






 本文介绍了深度学习中的多种优化算法,包括一阶优化方法如梯度下降及其变种SGDM、NAG等,以及二阶优化方法如AdaGrad、RMSProp、Adam等,并对比了它们在实际应用中的效果。
本文介绍了深度学习中的多种优化算法,包括一阶优化方法如梯度下降及其变种SGDM、NAG等,以及二阶优化方法如AdaGrad、RMSProp、Adam等,并对比了它们在实际应用中的效果。
文章列表
1.深度学习基础模型算法原理及编程实现–01.感知机.
2.深度学习基础模型算法原理及编程实现–02.线性单元 .
3.深度学习基础模型算法原理及编程实现–03.全链接 .
4.深度学习基础模型算法原理及编程实现–04.改进神经网络的方法 .
5.深度学习基础模型算法原理及编程实现–05.卷积神经网络.
6.深度学习基础模型算法原理及编程实现–06.循环神经网络.
9.深度学习基础模型算法原理及编程实现–09.自编码网络.
10.深度学习基础模型算法原理及编程实现–10.优化方法:从梯度下降到NAdam.
11.深度学习基础模型算法原理及编程实现–11.构建简化版的tensorflow—MiniFlow【实现MLP对MNIST数据分类】.
…
[TOC]
深度学习基础模型算法原理及编程实现–10.优化方法:从梯度下降到NAdam
优化算法的出现顺序从前往后依次为:SGD、SGDM、NAG、AdaGrad、AdaDelta、Adam、Nadam,这些优化算法的演变其实都来自一个模型,其演化路径如下图所示:
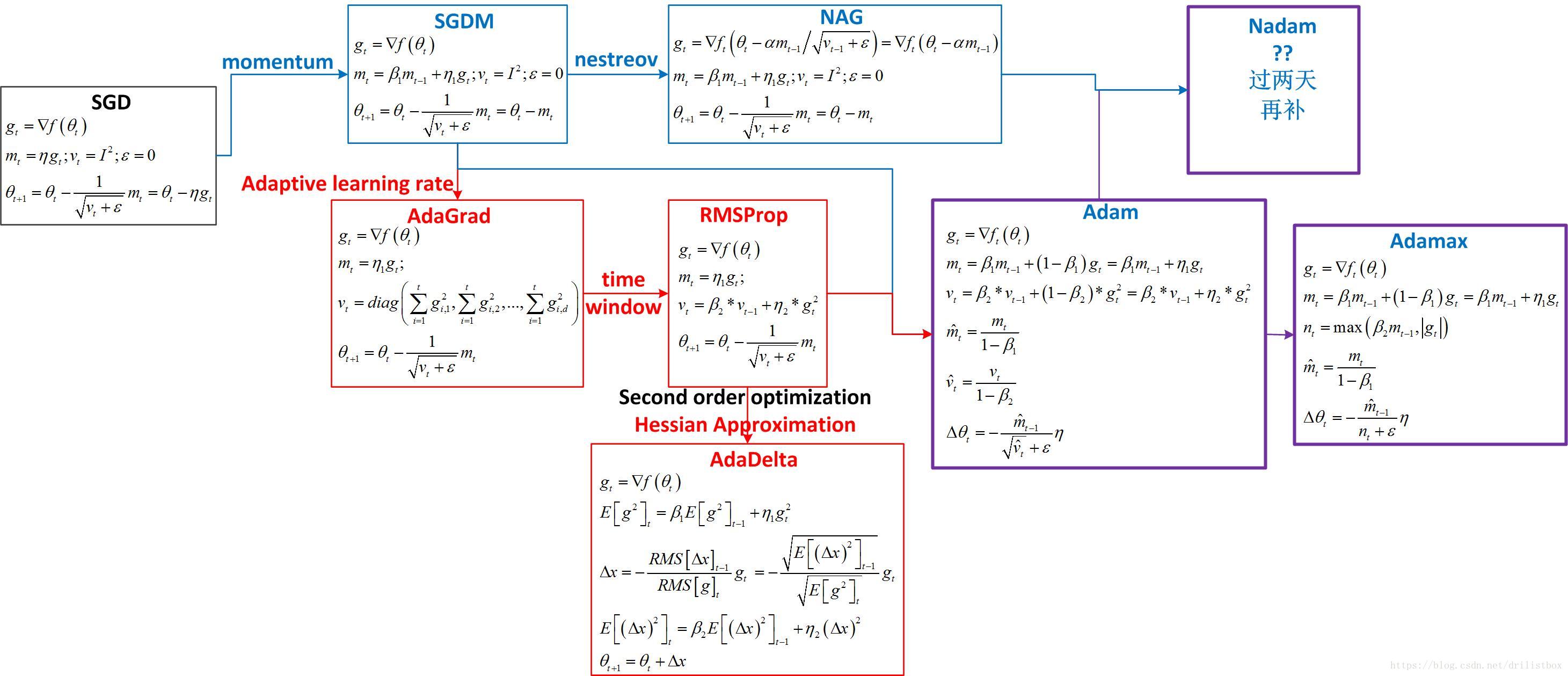
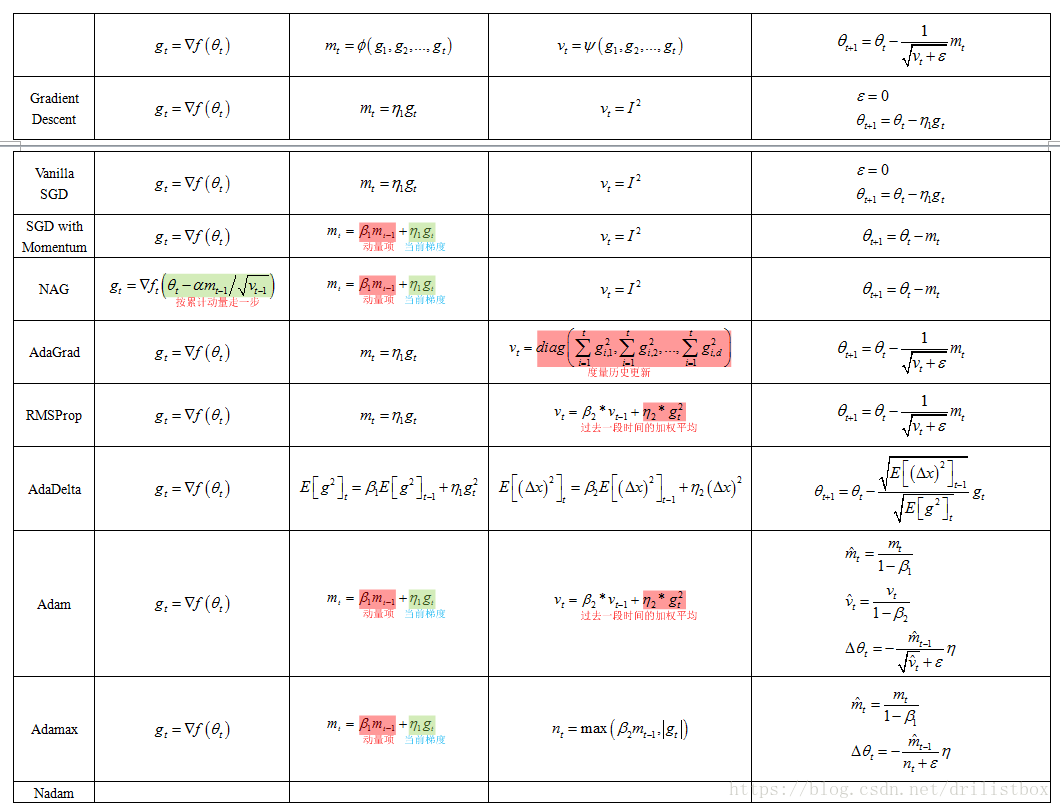
1 一阶优化方法(梯度下降)

