







 本文聚焦于无LiDAR自动驾驶车辆的3D感知系统,探讨构建不依赖高密度激光雷达的3D感知系统。研究分析了BEV感知模型设计和训练中的高影响因素,如批处理大小、输入分辨率等,还证明雷达数据可提升性能,并分析了雷达使用细节。
本文聚焦于无LiDAR自动驾驶车辆的3D感知系统,探讨构建不依赖高密度激光雷达的3D感知系统。研究分析了BEV感知模型设计和训练中的高影响因素,如批处理大小、输入分辨率等,还证明雷达数据可提升性能,并分析了雷达使用细节。
论文地址:https://arxiv.org/pdf/2206.07959.pdf
地址:https://simple-bev.github.io/ 内有视频
Abstract
Abstract— Building 3D perception systems for autonomous vehicles that do not rely on high-density LiDAR is a critical research problem because of the expense of LiDAR systems compared to cameras and other sensors.
摘要— 在自动驾驶车辆中构建不依赖于高密度激光雷达(LiDAR)的3D感知系统是一个关键的研究问题,因为与相机和其他传感器相比,激光雷达系统的费用较高。
Recent research has developed a variety of camera-only methods, where features are differentiably “lifted” from the multi-camera images onto the 2D ground plane, yielding a “bird’s eye view” (BEV) feature representation of the 3D space around the vehicle.
最近的研究已经发展出各种仅使用摄像头的方法,其中特征可区分地从多摄像头图像中“抬升”到二维地平面,生成车辆周围3D空间的“鸟瞰图”(BEV)特征表示。
This line of work has produced a variety of novel “lifting” methods, but we observe that other details in the training setups have shifted at the same time, making it unclear what really matters in top-performing methods.
这一领域的研究产生了各种新颖的“抬升”方法,但我们观察到培训设置中的其他细节同时发生了变化,使得在表现优异的方法中究竟哪些因素真正重要变得不清晰。
We also observe that using cameras alone is not a real-world constraint, considering that additional sensors like radar have been integrated into real vehicles for years already.
我们还观察到仅使用摄像头并非现实世界的限制,考虑到多年来已经将雷达等额外传感器集成到实际车辆中。
In this paper, we first of all attempt to elucidate the high-impact factors in the design and training protocol of BEV perception models.
在本文中,首先我们试图阐明BEV感知模型设计和训练协议中的高影响因素。
We find that batch size and input resolution greatly affect performance, while lifting strategies have a more modest effect—even a simple parameter-free lifter works well.
我们发现批处理大小和输入分辨率对性能有很大影响,而抬升策略的影响较小,即使是一个简单的无参数抬升器也能很好地工作。
Second, we demonstrate that radar data can provide a substantial boost to performance, helping to close the gap between camera-only and LiDAR-enabled systems.
其次,我们证明雷达数据可以显著提升性能,有助于弥合仅使用摄像头和启用LiDAR系统之间的差距。
We analyze the radar usage details that lead to good performance, and invite the community to re-consider this commonly-neglected part of the sensor platform.
我们分析了导致良好性能的雷达使用细节,并邀请社区重新考虑传感器平台中这个常常被忽视的部分。
- INTRODUCTION
I. INTRODUCTION
I. 引言
There is great interest in building 3D-aware perception systems for LiDAR-free autonomous vehicles, whose sensor platforms typically constitute multiple RGB cameras, and multiple radar units.
对于通常由多个RGB摄像机和多个雷达单元组成的传感器平台的无LiDAR自动驾驶车辆,构建3D感知系统存在着极大的兴趣。
While LiDAR data enables highly accurate 3D object detection [1, 2], the sensors themselves are arguably too expensive for large-scale deployment [3], especially as compared to current camera and radar units.
虽然LiDAR数据可以实现高度准确的3D对象检测[1, 2],但传感器本身对于大规模部署而言可能过于昂贵[3],尤其与当前的摄像机和雷达单元相比。
Most current works focus on producing an accurate “bird’s eye view” (BEV) semantic representation of the 3D space surrounding the vehicle, using multi-view camera input alone.
大多数当前的工作都集中于使用多视角摄像机输入单独生成车辆周围3D空间的准确“鸟瞰图”(BEV)语义表示。
This representation captures the information required for driving-related tasks, such as navigation, obstacle detection, and moving-obstacle forecasting.
这种表示捕获了与驾驶相关任务所需的信息,如导航、障碍物检测和移动障碍物预测。
We have seen extremely rapid progress in this domain: for example, BEV vehicle semantic segmentation IOU improved from 23.9 [4] to 44.4 [5] in just two years!
