




 这篇博客总结了深度学习领域的多个重要模型,包括GPT系列(GPT1到GPT3,以及instructGPT),多模态研究中的visualBERT、Unicoder-VL、UNITER和ViLT,以及DeBERTa的改进。此外,还介绍了SSL方法、MMOE、无模板提示微调用于NER,以及多任务学习和半监督学习的概述。内容涵盖模型结构、预训练任务和多模态交互。
这篇博客总结了深度学习领域的多个重要模型,包括GPT系列(GPT1到GPT3,以及instructGPT),多模态研究中的visualBERT、Unicoder-VL、UNITER和ViLT,以及DeBERTa的改进。此外,还介绍了SSL方法、MMOE、无模板提示微调用于NER,以及多任务学习和半监督学习的概述。内容涵盖模型结构、预训练任务和多模态交互。
11,GPT
1,GPT1
Improving Language Understanding by Generative Pre-Training
finetune:
L ( C ) = L 2 ( C ) + λ L 1 ( C ) L(C) = L_2(C)+\lambda L_1(C) L(C)=L2(C)+λL1(C)
L 1 ( C ) = ∑ x ∑ i P ( x i ∣ x 1 , x 2 , ⋯ , x i − 1 ) L_1(C)=\sum_x\sum_iP(x_i|x_1,x_2,\cdots,x_{i-1}) L1(C)=∑x∑iP(xi∣x1,x2,⋯,xi−1)
L 2 ( C ) = ∑ x P ( y ∣ x ) L_2(C)=\sum_xP(y|x) L2(C)=∑xP(y∣x)

2,GPT2
Language Models are Unsupervised Multitask Learners
继续finetune,但是变成seq2seq的形式,如:“translate to french, english text, french text”
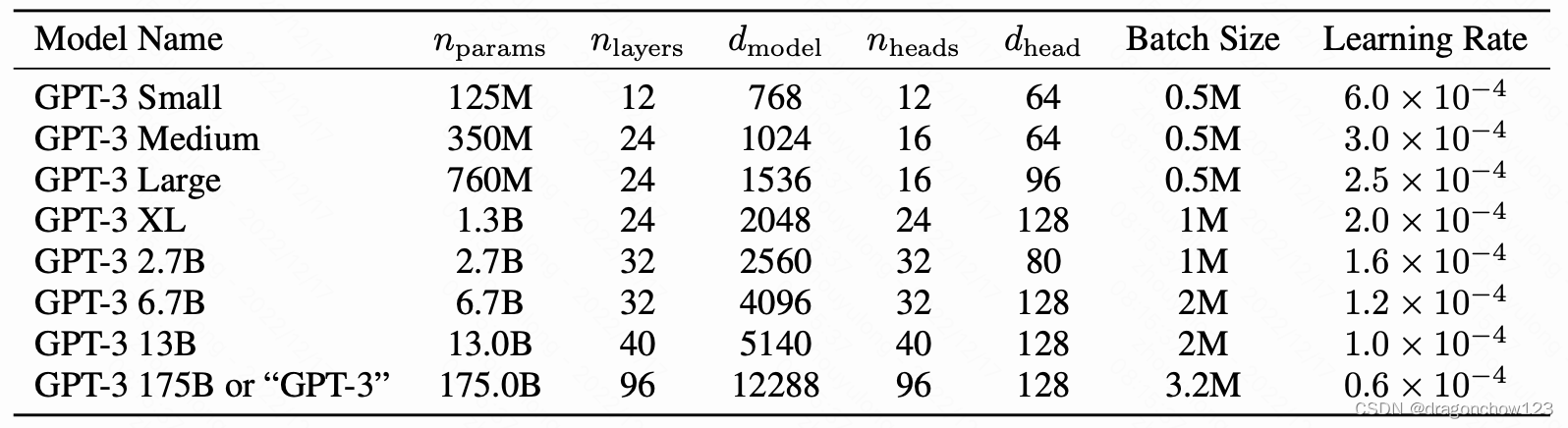
model size:117M, 345M, 762M, 1542M
3,GPT3
Language Models are Few-Shot Learners
follow GPT2,但不做finetune,做zero-shot和few-shot


