




📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
在人工智能领域,大模型(如GPT、BERT等)凭借其庞大的参数量和强大的计算能力在自然语言处理、计算机视觉等任务中表现出了卓越的性能。然而,随着这些大模型的应用不断扩展,如何高效部署和应用这些模型成为了一个重要问题。尤其是在资源受限的环境下,如何降低计算开销、减小模型体积,同时保持其性能,成为了技术发展的一个难题。
为了解决这个问题,模型蒸馏(Model Distillation) 技术应运而生。本文将详细介绍大模型蒸馏技术的原理、流程、应用场景及挑战,帮助你理解这一技术如何有效地将大模型的知识迁移到小模型中,从而实现高效的推理和部署。
一. 什么是模型蒸馏?
模型蒸馏是通过将大模型的知识迁移到小模型的一种方法。简单来说,蒸馏的目的是通过“蒸馏”大模型的知识,得到一个较小但仍具备相似表现的小模型。这一过程可以帮助我们减少计算资源和存储消耗,同时在某些场景下,蒸馏后的模型甚至可以提供比大模型更快的推理速度。
模型蒸馏最早由Hinton等人在2015年提出,并在之后的研究中被广泛应用于深度学习的各类任务中。
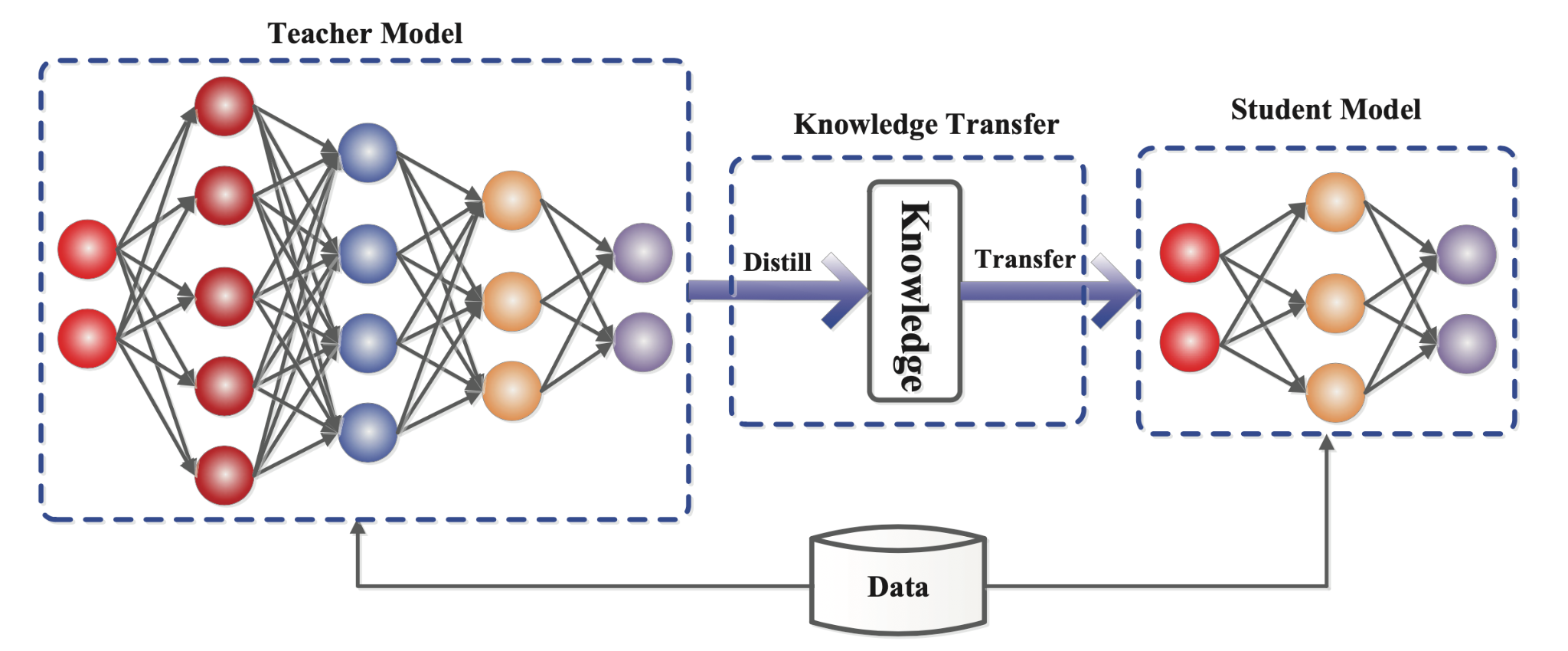
二. 大模型蒸馏的基本原理
2.1 知识蒸馏的工作流程
知识蒸馏的核心思想是通过训练一个较小的学生模型(student model)来模仿一个较大的教师模型(teacher model)的行为。具体来说,教师模型提供的知识不仅仅是预测结果(如标签类别),而是更丰富的信息,通常包括:
- 软标签(Soft Labels) :教师模型的输出概率分布(即各类标签的预测概率)。这些信息能够反映模型在各个类别之间的相对置信度,而不仅仅是一个硬标签。
- 特征映射(Feature Maps) :教师模型中间层的特征,可以帮助学生模型学习更加复杂的抽象。
蒸馏过程中的目标
在蒸馏过程中,学生模型的训练目标是尽量模仿教师模型的行为。训练过程中,学生模型不仅要尽量将其输出概率与教师模型接近,还要模仿教师模型的中间特征(如果使用了中间特征蒸馏)。
公式化表达:
-
输出蒸馏:将学生模型的输出概率分布与教师模型的概率分布进行对比,使用交叉熵损失函数来度量两者的差异。
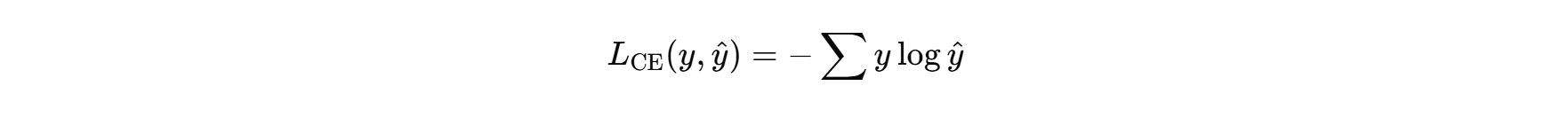
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









