




📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
近年来,自监督学习(Self-Supervised Learning,SSL)作为一种新兴的学习范式,在计算机视觉、自然语言处理等多个领域都取得了显著的进展。与传统的监督学习不同,自监督学习不依赖于人工标注的数据,而是通过从未标注的数据中自动生成标签,进而进行学习。这一特性使得自监督学习在数据稀缺的场景中展现出强大的潜力。本文将深入探讨自监督学习的基本概念、方法以及实际案例,以帮助读者更好地理解这一重要技术。
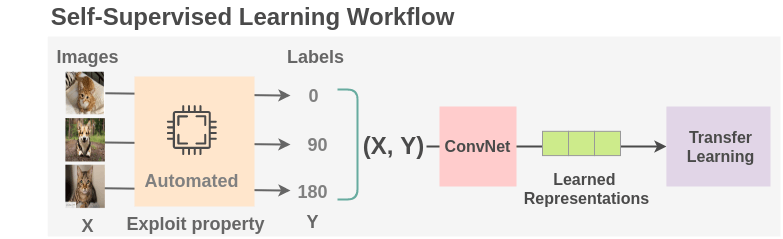
一、自监督学习的概念
自监督学习(Self-Supervised Learning, SSL)是一种无监督学习的分支,旨在通过利用数据自身的结构和特征来生成标签,从而进行模型训练。与传统的监督学习方法依赖于大量标注数据的需求不同,自监督学习通过设计特定的任务,利用未标注数据中的信息创造出伪标签,使模型可以在没有人工标注的情况下进行学习。这一特性使得自监督学习在处理大规模未标注数据时展现出了独特的优势。
1.1 自监督学习的基本原理
自监督学习的核心在于通过创造性地设计学习任务,使得模型能够从数据中自动学习特征。这些任务通常基于数据的内在结构,目的是帮助模型理解数据的潜在规律。例如,模型可以通过以下几种方式来生成伪标签:
-
数据变换任务:对输入数据进行一定的变换或生成不同的视图,模型的目标是重建原始输入或识别变换的类型。例如,在图像数据中,图像旋转、裁剪或翻转等操作都可以被视为自监督任务,模型需要学习如何恢复或识别这些变换。
-
上下文预测任务:模型通过预测输入数据的某个部分或上下文来学习数据的结构。例如,在文本数据中,模型可以通过掩码某些单词并预测它们来学习语言结构。
-
对比学习:通过对比不同样本之间的相似性和差异性,模型可以学习到有用的表示。例如,在图像领域,可以将同一图像的不同增强版本视为正样本,而不同图像视为负样本,通过对比学习来优化模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