1.1 Jacobi矩阵的性质
Jacobi矩阵给出了优化问题中当前点的最优线性逼近。需要注意的是许多神经网络的jacobi矩阵总是秩亏损的,这导致反向传播算法仅仅得到搜寻方向上的部分信息,从而导致训练时间过长。比如,如果jacobi矩阵是diag([1,0,1,0,0,1,0,1]),那么仅在对角线值元素值为1的维度所对应的参数有更新,对角线元素值为0的维度更新为0。
1.2 Gradient Descent

1.3 Noisy gradient descent

1.4 Vanilla SGD

1.5 SGD with Momentum(缩写SGDM)

1.6 NAG(Nesterov Accelerated Gradient)

2 学习率退火
如果学习率过高,参数更新量过大,参数就会无规律地跳动,不能够稳定到损失函数更深更窄的凹点中去。如果慢慢减小它,可能在前期的很长时间内看参数无规律的跳动。如果快速减小它,参数更新量可能下降过快,使得学习速度变慢甚至趋于0。常用的学习率退火有3种方式:
2.1 随步数衰减
特定周期个数后就降低学习率。比如每过5或10个周期就将学习率减少一半或更多。或者用固定的学习率来进行训练,每当验证集错误率停止下降,就以一定的系数来降低学习率。
2.2 指数衰减
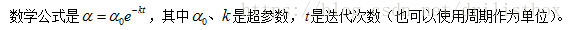
2.3 1/t衰减

3 二阶优化方法(牛顿法,又是一阶求跟方法)
一阶方法只使用梯度和函数评估去优化目标。二阶方法比如牛顿方法或者逆牛顿方法使用海塞矩阵或近似。尽管这为优化提供了额外的曲率信息,但精确计算二阶信息还是比较困难的。
3.1 牛顿法原理
3.1.1 牛顿法是一阶求跟方法

3.1.2 牛顿法是二阶优化方法
3.1.2.1 二阶泰勒分解求解

3.1.2.2 用求f’(x)=0根的方法来求解

3.1.3 海塞矩阵的性质
从式(1.9)可以发现,由于Hessian矩阵描述了损失函数的局部曲率,通过乘以Hessian矩阵的逆矩阵,可以在曲率小的时候大步前进,在曲率大的时候小步前进,从而使得参数更高效的更新。
此外,导数为0的点称为稳定点(Stationary points)。稳定点可以是(局部)最小值、(局部)最大值及鞍点。可通过计算Hessian矩阵H来进行判别:
(1)非退化的情况
若H负定(所有特征值都是负的),这是(局部)最大值.
若H正定(所有特征值都是正的),这是(局部)最小值.
若H特征值既有正的,又有负的,那该点是鞍点。(有些方向函数值上升,有些方向函数值下降)。
种非退化的情况下面,我们考虑一个重要的类别,即strict saddle函数.这种函数有这样的特点:对于每个点x
要么x的导数比较大
要么x的Hessian矩阵包含一个负的特征值
要么x已经离某一个(局部)最小值很近了
为什么我们要x满足这三个情况的至少一个呢?因为
(2)退化的情况
H特征值含0的情况。此时无法判断稳定点的类别,需参照更高维的导数。
3.1.4 海塞矩阵近似计算
3.1.4.1 对角线近似逆矩阵