在这个领域我们已经看到了极快的进步:例如,在短短两年内,BEV车辆语义分割IOU从23.9 [4]提高到44.4 [5]!
While this progress is encouraging, the focus on innovation and accuracy has come at the cost of system simplicity, and risks obscuring “what really matters” for performance [6, ?].
虽然这种进展令人鼓舞,但对创新和准确性的关注牺牲了系统的简单性,并有可能掩盖了对性能“真正重要的东西” [6, ?]。
There has been a particular focus on innovating new techniques for “lifting” features from the 2D image plane(s) onto the BEV plane.
特别关注了从2D图像平面向BEV平面“提升”特征的新技术的创新。
For example, some work has explored using homographies to warp features directly onto the ground plane [7], using depth estimates to place features at their approximate 3D locations [8, 9], using MLPs with various geometric biases [10, 11, 12], and most recently, using geometry-aware transformers [13] and deformable attention across space and time [5].
例如,一些研究已经探索了使用单应性直接将特征变形到地面[7],使用深度估计将特征放置在其近似的3D位置[8, 9],使用具有各种几何偏移的MLPs[10, 11, 12],以及最近使用几何感知变换器[13]和时空可变形注意力[5]。
At the same time, implementation details have gradually shifted toward using more powerful backbones and higher-resolution inputs, making it difficult to measure the actual impact of these developments in lifting.
同时,实现细节逐渐转向使用更强大的骨干网络和更高分辨率的输入,这使得很难衡量这些在提升方面的发展的实际影响。
We propose a model where the “lifting” step is parameter-free and does not rely on depth estimation: we simply define a 3D volume of coordinates over the BEV plane, project these coordinates into all images, and average the features sampled from the projected locations.
我们提出了一个模型,其中**“提升”步骤是无参数的**,不依赖深度估计:我们简单地在BEV平面上定义一个3D坐标体积,将这些坐标投影到所有图像中,并平均从投影位置采样的特征。
When this simple model is tuned well, it exceeds the performance of state-of-the-art models while also being faster and more parameter-efficient.
当这个简单的模型调整得很好时,它的性能超过了最先进的模型,同时也更快、更参数高效。
We measure the independent effects of batch size, image resolution, augmentations, and 2D-to-BEV lifting strategy, and show empirically that good selection of input resolution and batch size can improve performance by more than 10 points (all other factors held equal), while the difference between the worst and best lifting methods is only 4 points – which is particularly surprising because lifting methods have been the main focus of earlier work.
我们测量了批大小、图像分辨率、增强和2D到BEV提升策略的独立效果,并从经验上显示,良好的输入分辨率和批大小选择可以提高性能超过10个百分点(其他所有因素保持不变),而最差和最好的提升方法之间的差异仅为4个百分点,这尤其令人惊讶,因为提升方法一直是早期工作的主要焦点。
We further show that results can be substantially improved by incorporating input from radar.
我们进一步显示,通过整合雷达的输入,结果可以得到实质性的改善。
While recent efforts have focused on using cameras and/or LiDAR, we note that radar sensors have been integrated into real vehicles for years already [14], and cameras plus radar performs far better than cameras alone.
尽管近期的努力主要集中于使用摄像机和/或LiDAR,但我们注意到雷达传感器已经集成到实际车辆中多年了[14],而摄像机加雷达的性能远远超过单独使用摄像机。
While using cameras alone may give the task a certain purity (requiring metric 3D estimates from 2D input), it does not reflect the reality of autonomous driving, where noisy metric data is freely available, not only from radar but from GPS and odometry.
尽管仅使用摄像机可能会使任务具有一定的纯度(需要从2D输入获得度量3D估计),但这并不反映自动驾驶的现实情况,其中嘈杂的度量数据是免费可用的,不仅来自雷达,还来自GPS和里程计。
The few recent works that discuss radar in the context of semantic BEV mapping have concluded that the data is often too sparse to be useful [3, 10].
少数近期在语义BEV映射背景下讨论雷达的工作得出结论,数据通常过于稀疏,无法发挥作用[3, 10]。
We identify that these prior works evaluated the use of radar alone, avoiding the multi-modal fusion problem, and perhaps missing the opportunity for RGB and radar to complement one another.
我们认为,这些先前的工作评估了单独使用雷达,避免了多模态融合问题,并且可能错过了RGB和雷达相互补充的机会。
We introduce a simple RGB+radar fusion strategy (rasterizing the radar in BEV and concatenating it to the RGB features) and exceed the performance of all published BEV segmentation models by a margin of 9 points.
