一、基本流程
- 浏览器解析HTML、CSS、JS并最终在屏幕上渲染出实际像素所经历的全部过程,称为关键路径渲染。主要过程为:
- 浏览器获取HTML构建DOM,获取CSS构建CSSOM,结合DOM和CSSOM构建render树,通过布局计算出节点在屏幕上的具体物理位置,最后调用硬件API绘制像素。
- 如果在构建DOM时遇到了JS,会阻塞DOM的构建,甚至会导致CSSOM的构建对DOM的构建造成阻塞。
- 总结:
- 关键路径渲染共分为5个步骤:
- 构建DOM、构建CSSOM、构建渲染树、布局、绘制。
- 通常情况下,DOM和CSSOM是并行处构建的。但是当浏览器遇到一个script标签时,DOM构建将被暂停,直到脚本完成。如果脚本中涉及了对CSS的更改,则JS需要等待CSSOM构建完成才能继续执行。
1.1 构建DOM
- DOM:document object model,文档对象模型。
- 浏览器处理HTML构建DOM的步骤可以分为:
- Btyes -> Characters -> Tokens -> Nodes -> DOM
- 第一步:转化,把原始的编码转化为字符
- 浏览器从磁盘或网络中读取HTML原始的字节,并根据文件的编码(如UTF-8)转化成字符。
- 第二步:Token化,将字符串转化为Token。
- Token中会标识出当前标签的相关信息,如是开始标签、结束标签等。这些标识用于记录节点间的父子关系等。
![[Image]](https://i-blog.csdnimg.cn/blog_migrate/ec07d1860b125d8dacdac5d8733e2e6e.png)
- 第三步:生成节点并构建DOM。
- 构建DOM的构建,是伴随的Token的生成同时进行的。每生成一个Token,如果是非结束标签,会立即消耗该Token生成相应的Node节点,该节点对象中包含了标签中所有的属性。
- 随后通过开始节点和结束节点之间标识的节点间关系,可以构建出DOM树。
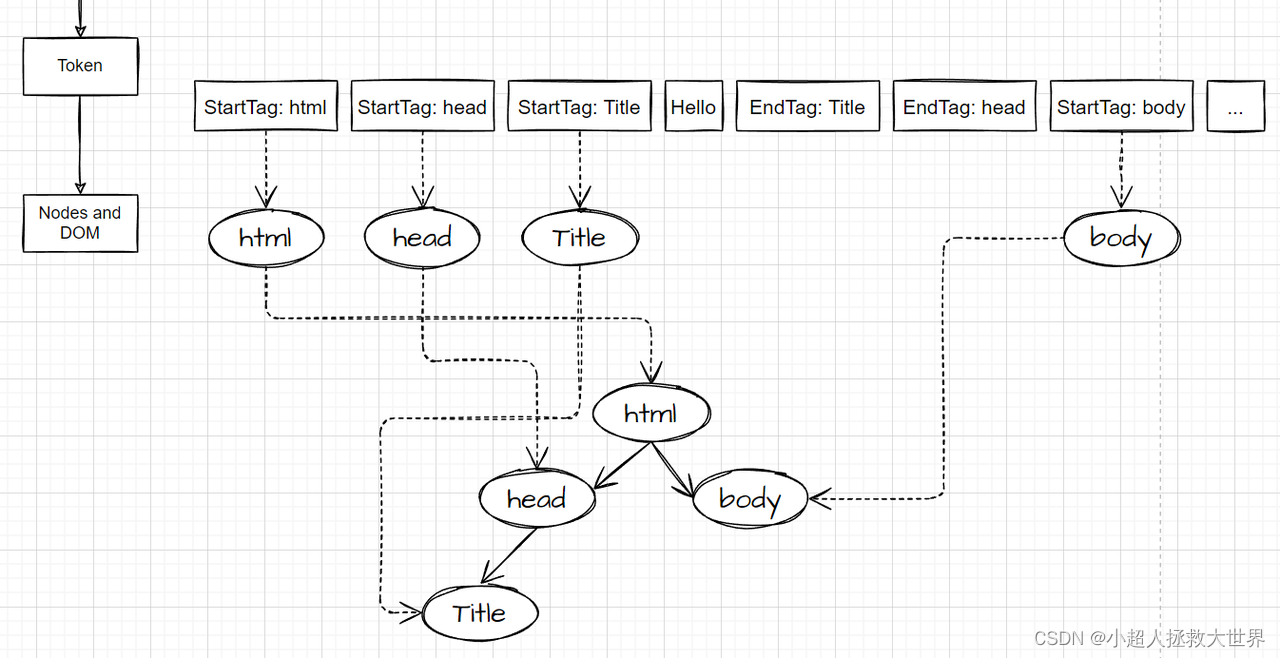
- 每生成一个Token,就立即消耗该Token
- 如果是开始标签,就创建一个Node节点
- 如果该开始标签前一个token也是开始标签,该节点就是前节点的子节点,通过这个构建树形结构,将其关联到前一个节点上。
- 直到所有的Token被消耗完,该DOM也构建完成。
1.2 构建CSSOM
1.3 构建渲染树
- 渲染树的作用在于只捕获可见内容,其构建需要做以下工作:
- 从DOM树根节点开始遍历每一个可见节点:
- 对于最终不会出现在渲染输出的节点,如脚本节点(script)、元节点(meta、title)等,将被忽略;
- 对于不可见的节点,如设置了display: none,将被忽略。
- 找到该可见节点的CSSOM规则,并应用。
1.4 布局
- 在该阶段,浏览器要计算各个节点在页面中的确切位置和大小。
- 布局流程输出的是一个盒模型,它会精确地捕捉所有元素在视口内的确切位置和尺寸,所有的相对测量量都将被转换为屏幕上的绝对像素。
1.5 绘制
- 布局完成之后,浏览器会立即发出’Paint Setup’和’Paint’事件,将渲染树转化为屏幕上的像素。
1.6 JS的影响
- JS的加载、解析和执行都会阻塞DOM的构建。
- 在构建DOM时,如果HTML解析器遇到了JS,会暂停构建DOM,将控制权转移给JS引擎。等到JS执行完成后,浏览器再从中断的地方恢复构建DOM。
- JS同时也能导致CSSOM阻塞DOM的构建,因为JS也能修改CSS样式。
- 之前说过,不完整的CSS是无法使用的,所以必须要等到CSSOM完整构建后,才能进行下一步操作。
- 如果JS要访问CSSOM并修改它,就必须等到CSSOM构建完成。如果此时浏览器尚未完成CSS的下载和CSSOM的构建,浏览器将延迟脚本的执行和DOM的构建。
- 综上,浏览器会先构建CSSOM,然后运行脚本,最后恢复DOM构建。
二、回流和重绘
2.1 回流
- 回流:当对DOM的修改引发了DOM几何尺寸的变化,包括元素的宽高、隐藏元素等,导致浏览器需要重新计算元素的几何属性,并根据计算结果进行绘制的过程。
- 回流需要更新render树,代价是高昂的,会破坏用户体验。应该尽可能的减少触发回流的次数。
- 常见引起回流的操作:
- 添加或删除可见的DOM元素。