3.1.4.2 Adadelta中的近似方法
3.1.4.2.1 时间加权

3.1.4.2.2 利用二阶优化方法的量纲是正确的

3.1.4.2.3 近似Hessian方法

3.2 AdaGrad

3.3 RMSProp

3.4 AdaDelta

3.5 Adam

3.6 Adamax
3.7 Nadam
4 不同优化方法结果比对
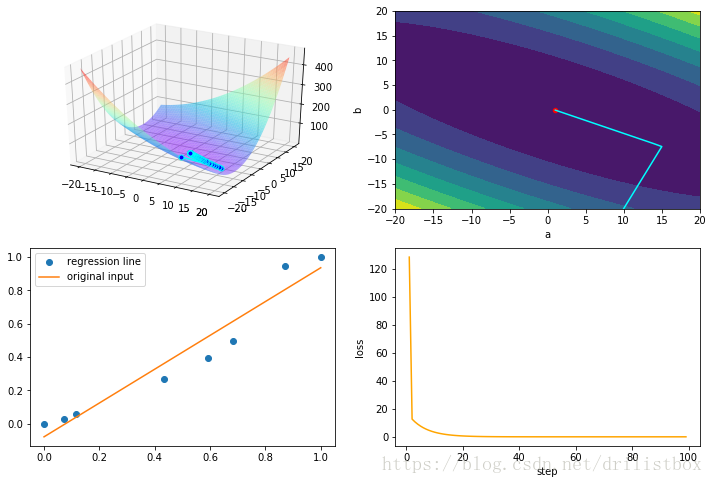
4.1 GD
eta1 = 0.1
step: 100 loss: 0.0044979134602375365
4.2 Vanilla SGD
eta1 = 0.1
step: 400 loss: 0.001108528235755615
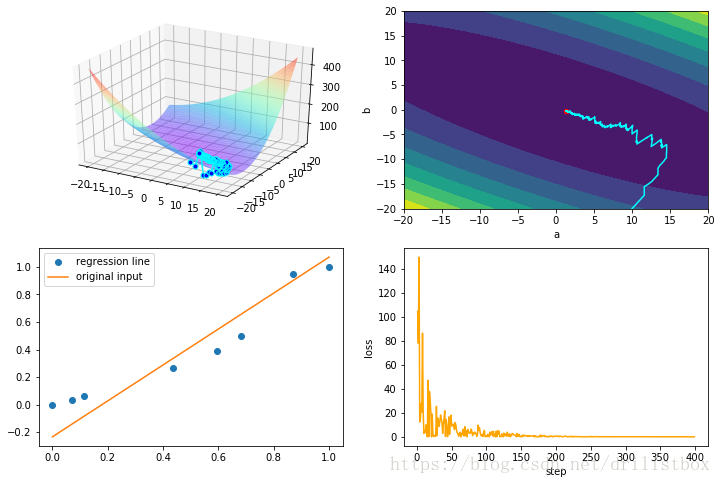
4.3 Mini_batch SGD
eta1 = 0.1
step: 500 loss: 0.0062751857700584805