我们引入了一个简单的RGB+雷达融合策略(在BEV中栅格化雷达并将其与RGB特征连接起来),并超过了所有已发布的BEV分割模型的性能,领先9个百分点。
This paper has two main contributions: First, we elucidate high-impact factors in the design and training protocol of BEV perception models. We show in particular that batch size and input resolution greatly affect performance, while lifting details have a more modest effect.
本文有两个主要贡献:首先,我们明确了BEV感知模型的设计和训练协议中的高影响因素。我们特别显示,批大小和输入分辨率对性能有很大影响,而提升细节的影响更为适中。
Second, we demonstrate that radar data can provide a large boost to performance with a simple fusion method, and invite the community to re-consider this commonly-neglected part of the sensor platform. We also release code and reproducible models to facilitate future research in the area.
其次,我们证明雷达数据可以通过简单的融合方法大大提高性能,并邀请社区重新考虑这部分常被忽视的传感器平台。我们还发布代码和可复现的模型,以促进该领域的未来研究。
2. RELATED WORK
II. 相关工作
A major differentiator in prior work on dense BEV parsing is the precise operator for “lifting” 2D perspective-view features to 3D, or directly to the ground plane.
在之前关于密集BEV解析的工作中,一个主要的区别在于将2D透视视图特征“提升”到3D或直接提升到地面的精确操作。
Parameter-free unprojection 无参数反投影
Parameter-free unprojection: This strategy, pursued in a variety of object and scene representation models [15, 16, 17], uses the camera geometry to define a mapping between voxels and their projected coordinates, and copies 2D features to voxels along their 3D rays.
无参数反投影:这种策略在各种对象和场景表示模型[15, 16, 17]中被采用,它使用摄像机几何来定义体素和它们的投影坐标之间的映射,并沿它们的3D射线将2D特征复制到体素上。
We specifically follow the implementation of Harley et al. [18], which bilinearly samples a subpixel 2D feature for each 3D coordinate.
我们特别遵循Harley等人[18]的实现,它为每个3D坐标双线性采样一个亚像素2D特征。
Parameter-free lifting methods are not typically used in bird’s eye view parsing tasks.
在鸟瞰图解析任务中,通常不使用无参数的提升方法。
Depth-based unprojection
Depth-based unprojection: Several works estimate per-pixel depth with a monocular depth estimator, either pretrained for depth estimation [8, 19, 20] or trained simply for the end-task [9, 21, 22], and used the depth to place features at their estimated 3D locations.
基于深度的反投影:一些工作使用单目深度估计器估计每像素的深度,要么为深度估计预先训练[8, 19, 20],要么简单地为最终任务训练[9, 21, 22],并使用深度将特征放置在它们估计的3D位置上。
This is an effective strategy, but note that if the depth estimation is perfect, it will only place “vehicle” features at the front visible surface of the vehicle, rather than fill the entire vehicle volume with features.
这是一种有效的策略,但请注意,如果深度估计是完美的,它只会将“车辆”特征放置在车辆的前部可见表面,而不是用特征填充整个车辆体积。
We believe this detail is one reason that naive unprojection performs competitively with depth-based unprojection.
我们认为这个细节是朴素反投影与基于深度的反投影有竞争力的一个原因。
Homography-based unprojection
Homography-based unprojection: Some works estimate the ground plane instead of per-pixel depth, and use the homography that relates the image to the ground to create a warp [23, 24, 7], transferring the features from one plane to another.
基于单应性的反投影:一些工作估计地面平面而不是每像素深度,并使用将图像与地面相关联的单应性创建一个扭曲[23, 24, 7],将特征从一个平面转移到另一个平面。
This operation tends to produce poor results when the scene itself is non-planar.
当场景本身不是平面的时候,这个操作往往产生不良的结果!!!。
MLP-based unprojection
表示多层感知机(Multi-Layer Perceptron)
MLP-based unprojection: A popular approach is to convert a vertical-axis strip of image features to a forward-axis strip of ground-plane features, with an MLP [4, 10, 25].
基于MLP的反投影:一个受欢迎的方法是将垂直轴的一条图像特征转换为地平面特征的一条前向轴,使用一个MLP[4, 10, 25]。
An important detail here is that the initial ground-plane features are considered aligned with the camera frustum, and they are therefore warped into a rectilinear space using the camera intrinsics.
