = 1234567;这个语句并不会和mysql一样直接拒绝,而是发生截断。
为什么mysql采取这样的方案呢?
mysql插入数据时必须保证数据的完整性,如果不完整,数据就没有信任度了。反过来,当我们使用这些数据库里的数据的时候,我们知道这些数据一定是一致性的,合法的。所以在mysql中,一般而言,数据类型本身也是一种约束。什么是约束?能倒逼程序员,让程序员尽快自发的去遵守去正确的插入,约束的是程序员(也就是数据库的使用者)。另外,如果你错误的使用了,mysql也能保证数据插入的合法性。
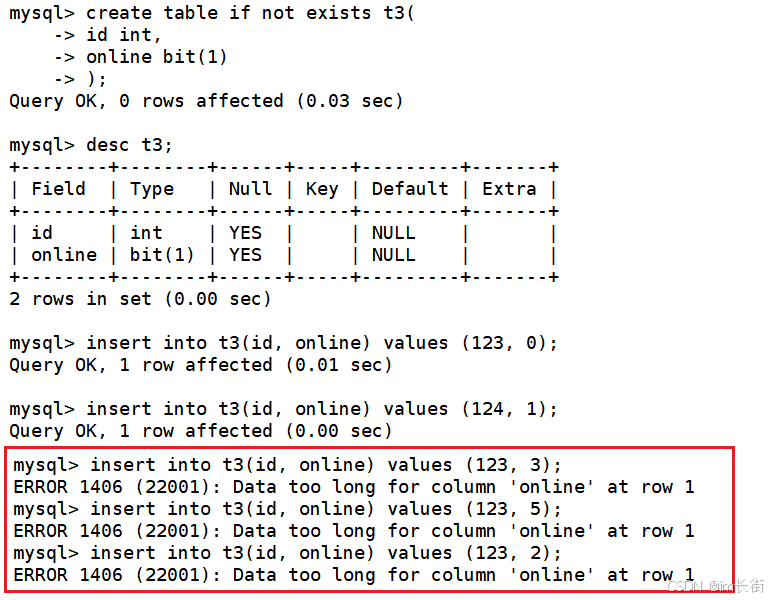
建表的时候如何选择类型呢?是否要unsigned?没有固定的要求,要结合实际场景选择适当的数据类型。
bit类型
语法:
BIT(M):位类型。M指定位数,默认值1,范围1-64
示例:
类型是有约束性的,这里发现不行,因为只有一个bit位
bit类型,在5.7版本(右边)中这里本来是不会显示的,因为显示的是ASCII字符,是为0为1的不可显示字符。在8.0版本(左边)转换为了十六进制来显示。存的数据是原来的数据,显示的时候是把原来的数据拿出来处理后显示。
这也说明了一个问题:在计算机中所有数据都可以视为二进制数据,只不过读取、处理和表现的方式不同而已。

