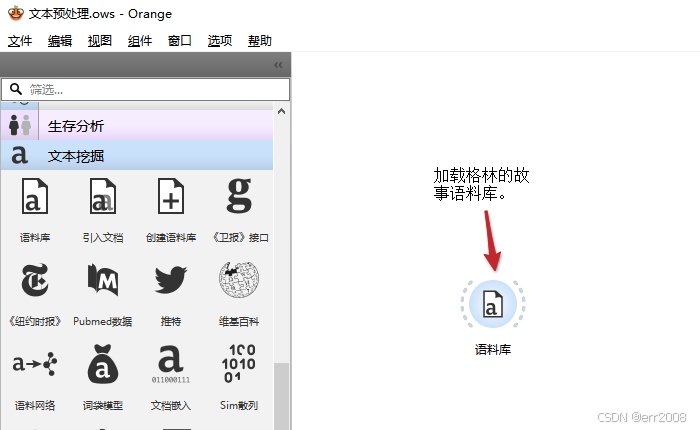
文本预处理 文本挖掘需要仔细的预处理。下面是一个使用简单的预处理从文档创建tokens的工作流。首先,它应用小写,然后将文本拆分为单词,最后,它删除频繁的非索引词。预处理是特定于语言的,因此在需要时将语言更改为文本的语言。预处理的结果可以在词汇云中观察。 步骤1:启动Orange3 通过执行 python -m Orange.canvas 启动Orange3: 步骤2:拖动语料库组件   在文本挖掘里找到语料库组件:   拖动组件到画布:   双击组件,并加载数据:








 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 39
39

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