这里的一个重要细节!!是,初始的地面特征被认为与摄像机的截头锥体对齐,因此它们使用摄像机的内部参数被扭曲到一个直线空间中。
Some works in this category use multiple MLPs, dedicated to different scales [26, 11], or to different categories [12].
这一类别中的一些工作使用多个MLP,专门用于不同的尺度[26, 11]或不同的类别[12]。
As this MLP is parameter-heavy, Yang et al. [27] propose a cycle-consistency loss (mapping backward to the image-plane features) to help regularize it.
由于这个MLP参数众多,Yang等人[27]提议使用一个循环一致性损失(映射回到图像平面特征)来帮助规范化它。
Geometry-aware transformer-like models
Geometry-aware transformer-like models: An exciting new trend is to transfer features using model components taken from transformer literature.
几何感知的Transformer模型:一个令人兴奋的新趋势是使用来自Transformer文献的模型组件来转移特征。
Saha et al. [13] begin by defining a relationship between each vertical scan-line of an image, and the ground-plane line that it projects to, and use self-attention to learn a “translation” function between the two coordinate systems.
Saha等人[13]首先定义了图像的每个垂直扫描线与其投影到的地面线之间的关系,并使用自注意力来学习两个坐标系之间的“转换”函数。
Defining this transformer at the line level provides inductive bias to the model, reusing the lifting method across all lines.
在线级别定义这个Transformer为模型提供了归纳偏差,重复使用在所有线上的提升方法。
BEVFormer [5], which is concurrent work, proposes to use deformable attention operations to collect image features for a pre-defined grid of 3D coordinates.
BEVFormer [5],一个并发的工作,提议使用可变形注意操作来收集为预定义的3D坐标网格的图像特征。
This is similar to the bilinear sampling operation in parameter-free unprojection, but with approximately 10× more samples, learnable offsets for the sampling coordinates, and a learnable kernel on their combination.
这与无参数反投影中的双线性采样操作类似,但有大约10倍的样本,可学习的采样坐标的偏移量,以及它们组合上的可学习的核心。
Radar
Radar: In the automotive industry, radar has been in use for several years already [14].
雷达:在汽车工业中,雷达已经使用了好几年[14]。
Since radar measurements provide position, velocity, and angular orientation, the data is typically used to detect obstacles (e.g., for emergency braking), and to estimate the velocity of moving objects (e.g., for cruise control).
由于雷达测量提供位置、速度和角度定位,这些数据通常用于检测障碍物(例如,应急制动)和估算移动物体的速度(例如,巡航控制)。
Radar is longer-range and less sensitive to weather effects than LiDAR, and substantially cheaper.
雷达的测量范围更远,对天气效应的敏感度低于LiDAR,并且价格大大便宜。
Unfortunately, the sparsity and noise inherent to radar make it a challenge to use [28, 29, 30, 29, 31].
不幸的是,雷达固有的稀疏性和噪声使其难以使用[28, 29, 30, 29, 31]。
Some early methods use radar for BEV semantic segmentation tasks much like in our work [28, 32, 29], but only in small datasets.
一些早期的方法使用雷达进行BEV语义分割任务,就像在我们的工作中[28, 32, 29],但只在小数据集中。
Recent work within the nuScenes benchmark [33] has reported the data too sparse to be useful, recommending instead higher-density radar data from alternate sensor setups [3, 10].
在nuScenes基准[33]的近期工作中,报告说数据过于稀疏,不太有用,建议使用来自备选传感器设置的高密度雷达数据[3, 10]。
Some recent works explore RGB-radar or RGB-Lidar fusion strategies [23, 30], but focus on detection and velocity estimation rather than BEV semantic labeling.
一些近期的工作探讨RGB-雷达或RGB-Lidar融合策略[23, 30],但重点是检测和速度估计,而不是BEV语义标签。
3. SIMPLE-BEV MODEL
In this section, we describe the architecture and training setup of a basic neural BEV mapping model, which we will modify in the experiments to study which factors matter most for performance.
在本节中,我们描述了一个基本的神经BEV映射模型的架构和训练设置,我们将在实验中对其进行修改,以研究对性能影响最大的因素。
A. Setup and overview
A. Setup and overview
我们的模型从摄像头、雷达,甚至是LiDAR中获取输入。我们假设数据在传感器之间同步。我们假设传感器的内参和相对位姿是已知的。
The model has a 3D metric span, and a 3D resolution. Following the baselines in this task, we set the left/right and forward/backward span to 100m × 100m, discretized at a resolution of 200×200. We set the up/down span to 10m, and discretize at a resolution of 8. This volume is centered and oriented according to a reference camera, which is typically the front camera. We denote the left-right axis with X, the up-down axis with Y , and the forward-backward axis with Z.