默认值为1,范围为1-64。
小数类型
float类型
语法:
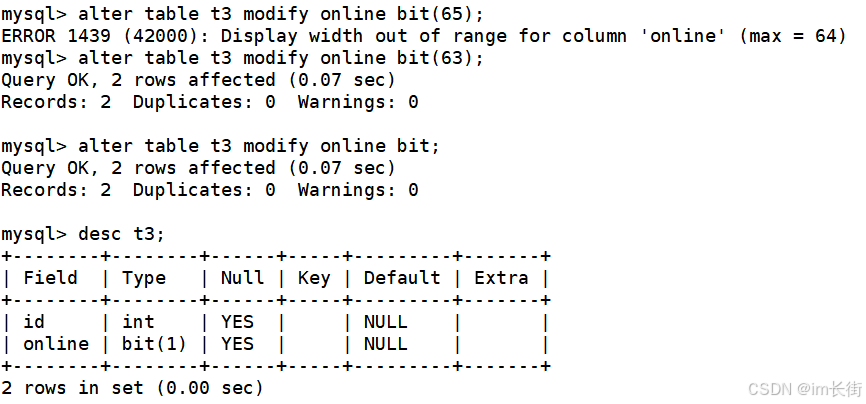
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节。比如,float(4, 2)表示的范围是-99.99~99.99,MySQL在保存值是会进行四舍五入;无符号的范围为0-99,99。
示例:
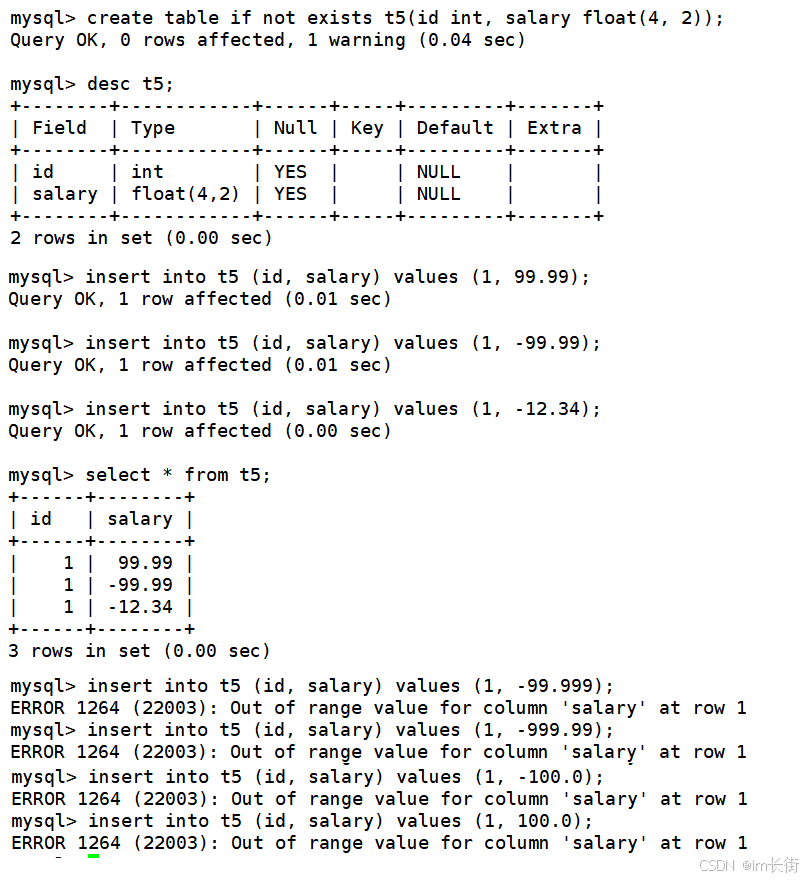
值的范围都必须符合要求,否则会插入失败
要求的是两位精度,如果你传了更多位的小数,mysql会进行四舍五入的方式截断。
为什么之前的类型不会截断数据,而小数却可以?
在计算机中,是无法精确的表示某一个小数的值的,所以只能存储与其十分相近的值来替代,所以本来就是不精准的,截断也就无关痛痒了。
decimal类型
decimal可以对表C语言的double类型,是float的精度更高的类型
语法:
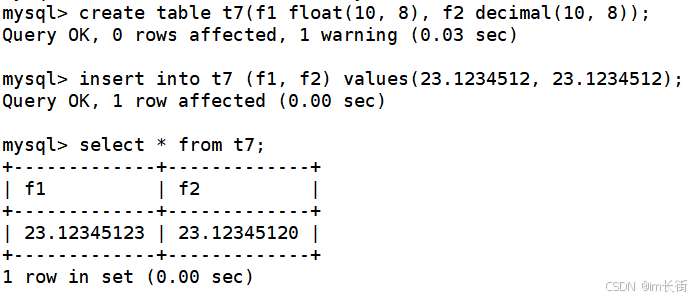
decimal(m,d)[unsigned]:定点数m指定长度,d表示小数点的位数
示例:
可以看到float有精度损失,而decimal没有。
建议:如果希望小数的精度高,推荐使用decimal
字符串类型
char类型
语法:
char(L):固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255。
示例:
因为插入的字符超过了固定长度,不让插入了,符合预期。
我们这是utf8编码,一个汉字占3个字节,gbk编码占两个字节,我们采用的是utf8编码,按理说’中国’总共占6 个字节,而我们定义的长度只有2,为什么依然能插入呢?虽然单位为字符,但这里的字符与C/C++里的字符概念是不一样的,一个字符是一个字节,而mysql的一个字符是一个符号。


小扩展:
我们用搜狗输入法输入一个汉字,直到我们看到这个汉字,这期间采用了编码方式吗?
没有,采用的是机内码(又称汉字ASCII码),计算机通过读取汉字的机内码,并利用字体文件中的字形信息来“渲染”或“绘制”出汉字的图像。
既然可以不用编码格式,那为什么mysql不采用这种方法,偏偏要用编码格式呢?
其实不止mysql,几乎所有软件都要有编码格式,因为当汉字需要从一台计算机传输到另一台计算机(如服务器)时,由于两台计算机可能使用不同的操作系统、字符编码标准或字体库,直接传输机内码可能会导致接收端无法正确解析和显示汉字。所以在传输过程中,需要一种专门编码格式来控制,以确保接收端能够正确的显示。
varchar类型
语法:
varchar(L):可变长度字符串,L表示字符长度,最大长度65535个字节。
示例:
不是说最大65535吗?是65535个字节,不是字符,最大只能定义65535/3=21845个字符。所以varchar(6)圆括号里的代表最多字符的个数。
varchar和char的圆括号的意义都是相同的,都表示上限,那他们的区别是什么呢?用起来没有区别,但是底层有区别,插入就相当于C语言中静态的数组,而varchar就相当于动态数组,但是该动态数组的总容量capacity是固定的。就好比我给你最大限制6个字节,但是你没有存储到6个字节,你只用了1个字节,那我底层就是1个字节给你来存储,并不会开辟6个字节给你存储,所以这就很好的控制了空间的利用率。

