




 本文介绍了信息熵的概念,由信息论之父香农提出,用于量化信息的不确定性。通过实例展示了如何计算信息熵,并对一串包含A到E符号的消息进行了香农编码和霍夫曼编码的步骤及结果展示。香农编码根据概率从大到小分配码字,而霍夫曼编码通过构建最优二叉树实现更高效的编码。
本文介绍了信息熵的概念,由信息论之父香农提出,用于量化信息的不确定性。通过实例展示了如何计算信息熵,并对一串包含A到E符号的消息进行了香农编码和霍夫曼编码的步骤及结果展示。香农编码根据概率从大到小分配码字,而霍夫曼编码通过构建最优二叉树实现更高效的编码。
信息熵简介
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。
直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
信息论之父克劳德·艾尔伍德·香农第一次用数学语言阐明了概率与信息冗余度的关系。
信息论之父 C. E. Shannon 在 1948 年发表的论文“通信的数学理论( A Mathematical Theory of Communication )”中, Shannon 指出,任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。
Shannon 借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为“信息熵”,并给出了计算信息熵的数学表达式。
信息熵运算实例
一串消息包含A,B,C,D,E共5类符号,其内容为AABBBBAAAACCCCCCCCCEEEEEEDDDDEEEEEEEEEEEEE,分别对其进行香农编码和霍夫曼编码
我们可以看到内容总共含42个符号,其中6个A,4个B,9个C,4个D,19个E,其对应的概率分别为1/7,2/21,3/14,2/21,19/42
可以看到其概率分布如下
P(A)=1/7
P(B)=2/21
P©=3/14
P(D)=2/21
P(E)=19/42
信息熵计算为2.043
香农编码
编码步骤
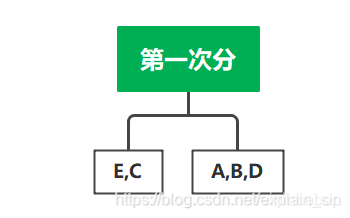
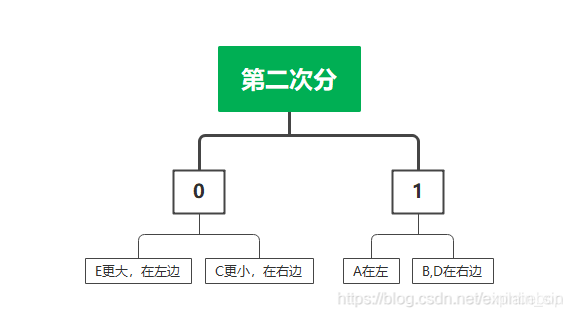
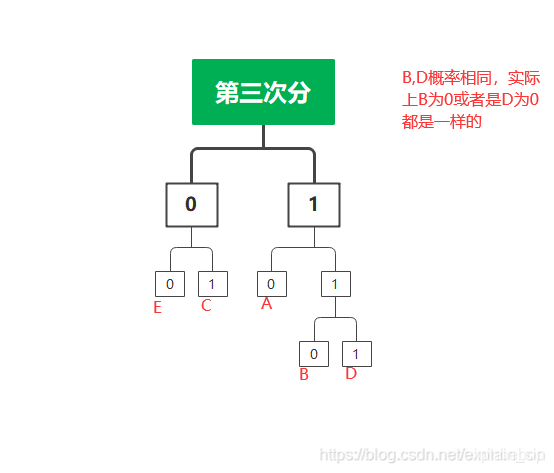
(1)将信源符号按概率从大到小顺序排列,为方便起见
(2)按计算第i个符号对应的码字的码长(取整);
(3) 计算第i个符号的累加概率 ;
(4)将累加概率变换成二进制小数,取小数点后 位数作为第i个符号的码字。