该模型具有3D度量跨度和3D分辨率。按照此任务中的基线,我们将左/右和前/后跨度设置为100m × 100m,以分辨率为200×200进行离散化。我们将上/下跨度设置为10m,并以分辨率8进行离散化。该体积以参考摄像头为中心并根据其定向,通常是前置摄像头。我们用X表示左右轴,用Y表示上下轴,用Z表示前后轴。
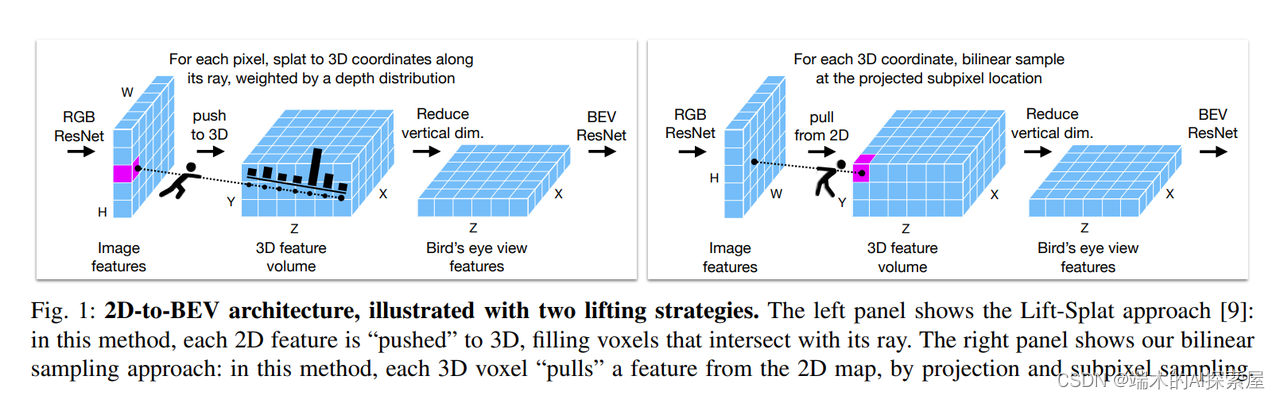
图 1:2D到BEV的架构,用两种提升策略进行说明。左侧面板展示了Lift-Splat方法[9]:在这个方法中,每个2D特征都被“推”到3D,填充与其光线相交的体素。右侧面板展示了我们的双线性采样方法:在此方法中,每个3D体素都从2D图中“拉取”一个特征,通过投影和亚像素采样。
LSS(Lift,Splat,Shoot)
- 推:站在Image图像的视角。将像素点推到BEV空间,叫做推(push)。
- 拉:站在BEV特征图的视角。将特征值从图像等信息上,查过来。叫做拉(pull)。
- 其中Image通常属于source,BEV通常是我们需要的结果
- 以上推拉两个视角,类似于写放射变换,你是从src–>output 还是 output --> src
Following related work, we first apply a 2D ResNet to compute features from each camera image, then lift to 3D, then reduce to a BEV plane, and finally apply a 2D ResNet in BEV to arrive at the output. These steps are illustrated in Figure 1, and will be described in more detail in the next section.
遵循相关工作,我们首先应用2D ResNet从每个摄像头图像中计算特征,然后提升到3D,然后减小到BEV平面,最后在BEV中应用2D ResNet以得到输出。这些步骤在图1中有图示,并将在下一节中更详细地描述。
Our lifting step is subtly different from prior work: while some works “splat” 2D features along their corresponding 3D rays [9, 21], we instead begin at 3D coordinates, and bilinearly sample a sub-pixel feature for each voxel. If radar or LiDAR is provided, we rasterize this data into a bird’s eye view image, and concatenate this with the 3D feature volume before compressing the vertical dimension.
我们的提升步骤与先前的工作略有不同:虽然有些工作在其对应的3D射线上“拍扁 栅格化”2D特征[9, 21],但我们相反地从3D坐标开始,并为每个体素双线性采样一个亚像素特征。如果提供了雷达或LiDAR,我们将这些数据栅格化成鸟瞰图像,并在在压缩垂直维度之前将其与3D特征体积连接。
B. Architecture design
B. Architecture design
B. 架构设计
We featurize each input RGB image, shaped 3 × H × W, with a ResNet-101 [34] backbone. We upsample the output of the last layer and concatenate it with the third layer output, and apply two convolution layers with instance normalization and ReLU activations [35], arriving at feature maps with shape C × H/8×W/8 (one eighth of the image resolution).