char和varchar比较
| 实际存储 | char(4) | varchar(4) | char占用字节 | varchar占用字节 |
|---|---|---|---|---|
| abcd | abcd | abcd | 4*3=12 | 4*3 + 1=13 |
| A | A | A | 4*3=12 | 1+3=4 |
| Abcde | × | × | 数据超过长度 | 数据超过长度 |
如何选择定长或变长字符串?
如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5。
如果数据长度有变化,就使用变长(varchar),比如:名字,地址,但是你要保证最长的能存的进去。
定长的磁盘空间比较浪费,但是效率高。
变长的磁盘空间比较节省,但是效率第。
定长的意义是,直接开辟好对应的空间。
变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期和时间类型
常用的日期有如下三个:
- date:日期格式
yyyy-mm-dd,占用三个字节。比如说生日。 - datetime:时间日期格式
yyyy-mm-dd HH:ii:ss表示范围从1000到9999,占用八字节。比如说评论时间。 - timestamp:时间戳,从1970年开始的
yyyy-mm-dd HH:ii:ss格式和datetime完全一致,占用4个字节
示例:
mysql的5.7版本和mysql的8.0版本略有差别
8.0版本:
default表示,当你插入时但没有插入t3这列属性,则会自动以current_timestamp插入(即以当前系统时间插入)
可以看到自动插入了t3,时间为了当前系统时间。
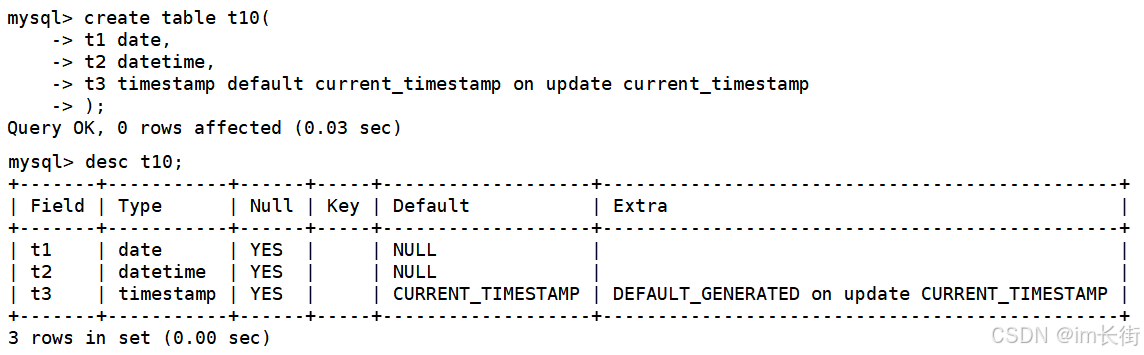

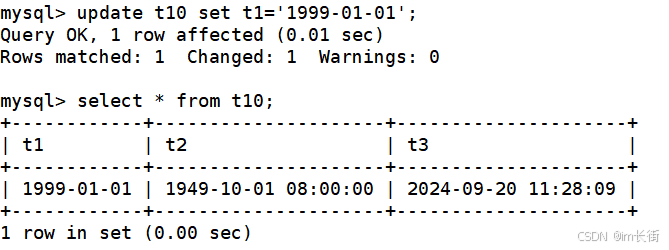
extra表示额外的执行命令,为只要你更新了这一行的某个列属性(除了t3,t1或t2),t3就会自动的更新为当前系统时间。
可以看到只改了t1,而t3也跟着改了,且为当前系统时间。
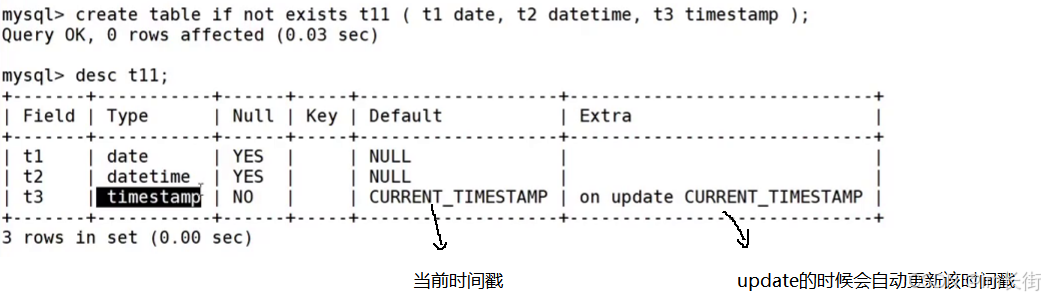
而5.7版本创建表的时候,t3会自动的添加default和extra。其他效果和8.0版本一样
enum和set类型
语法:
- enum:枚举,“单选”类型。
enum(‘选项1’, ‘选项2’, ‘选项3’)。
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值,而且处于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值一次对应如下数字:1,2,3…最多65535;当我们添加枚举值是,也可以添加对应的数字编号。
语法:
- enum:枚举,“单选”类型
enum(‘选项1’, ‘选项2’, ‘选项3’)
该设定只是提供了若干个选项的值,最终一个单元格中,设计课存储其中任意多个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值一次对应如下数字:1,2,4,8,16,32,…最多64。
示例:

enum和set类型查找:

集合查询使用find_in_set函数:
find_in_set(sub, str_list):如果sub在str_list中,则返回下标;如果不在,返回0;str_list用逗号分割的字符串。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