实例演示
| E | C | A | B | D |
|---|---|---|---|---|
| 19/42 | 3/14 | 1/7 | 2/21 | 2/21 |
最终编码结果
| E | C | A | B | D |
|---|---|---|---|---|
| 00 | 01 | 10 | 110 | 111 |
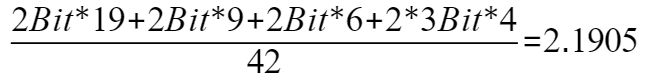
霍夫曼编码
香农-范诺编码算法并非总能得到最优编码。1952年, David A. Huffman提出了一个不同的算法,这个算法可以为任何的可能性提供出一个理想的树。
香农-范诺编码是从树的根节点到叶子节点所进行的的编码,哈夫曼编码算法却是从相反的方向,暨从叶子节点到根节点的方向编码的。
编码步骤
1.为每个符号建立一个叶子节点,并加上其相应的发生频率
2.当有一个以上的节点存在时,进行下列循环:
把这些节点作为带权值的二叉树的根节点,左右子树为空
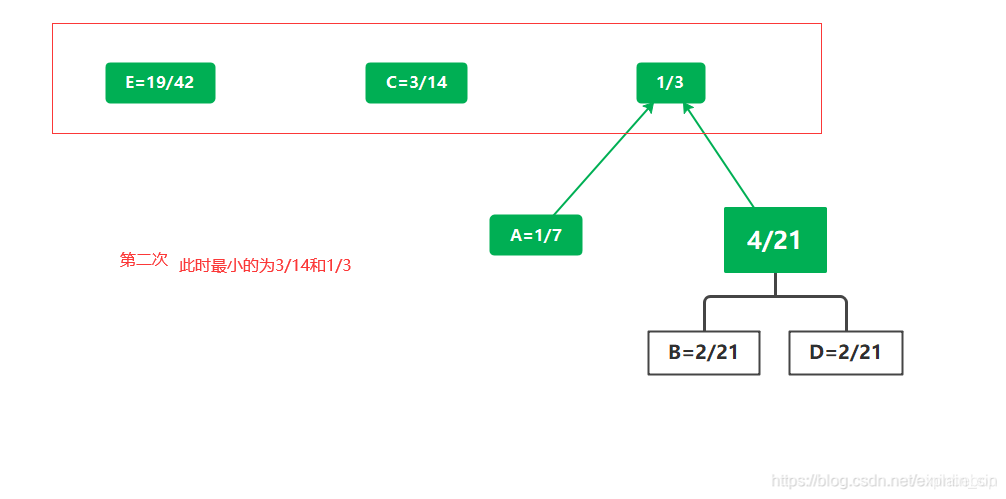
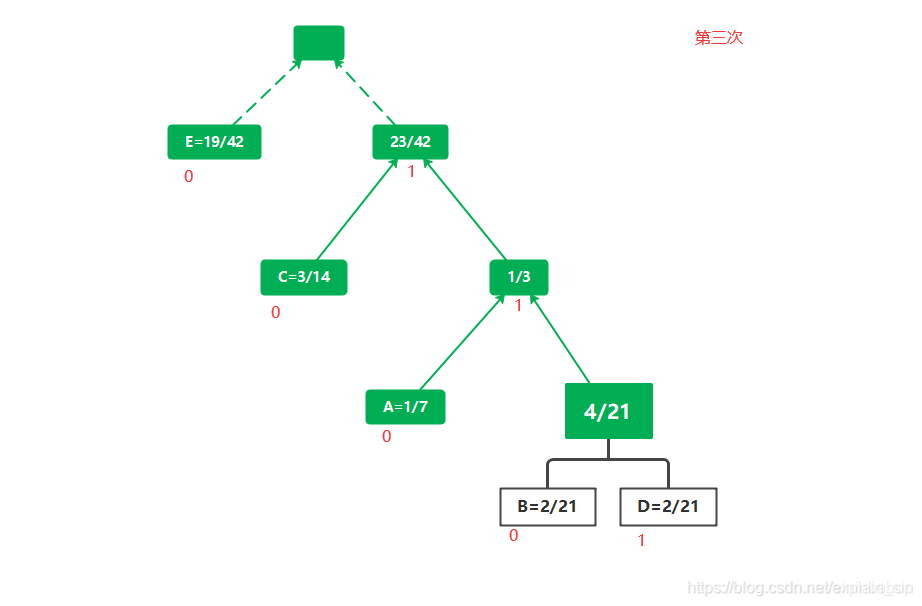
选择两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且至新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
把权值最小的两个根节点移除
将新的二叉树加入队列中。
3.最后剩下的节点暨为根节点,此时二叉树已经完成。
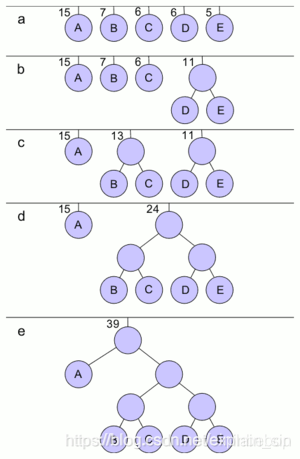
实例演示
| E | C | A | B | D |
|---|---|---|---|---|
| 19/42 | 3/14 | 1/7 | 2/21 | 2/21 |

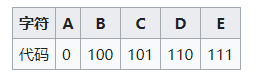
最终编码结果
| E | C | A | B | D |
|---|---|---|---|---|
| 0 | 10 | 110 | 1110 | 1111 |
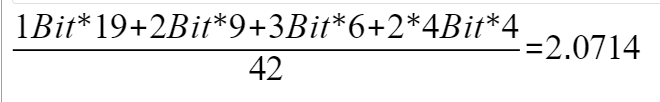

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