我们使用ResNet-101 [34]主干对每个输入的RGB图像(形状为3 × H × W)进行特征化。我们上采样最后一层的输出,并与第三层的输出进行连接,然后应用两个带实例归一化和ReLU激活的卷积层[35],得到形状为C × H/8×W/8的特征映射(图像分辨率的八分之一)。
We project the pre-defined volume of 3D coordinates into all feature maps, and bilinearly sample there, yielding a 3D feature volume from each camera. We compute a binary “valid” volume per camera at the same time, indicating if the 3D coordinate landed within the camera frustum. We then take a valid-weighted average across the set of volumes, reducing our representation down to a single 3D volume of features, shaped C ×Z ×Y ×X. We then rearrange the axes so that the vertical dimension extends the channel dimension, as in C × Z × Y × X → (C · Y ) × Z × X, yielding a high-dimensional BEV feature map.
我们将预定义的3D坐标体积投影到所有特征映射中,并在那里进行双线性采样,从每个摄像头得到一个3D特征体积。同时,我们为每台摄像机计算一个二进制的“有效”体积,以指示3D坐标是否落在摄像机的视锥内。然后我们对体积集合取一个有效加权平均值,将我们的表示缩减为一个形状为C ×Z ×Y ×X的3D特征体积。然后我们重新排列轴,使得垂直维度扩展通道维度,即C × Z × Y × X → (C · Y ) × Z × X,产生一个高维的BEV特征映射。
If radar is provided, we rasterize it to create another BEV feature map with the same spatial dimensions as the RGB-based map. We use an arbitrary number of radar channels R (including R = 0, meaning no radar). In nuScenes [33], each radar return consists of a total of 18 fields, with 5 of them being position and velocity, and the remainder being the result of built-in pre-processes (e.g., indicating confidence that the return is valid). We use all of this data, by using the position data to choose the nearest XZ position on the grid (if in bounds), and using the 15 non-position items as channels, yielding a BEV feature map shaped R×Z×X, with R = 15.
如果提供了雷达,我们将其光栅化以创建另一个与基于RGB的映射具有相同空间维度的BEV特征映射。我们使用任意数量的雷达通道R(其中R = 0表示没有雷达)。在nuScenes [33]中,每个雷达返回由总共18个字段组成,其中5个字段是位置和速度,其余的是内置预处理的结果(例如,表示返回是否有效的置信度)。我们使用所有这些数据,通过使用位置数据选择网格上的最近XZ位置(如果在界限内),并使用15个非位置项目作为通道,得到形状为R×Z×X的BEV特征映射,其中R = 15。
If LiDAR is provided, we voxelize it to a binary occupancy grid shaped Y ×Z ×X, and use it in place of radar features. We then concatenate the RGB features and radar/LiDAR features, and compress the extended channels down to a dimensionality of C, by applying a 3×3 convolution kernel. This achieves the reduction (C · Y + R) × Z × X → C ×Z ×X. At this point, we have a single plane of features, representing a bird’s eye view of the scene. We process this with three blocks of a ResNet-18 [34], producing three feature maps, then use additive skip connections with bilinear upsampling to gradually bring the coarser features to the input resolution, and finally, apply two convolution layers acting as the segmentation task head. Following FIERY [21], we complement the segmentation head with auxiliary task heads for predicting centerness and offset, which serve to regularize the model. The offset head produces a vector field where, within each object mask, each vector points to the center of that object. We train the segmentation head with a cross-entropy loss, and supervise the centerness and offset fields with an L1 loss. We use an uncertainty-based learnable weighting [36] to balance the three losses.
如果提供了LiDAR,我们将其体素化为一个形状为Y ×Z ×X的二进制占用网格,并用其替代雷达特征。然后我们连接RGB特征和雷达/LiDAR特征,并通过应用3×3卷积核将扩展的通道压缩到C的维度。这实现了(C · Y + R) × Z × X → C ×Z ×X的缩减。此时,我们有一个特征平面,代表着场景的鸟瞰图。我们使用ResNet-
18 [34]的三个块来处理这个特征图,生成三个特征映射,然后使用加性跳跃连接和双线性上采样逐渐将较粗的特征带到输入分辨率,并最后应用两个卷积层作为分割任务的头部。按照FIERY [21],我们使用预测中心性和偏移的辅助任务头部来补充分割头部,从而规范化模型。偏移头产生一个矢量场,在每个对象遮罩内,每个矢量都指向该对象的中心。我们使用交叉熵损失训练分割头,并使用L1损失监督中心性和偏移字段。我们使用基于不确定性的可学习加权[36]来平衡这三个损失。
The 3D resolution is 200 × 8 × 200, and our final output resolution is 200 × 200. Our 3D metric span is 100m × 10m × 100m. This corresponds to voxel lengths of 0.5m × 1.25m×0.5m (in Z, Y, X order). We use a feature dimension (i.e., channel dimension C) of 128. The ResNet-101 is pretrained for object detection [37] on COCO 2017 [38]. The BEV ResNet-18 is trained from scratch. We train end-to-end for 25,000 iterations, with the Adam-W optimizer [39] using a learning rate of 5e-4 and 1-cycle schedule [40].