4,instructGPT
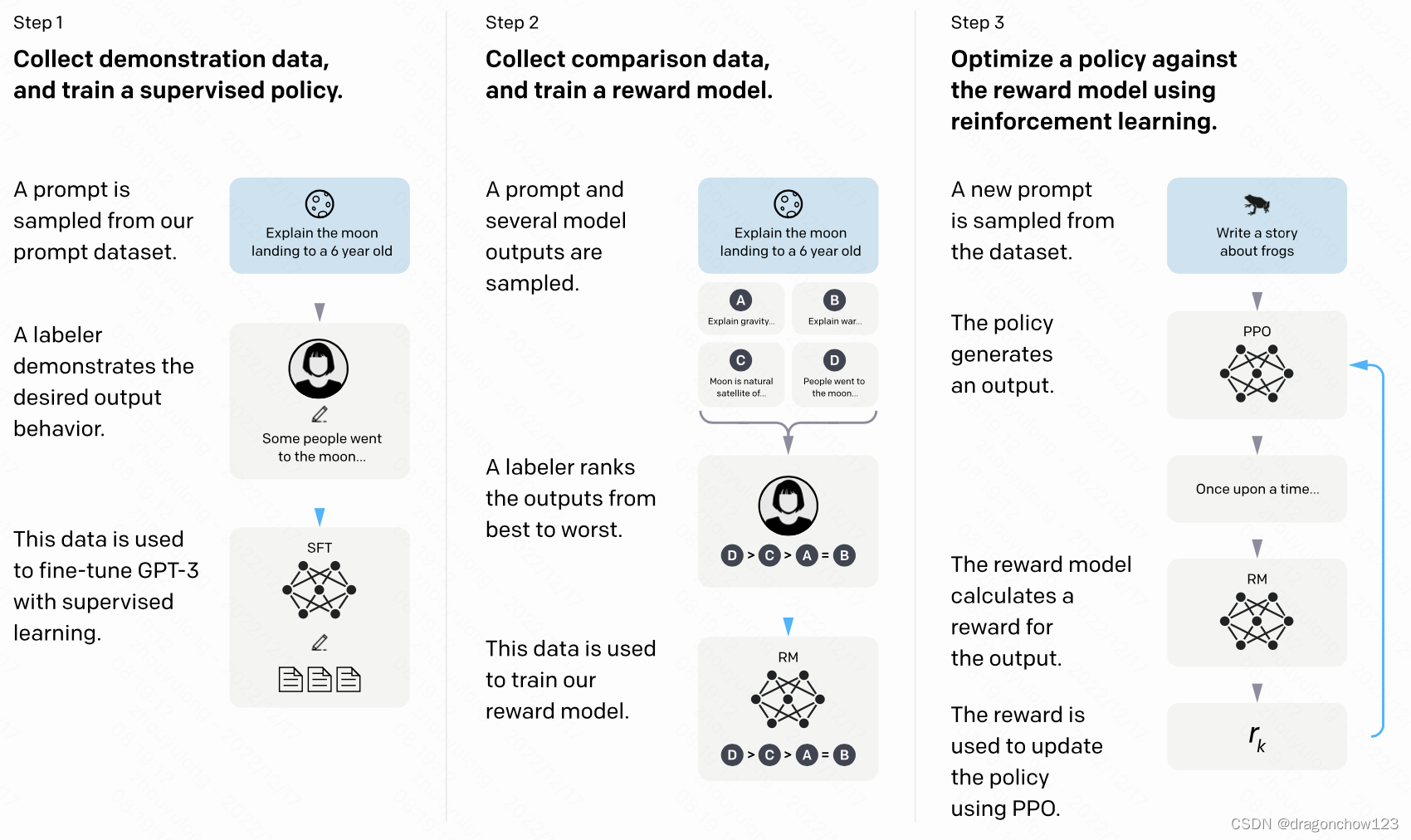
1,SFT
fine-tune GPT-3 on our labeler demonstrations
2,RM
Starting from the SFT model with the final unembedding layer removed, we trained a model to take in a prompt and response, and output a scalar reward
数据:人工排序K个样本,将K个样本两两比较:

3,RL

这个公式是啥, π \pi π是啥结构,都没讲清楚
这并不是创新的工作,抄的前面一篇Learning to summarize from human feedback
10,MMOE
MOE解决多任务的数据分布的问题
MMOE用合成数据说明了任务的相关性对模型也有影响

y k = h k ( ∑ i f i ( x ) g k ( x ) i ) , g k ( x ) = s o f t m a x ( W k x ) y_k=h_k(\sum_i f_i(x)g_k(x)_i), g_k(x)=softmax(W_k x) y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