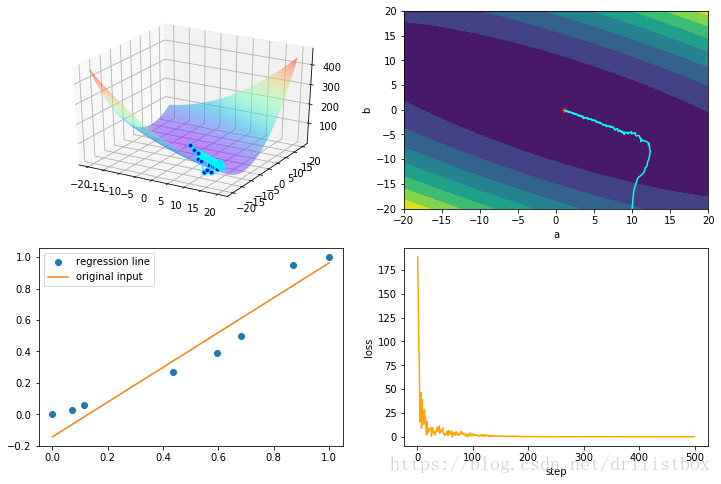
4.4 SGDM
eta1 = 0.1
beta1 = 1 - eta1
step: 400 loss: 0.005477318943045696
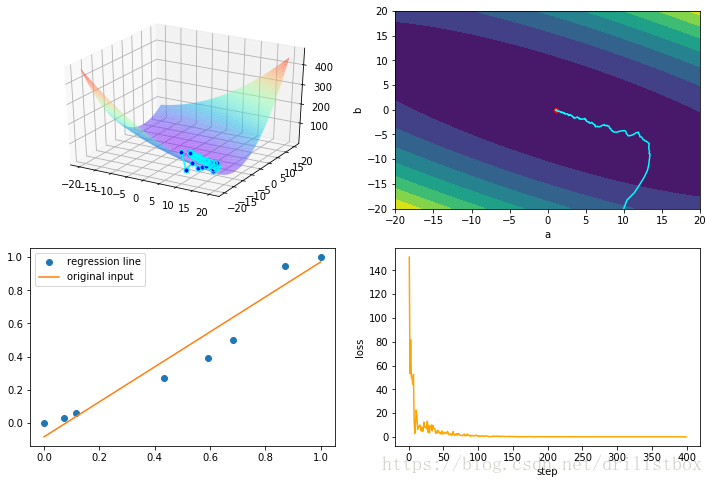
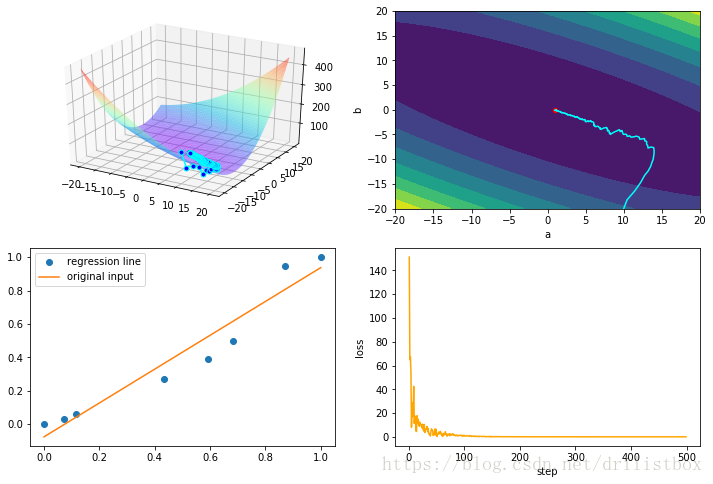
4.5 NAG
alpha = 0.05 #Nestreov项一步向前学习率
eta1 = 0.1
beta1 = 1 - eta1
step: 500 loss: 0.0027062579259504315
4.6 Adagrad
eta1 = 0.1
step: 2600 loss: 26.2471475715
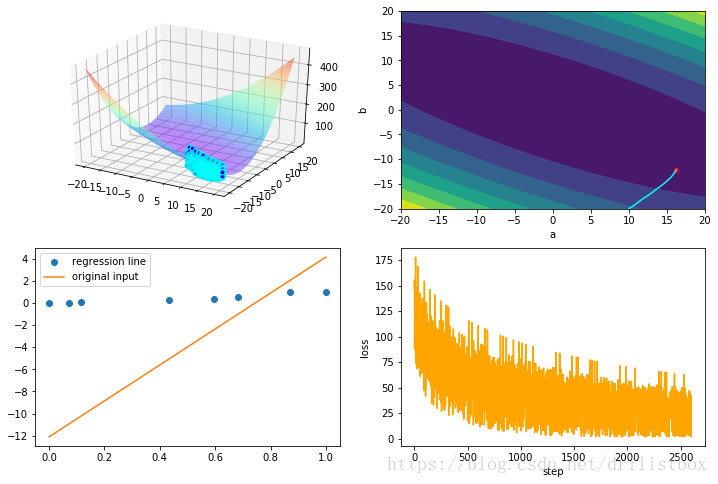
4.7 RMSProp
eta1 = 0.1
eta2 = 0.1
beta2 = 1 - eta2