3D分辨率为200 × 8 × 200,我们的最终输出分辨率为200 × 200。我们的3D度量范围是100m × 10m × 100m。这对应于0.5m × 1.25m×0.5m的体素长度(按Z, Y, X的顺序)。我们使用一个特征维度(即,通道维度C)为128。ResNet-101是预先训练用于在COCO 2017 [38]上的物体检测[37]。BEV ResNet-18是从零开始训练的。我们使用Adam-W优化器[39]进行端到端的训练,迭代25,000次,使用学习率为5e-4和1-cycle调度[40]。
C. Key factors of study
C. Key factors of study
C. 研究的关键因素
Lifting strategy
Lifting strategy: Our model is “simpler” than related work, particularly in the 2D-to-3D lifting step, which is handled by (parameter-free) bilinear sampling.
提升策略:我们的模型比相关工作“更简单”,尤其是在2D到3D的提升步骤中,这一步骤由(无参数的)双线性采样处理。
This replaces, for example, depth estimation followed by splatting [9], MLPs [4, 10, 25], or attention mechanisms [13, 5, 41].
例如,这取代了深度估计后的喷射[9]、MLP[4, 10, 25]或注意力机制[13, 5, 41]。
Our strategy can be understood as “Lift-Splat [9] without depth estimation”, but as illustrated in Figure 1, our implementation is different in a key detail: our method relies on sampling instead of splatting.
我们的策略可以理解为“没有深度估计的Lift-Splat [9]”,但如图1所示,我们的实现在一个关键细节上有所不同:我们的方法依赖于采样而不是喷射。
Our method begins with 3D coordinates of the voxels, and takes a bilinear sample for each one.
我们的方法从体素的3D坐标开始,并对每一个体素进行双线性采样。
As a result of the camera projection, close-up rows of voxels sample very sparsely from the image (i.e., more spread out), and far-away rows of voxels sample very densely (i.e., more packed together), but each voxel receives a feature.
由于相机的投影,靠近的体素行从图像中非常稀疏地采样(即,更分散),而远离的体素行非常密集地采样(即,更加紧密地结合在一起),但每个体素都接收到一个特征。
Splatting-based methods [9, 13] begin with a 2D grid of coordinates, and “shoot” each pixel along its ray, filling voxels intersected by that ray, at fixed depth intervals.
基于喷射的方法[9, 13]从一个2D坐标网格开始,并“射击”沿其射线的每个像素,在固定的深度间隔处填充由那个射线相交的体素。
As a result, splatting methods yield multiple samples for up-close voxels, and very few samples (sometimes zero) for far-away voxels.
因此,喷射方法为靠近的体素提供多个样本,而对远离的体素提供非常少的样本(有时为零)。
As we will show in experiments, this implementation detail has an impact on performance, such that splatting is slightly superior at short distances, and sampling is slightly superior at long distances.
正如我们将在实验中展示的,这种实现细节会影响性能,使得在短距离上喷射略微优越,而在长距离上采样略微优越。
In the experiments, we also evaluate a recently-proposed deformable attention strategy [5], which is similar to bilinear sampling but with learned sampling kernel for each voxel (i.e., learned weights and learned offsets).
在实验中,我们还评估了一个最近提出的可变形注意力策略[5],它类似于双线性采样,但对每个体素有学习过的采样核(即,学习过的权重和学习过的偏移)。
Input resolution
Input resolution: While early BEV methods downsampled the RGB substantially before feeding it through the model (e.g., downsampling to 128 × 352 [9]), we note that recent works have been downsampling less and less (e.g., most recently using the full resolution [13, 5]).
输入分辨率:早期的BEV方法在将RGB输入模型之前会大幅下采样(例如,将分辨率下采样到128 × 352 [9]),但我们注意到最近的研究在下采样方面越来越少(例如,最近使用完整分辨率 [13, 5])。
We believe this is an important factor for performance, and so we train and test our RGB-only model across different input resolutions. Across variants of our model, we try resolutions from 112 × 208 up to 896 × 1600.
