 ImVoteNet:融合图像投票提升点云3D检测
ImVoteNet:融合图像投票提升点云3D检测





 ImVoteNet是一种融合2D图像和3D点云的3D物体检测方法,通过结合图像投票和点云投票提升检测性能。该方法利用2D检测器的几何、语义和纹理信息,将2D特征提升至3D空间,同时通过多塔网络结构进行特征融合,以避免单源信息主导。实验表明,ImVoteNet在SUN RGB-D数据集上达到了SOTA,尤其在处理遮挡和稀疏点云时表现优秀。
ImVoteNet是一种融合2D图像和3D点云的3D物体检测方法,通过结合图像投票和点云投票提升检测性能。该方法利用2D检测器的几何、语义和纹理信息,将2D特征提升至3D空间,同时通过多塔网络结构进行特征融合,以避免单源信息主导。实验表明,ImVoteNet在SUN RGB-D数据集上达到了SOTA,尤其在处理遮挡和稀疏点云时表现优秀。
本文同步于微信公众号:3D视觉前沿,欢迎大家关注。

1. 摘要
这篇文章的第一作者是Charles R. Qi,同时也是PointNet,PointNet++,Frustum PointNets和VoteNet的一作,代码目前没有开源。之前进行室内3D检测的SOTA算法VoteNet只使用了point cloud,而point cloud具有以下劣势,点云稀疏,缺少颜色信息,而且数据包含传感器噪声。相对而言,images具有更高的分辨率以及丰富的纹理信息,因此图像可以辅助点云进行3D detection,难点在于如何有效结合。这篇论文基于VoteNet框架,提出了一个专门针对RGB-D场景的3D检测算法框架ImVoteNet,融合了image上的2D Votes和point cloud的3D Votes。和之前进行多模态检测的工作相比,该论文显式地从2D image中提取几何和语义特征,并结合相机内参将这些特征提升至3D空间。为了提高2D-3D特征融合效果,作者还提出了一个multi-tower训练框架。ImVoteNet在SUN RGB-D数据集上达到了SOTA,比之前SOTA的VoteNet又提高了5.7mAP。
2. 简介
19年提出的VoteNet在室内3D检测任务上达到了SOTA,但这是否到极限了呢,是否存在一种有效方式结合RGB image来提升效果?通过分析point cloud和image数据,可以看出RGB image和point cloud之间存在互补关系,因此可以肯定image能够辅助point cloud带来效果提升。RGB image相比与depth image或者Lidar data具有更高的分辨率,包含丰富的纹理信息,而且images可以覆盖blind regions,这些区域由于反光等原因无法由depth sensors获取数据;另一方面,images缺乏绝对深度和尺度,而这些由point cloud可以提供。
如何结合image和point cloud是关键。一种直观的方式是将原始RGB值附加到点云上,通过投影可以得到point-pixel的一一对应。然而,由于3D点太稀疏了,这样做会丢失image空间的稠密特性。基于此,涌现了一些较为高级的方式来融合2D和3D数据。一类方法借助成熟的2D detectors来提供frustum point clouds,能够极大减少进行3D包围盒估计的3D检索空间。然而这种层叠式设计给出的初始proposals没有考虑3D信息,如果2D detectors检测不出物体,那么不会进行后续的3D detection。另外一类方法采用3D为主的方式,将从2D images中抽取的ConvNet特征concatenate到3D voxels或者points上,之后再生成候选以及回归3d bboxes。然而,这类方法没有直接基于2D image进行定位,不能为3D detection提供有效的guidance。
3. 方法概述
该论文提出了ImVoteNet,基于VoteNet使用一种联合的2D-3D投票框架进行3D检测。算法利用了成熟的2D detectors,也保留了从完整的点云进行推断物体的能力,并且是避免了各自的缺陷。
设计算法时主要考虑的是如何有效利用2D image中的几何、语义及颜色信息。其中,几何信息:给定2D BBox,可以获取2D votes,如图1,也即从当前像素指向物体中心像素,之后结合相机内参和像素的深度值,将2D votes提升到3D,产生伪3D Votes,进而附加到3D点上进行生成后续的proposals;语义信息:one-hot向量给出物体类别;颜色信息:三维的RGB信息。这些从images获取到的所有features,将会concatenate到由pointnet++获得的3D seed point featurs上。