- 元素尺寸的变化:width/height、padding、border、margin。
- 浏览器窗口的改变:resize事件
- 计算offsetWidth和offsetHeight属性。
2.2 重绘
- 重绘:对DOM的修改只导致了样式的变化而没有影响几何属性,例如修改了颜色等,浏览器不需要重新计算元素的几何属性,而是直接为元素绘制新的样式的过程。
- 综上:回流一定引发重绘,重绘不一定导致回流。
三、补充
3.1 元节点meta
- meta元素以 name/content的方式定义源数据类型。
<head>
<meta name="author" content="wangyufei"></meta>
<meta name="dectrip" content="A simple example."></meta>
</head>
| name取值 | 作用 |
|---|
| application name | 当前页面所属Web应用的名称 |
| author | 当前页的作者 |
| description | 当前页面的描述 |
| generator | 生成HTML的软件名 |
| keywords | 用逗号分隔的字符串,用于描述内容 |
<head>
<meta charset="utf-8"></meta>
</head>
| 字符编码 | 说明 |
|---|
| ASCII | 第一个字符编码标准,定义了127个字母数字字符。 |
| ANSI | 原始windows字符集,支持256种不同的字符代码。 |
| ISO-8859-1 | HTML4默认字符集,支持256种不同字符代码。 |
| utf-8 | HTML5默认编码,涵盖几乎所有字符符号。 |
- meta通过http-equiv属性,模拟或替换http某一个头。
- 使用http-equiv属性指定要模拟的头,使用content提供要使用的值。
- 以下代码表示,5s后加载demo的url。如果没有之后的url,表示重新加载当前页。
<head>
<meta http-equiv="refresh" content="5; https://demo.com"></meta>
</head>
| http-equiv取值 | 说明 |
|---|
| refresh | 设置一个周期(单位s),之后,将从服务器重新加载当前页,或加载指定的url。 |
| default-style | 设置应用此页面的首选样式表。 |
| content-type | 指定HTML页面的字符编码。 |
3.2 CSS盒模型
- css中,每一个元素都由一个盒子所包裹,盒模型定义了盒子的各个部分,包括:content、padding、border、margin。
- 有2种盒模型,标准盒模型和IE盒模型,二者的区别在于:width/height属性值,等于标准盒模型content,IE盒模型content、padding、boder的和。
- 通过box-sizing属性可以指定:
- 标准盒模型:content-box
- IE盒模型:border-box
3.3 JS对DOM的操作
3.3.1 节点查找
| API | 说明 |
|---|
| document.getElementById | 根据id查找元素,大小写敏感。
如果有多个,只返回第一个。 |
| document.getElementsByClassName | 根据类名查找,多个类名使用逗号分隔。
返回HTMLCollection。 |
| document.getElementsByTagName | 根据标签查找元素。
*表示查询所有标签。
返回HTMLCollection。 |
| document.getElementsByName | |
| 根据元素的name属性查找,返回NodeList。 | |
| document.querySelector | 返回单个且第一个Node。 |
| document.querySelectorAll | 返回NodeList。 |
| document.forms | 获取当前页所有的form,返回HTMLCollections。 |
3.3.2 节点创建
| API | 说明 |
|---|
| document.createElement | 创建元素,并未添加到HTML文档中。 |
| node.cloneNode(true/false) | 克隆一个节点。