我们认为这是性能的一个重要因素,因此我们在不同的输入分辨率下训练和测试我们的仅RGB模型。在我们模型的不同变体中,我们尝试从112 × 208到896 × 1600的分辨率。
Batch size
Batch size: Most of the related works on BEV segmentation use relatively small batch sizes in training (e.g., one [5] or four [9]). It has been reported in the image classification literature that higher batch sizes deliver superior results [42], but we have not seen batch size discussed as a performance factor in the BEV literature. This may be because of the high memory requirements of these BEV models: it is necessary to process all 6 camera images in parallel with a high-capacity module, and depending on implementation, it is sometimes necessary to store a 3D volume of features before reducing the representation to BEV. To overcome these memory issues, we accumulate gradients across multiple steps and multiple GPUs, and obtain arbitrarily-large effective batch sizes at the cost of slower wall-clock time per gradient step. For example, it takes us approximately 5 seconds to accumulate the forward and backward passes to create a batch size of 40, even using eight A100 GPUs in parallel. Overall, however, our training time is similar to prior work: our model converges in 1-3 days, depending on input resolution.
批处理大小:大多数与BEV分割相关的工作在训练中使用相对较小的批处理大小(例如,一个 [5] 或四个 [9])。在图像分类文献中已经报道过更大批处理大小可以获得更好的结果 [42],但我们在BEV文献中并没有看到批处理大小被讨论为性能因素。这可能是因为这些BEV模型具有较高的内存需求:需要使用高容量模块并行处理所有6个摄像头图像,根据具体实现,有时需要在将表示降低到BEV之前存储一定量的3D特征。为了解决这些内存问题,我们在多个步骤和多个GPU上累积梯度,并以较慢的每个梯度步骤的墙钟时间为代价获得任意大的有效批处理大小。例如,即使使用八个A100 GPU并行运行,我们累积正向和反向传递以创建一个批处理大小为40,大约需要5秒钟。然而,总体而言,我们的训练时间与先前的工作相似:我们的模型在1-3天内收敛,具体取决于输入分辨率。
Augmentations
Augmentations: Prior work recommends the use of camera dropout and various image-based augmentations, but we have not seen these factors quantified.
增强:以前的工作推荐使用摄像头掉线和各种基于图像的增强,但我们没有看到这些因素的量化。
We experiment with multiple augmentations at training time, and measure their independent effects: (1) we apply random resizing and cropping on the RGB input, in a scale range of [0.8, 1.2] (and update the intrinsics accordingly),
我们在训练时试验多种增强,并测量它们的独立效果:(1) 我们在[0.8, 1.2]的尺度范围内对RGB输入进行随机调整大小和裁剪(并相应地更新内参),
(2) we randomly select a camera to be the “reference” camera, which randomizes the orientation of the 3D volume (as well as the orientation of the rasterized annotations),
(2) 我们随机选择一个摄像头作为“参考”摄像头,这随机化了3D体积的方向(以及栅格化注释的方向),
and (3) we randomly drop one of the six cameras. At test time, we use the “front” camera as the reference camera, and do not crop.
并且 (3) 我们随机丢弃六个摄像头中的一个。在测试时,我们使用“前置”摄像头作为参考摄像头,不进行裁剪。
Radar usage details
Radar usage details: Prior work has reported that the radar data in nuScenes is too sparse to be useful [3, 10], but we hypothesize it can be a valuable source of metric information, lacking from current camera-only setups.
雷达使用细节:以前的工作报道称nuScenes中的雷达数据过于稀疏,无法使用 [3, 10],但我们假设它可以成为当前仅摄像头设置中所缺乏的有价值的度量信息来源。
Beyond simply using radar or not, our model is flexible in terms of (1) using the radar meta-data as additional channels, vs. treating the radar as a binary occupancy image,
除了简单地使用或不使用雷达,我们的模型在以下方面是灵活的:(1) 使用雷达元数据作为额外的通道,而不是将雷达视为二进制占用图像,
(2) using the raw data from the sensor, vs. using outlier-filtered input,
(2) 使用传感器的原始数据,而不是使用经过滤的异常值的输入,
and (3) using radar accumulated from a number of sweeps, vs. only using the time-synchronized data.
并且 (3) 使用从多次扫描中累积的雷达数据,而不仅仅是使用时间同步的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