图1:使用室内场景的image和point cloud共同进行投票。2D vote将物体3D中心的搜索空间简化为一条射线。
基于联合后的features,仿照VoteNet框架生成3D Hough Votes,再生成最后的3D bboxes。由于seed features包含了2D和3D信息,因此在本质上携带了更多的信息来回归遮挡或者点数目少的物体,而且在处理几何近似物体时更为有效。
另外,作者还发现,进行融合2D和3D信息时,必须很小心地平衡两者,以避免单源信息占主导。因此作者引入了一个使用梯度混合的multi-towered网络结构,确保能够最大化地利用2D和3Dfeatures。在测试时,只有主要的tower作用于联合的2D-3D特征,能够最小化在效率上的牺牲。
算法的整体流程如图2所示:
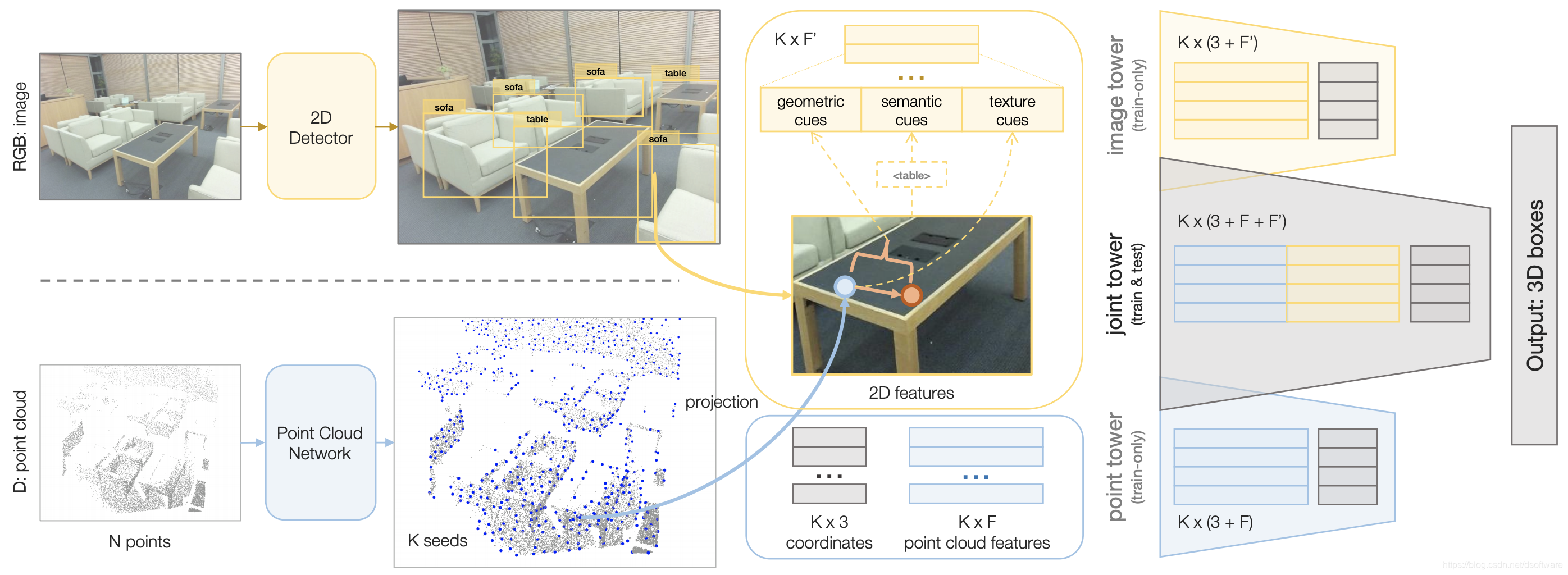
图2:ImVoteNet算法的3D检测流程。给定RGB-D输入,算法包含两个分支,一个分支进行2D detection,一个分支进行point cloud的feature抽取。之后,将image中抽取的geometric,semantic以及texture cues提升到3D,附
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