克隆节点不会克隆事件。 |
3.3.3 节点修改
| API | 说明 |
|---|
parent.appendChild(child)
parent.insertBefore(newNode, oldNode) | 添加 |
| parent.removeChild(node) | 移除节点并返回。 |
| parent.replaceChild(newNode, oldNode) | 替换 |
3.3.4 节点关系
| 属性 | 说明 |
|---|
| parentNode | 元素的父节点,可以是Element、Document、DocumentFragment。 |
| parentElement | 父元素必须是一个Element元素 |
| children | 返回实时的HTMLCollection,子节点都是Element |
| childNodes | 返回实时的NodeList,表四元素的子节点列表,子节点可能包含文本节点、注释节点等。 |
| firstChild / lastChild | |
| previousSibling / nextSibling | 节点的前一个节点 / 后一个节点 |
3.3.5 元素属性
| API | 说明 |
|---|
| element.setAttribute(name, value) | 设置属性 |
| element.getAttribute(name) | |
| element.hasAttribute(name) | |
3.3.6 样式相关
element.style.color = 'red';
element.style.setProperty('font-size', '18px');
element.style.removeProperty('color');
div.classList.remove('class1');
div.classList.add('class2');
div.classList.toggle('class3');
div.classList.replace('class2', 'class4');
window.getComputedStyle(element)
element.getBoundingClientRect();
3.4 NodeList vs HTMLCollection
- NodeList是一个静态的集合,其不受DOM树元素变化的影响,即后续节点的删减,NodeList察觉不到。
- HTMLCollection是动态绑定的,DOM树发生变化,HTMLCollection也会随之变化。
- 只有NodeList中的包含属性节点和文本节点。
- HTMLCollection可以通过name、id、index来获取;NodeList只能通过index来获取。
- HTMLCollection和NodeList本身无法使用数组方法,例如join()、pop()等,除非转化为数组。
const nodeList = document.querySelectorAll('div');
Array.from(nodeList);
Array.apply(null, nodeList);
Array.bind(null, nodeList)();
const nodeList = [...document.querySelectorAll('div')];




 文章详细阐述了浏览器从构建DOM和CSSOM,到生成渲染树、布局和绘制的全过程,强调了JS如何阻塞DOM构建以及回流和重绘的概念,讨论了CSSOM构建对首屏渲染速度的影响,并提供了关于DOM操作和CSS样式的API示例。
文章详细阐述了浏览器从构建DOM和CSSOM,到生成渲染树、布局和绘制的全过程,强调了JS如何阻塞DOM构建以及回流和重绘的概念,讨论了CSSOM构建对首屏渲染速度的影响,并提供了关于DOM操作和CSS样式的API示例。
![[Image]](https://i-blog.csdnimg.cn/blog_migrate/fce0853bbab6fa84675f96299b203eae.png)

















 1570
1570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









