







 超级会员免费看
超级会员免费看
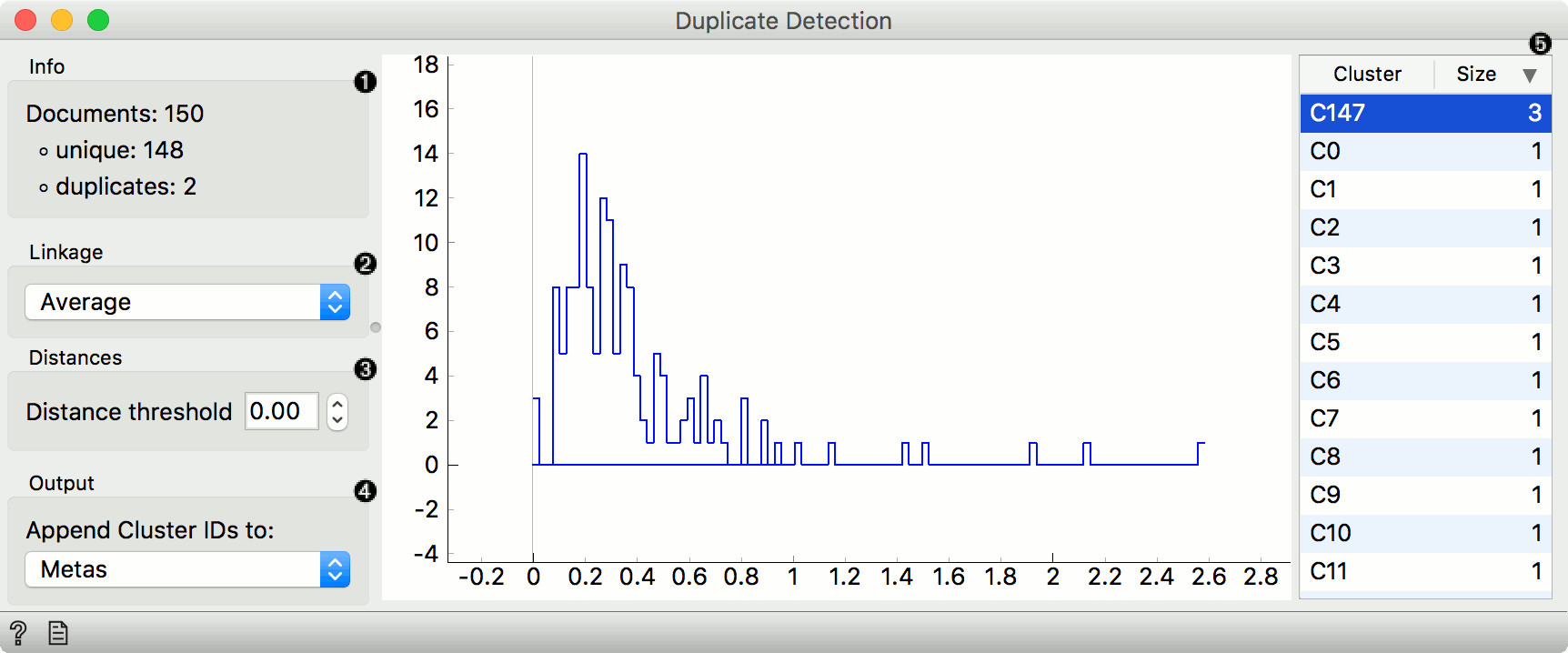
重复检测(Duplicate Detection)
从语料库中检测并移除重复项。
输入
- 距离(Distances):距离矩阵。
输出
- 无重复语料库(Corpus Without Duplicated):移除重复项后的语料库。
- 重复集群(Duplicates Cluster):属于所选集群的文档。
- 语料库(Corpus):附加集群标签的语料库。
重复检测通过聚类算法识别语料库中的重复项。该功能可与 Twitter 小部件结合使用,用于移除转发或其他相似文档。
可通过可视化界面拖动垂直线设置相似度阈值:
- 向左拖动表示需更高的相似度才被视为重复项(阈值更低)。
- 也可在控制区域手动输入阈值。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