step: 500 loss: 0.00855535079012
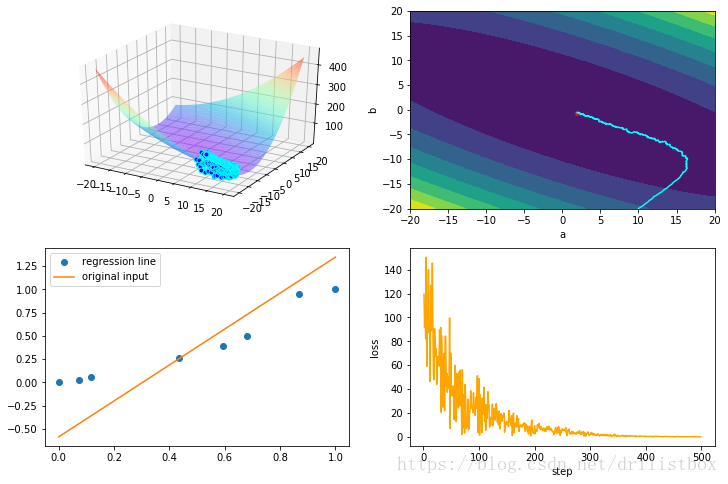
4.8 Adadelta
eta1 = 0.1
beta1 = 1 - eta1
eta2 = 0.1
beta2 = 1 - eta2
step: 100 loss: 0.0170838268612
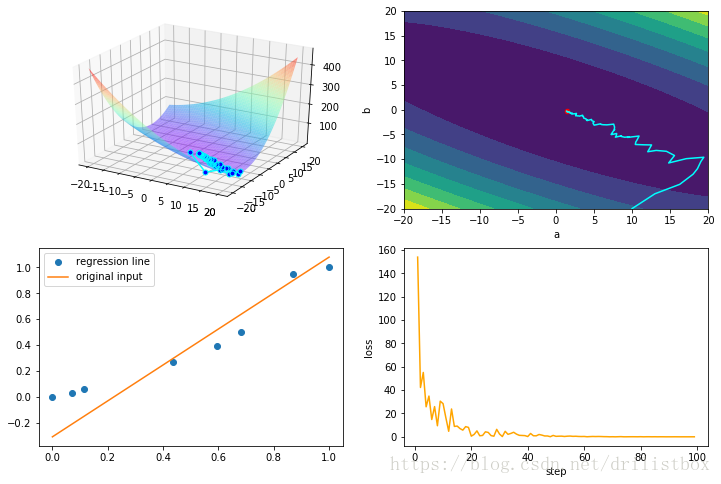
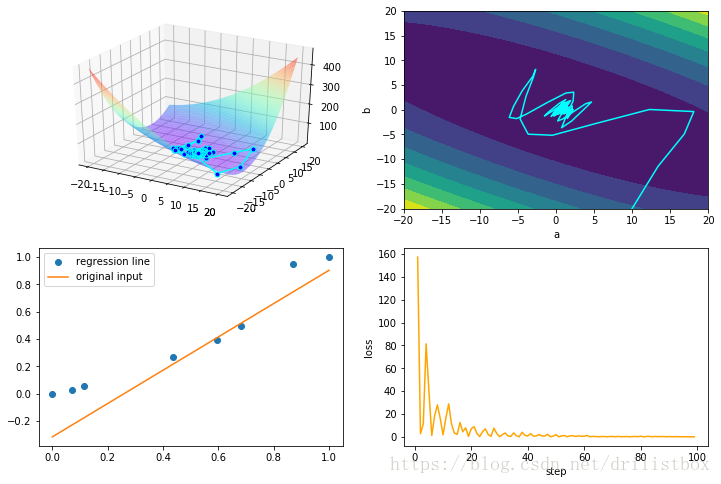
4.9 Adam
eta1 = 0.1
beta1 = 1 - eta1
eta2 = 0.1
beta2 = 1 - eta2
step: 100 loss: 0.0170408324886
5 编程实现
python版本:https://pan.baidu.com/s/1qZLJ7Gg

















 628
628





 到【灌水乐园】发言
到【灌水乐园】发言







